 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying and Enhancing the Efficiency of Large Language Model Based Search Agents
May 17, 2025Large Language Model (LLM)-based search agents have shown remarkable capabilities in solving complex tasks by dynamically decomposing problems and addressing them through interleaved reasoning and retrieval. However, this interleaved paradigm introduces substantial efficiency bottlenecks. First, we observe that both highly accurate and overly approximate retrieval methods degrade system efficiency: exact search incurs significant retrieval overhead, while coarse retrieval requires additional reasoning steps during generation. Second, we identify inefficiencies in system design, including improper scheduling and frequent retrieval stalls, which lead to cascading latency -- where even minor delays in retrieval amplify end-to-end inference time. To address these challenges, we introduce SearchAgent-X, a high-efficiency inference framework for LLM-based search agents. SearchAgent-X leverages high-recall approximate retrieval and incorporates two key techniques: priority-aware scheduling and non-stall retrieval. Extensive experiments demonstrate that SearchAgent-X consistently outperforms state-of-the-art systems such as vLLM and HNSW-based retrieval across diverse tasks, achieving up to 3.4$\times$ higher throughput and 5$\times$ lower latency, without compromising generation quality. SearchAgent-X is available at https://github.com/tiannuo-yang/SearchAgent-X.
UpDLRM: Accelerating Personalized Recommendation using Real-World PIM Architecture
Jun 20, 2024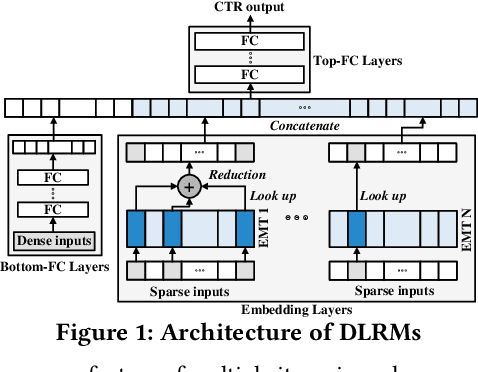

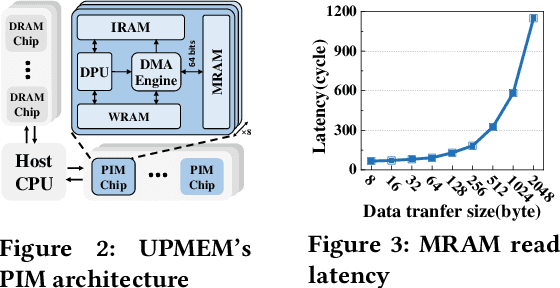
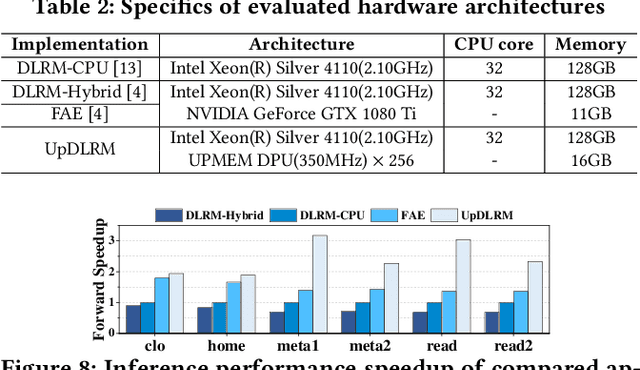
Deep Learning Recommendation Models (DLRMs) have gained popularity in recommendation systems due to their effectiveness in handling large-scale recommendation tasks. The embedding layers of DLRMs have become the performance bottleneck due to their intensive needs on memory capacity and memory bandwidth. In this paper, we propose UpDLRM, which utilizes real-world processingin-memory (PIM) hardware, UPMEM DPU, to boost the memory bandwidth and reduce recommendation latency. The parallel nature of the DPU memory can provide high aggregated bandwidth for the large number of irregular memory accesses in embedding lookups, thus offering great potential to reduce the inference latency. To fully utilize the DPU memory bandwidth, we further studied the embedding table partitioning problem to achieve good workload-balance and efficient data caching. Evaluations using real-world datasets show that, UpDLRM achieves much lower inference time for DLRM compared to both CPU-only and CPU-GPU hybrid counterparts.
VDTuner: Automated Performance Tuning for Vector Data Management Systems
Apr 16, 2024Vector data management systems (VDMSs) have become an indispensable cornerstone in large-scale information retrieval and machine learning systems like large language models. To enhance the efficiency and flexibility of similarity search, VDMS exposes many tunable index parameters and system parameters for users to specify. However, due to the inherent characteristics of VDMS, automatic performance tuning for VDMS faces several critical challenges, which cannot be well addressed by the existing auto-tuning methods. In this paper, we introduce VDTuner, a learning-based automatic performance tuning framework for VDMS, leveraging multi-objective Bayesian optimization. VDTuner overcomes the challenges associated with VDMS by efficiently exploring a complex multi-dimensional parameter space without requiring any prior knowledge. Moreover, it is able to achieve a good balance between search speed and recall rate, delivering an optimal configuration. Extensive evaluations demonstrate that VDTuner can markedly improve VDMS performance (14.12% in search speed and 186.38% in recall rate) compared with default setting, and is more efficient compared with state-of-the-art baselines (up to 3.57 times faster in terms of tuning time). In addition, VDTuner is scalable to specific user preference and cost-aware optimization objective. VDTuner is available online at https://github.com/tiannuo-yang/VDTuner.
DDistill-SR: Reparameterized Dynamic Distillation Network for Lightweight Image Super-Resolution
Dec 22, 2023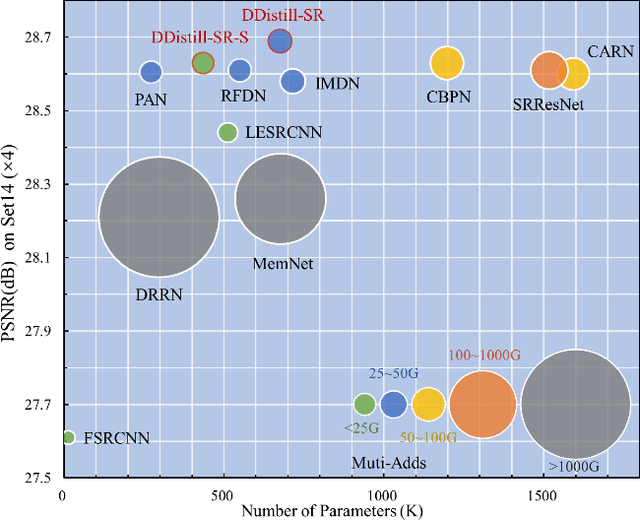
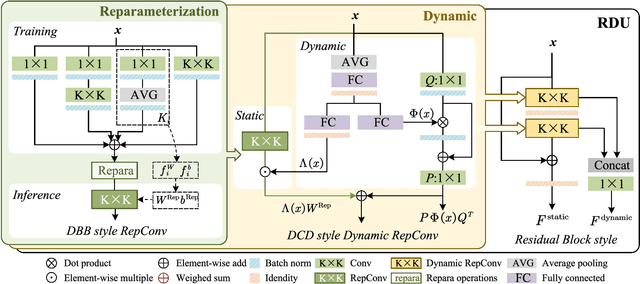
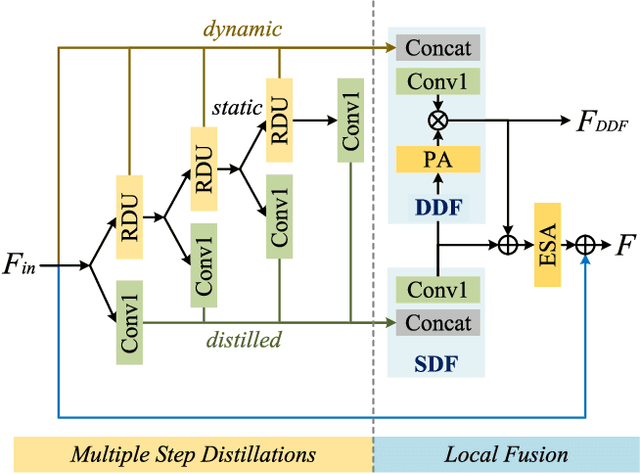
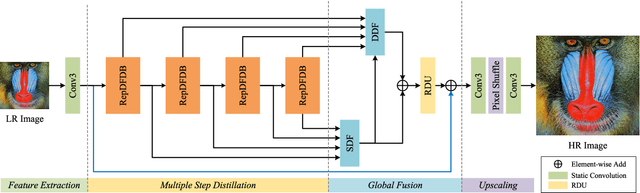
Recent research on deep convolutional neural networks (CNNs) has provided a significant performance boost on efficient super-resolution (SR) tasks by trading off the performance and applicability. However, most existing methods focus on subtracting feature processing consumption to reduce the parameters and calculations without refining the immediate features, which leads to inadequate information in the restoration. In this paper, we propose a lightweight network termed DDistill-SR, which significantly improves the SR quality by capturing and reusing more helpful information in a static-dynamic feature distillation manner. Specifically, we propose a plug-in reparameterized dynamic unit (RDU) to promote the performance and inference cost trade-off. During the training phase, the RDU learns to linearly combine multiple reparameterizable blocks by analyzing varied input statistics to enhance layer-level representation. In the inference phase, the RDU is equally converted to simple dynamic convolutions that explicitly capture robust dynamic and static feature maps. Then, the information distillation block is constructed by several RDUs to enforce hierarchical refinement and selective fusion of spatial context information. Furthermore, we propose a dynamic distillation fusion (DDF) module to enable dynamic signals aggregation and communication between hierarchical modules to further improve performance. Empirical results show that our DDistill-SR outperforms the baselines and achieves state-of-the-art results on most super-resolution domains with much fewer parameters and less computational overhead. We have released the code of DDistill-SR at https://github.com/icandle/DDistill-SR.
* Accepted by IEEE Transactions on Multimedia (TMM)
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Multi-scale Attention Network for Single Image Super-Resolution
Sep 29, 2022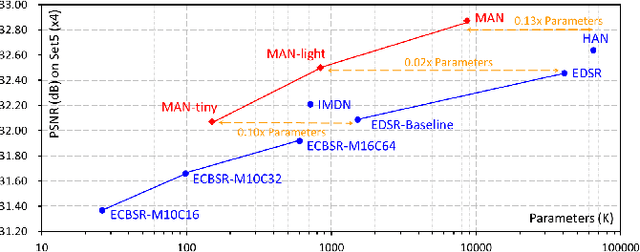
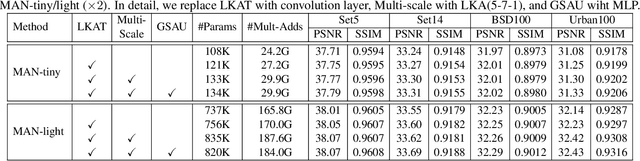

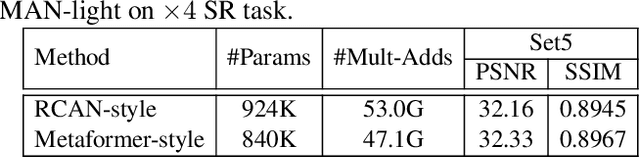
By exploiting large kernel decomposition and attention mechanisms, convolutional neural networks (CNN) can compete with transformer-based methods in many high-level computer vision tasks. However, due to the advantage of long-range modeling, the transformers with self-attention still dominate the low-level vision, including the super-resolution task. In this paper, we propose a CNN-based multi-scale attention network (MAN), which consists of multi-scale large kernel attention (MLKA) and a gated spatial attention unit (GSAU), to improve the performance of convolutional SR networks. Within our MLKA, we rectify LKA with multi-scale and gate schemes to obtain the abundant attention map at various granularity levels, therefore jointly aggregating global and local information and avoiding the potential blocking artifacts. In GSAU, we integrate gate mechanism and spatial attention to remove the unnecessary linear layer and aggregate informative spatial context. To confirm the effectiveness of our designs, we evaluate MAN with multiple complexities by simply stacking different numbers of MLKA and GSAU. Experimental results illustrate that our MAN can achieve varied trade-offs between state-of-the-art performance and computations. Code is available at https://github.com/icandle/MAN.