 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Zero-Overhead Freshness for Recommendation Systems via Inference-Side Model Updates
Dec 17, 2025Deep Learning Recommendation Models (DLRMs) underpin personalized services but face a critical freshness-accuracy tradeoff due to massive parameter synchronization overheads. Production DLRMs deploy decoupled training/inference clusters, where synchronizing petabyte-scale embedding tables (EMTs) causes multi-minute staleness, degrading recommendation quality and revenue. We observe that (1) inference nodes exhibit sustained CPU underutilization (peak <= 20%), and (2) EMT gradients possess intrinsic low-rank structure, enabling compact update representation. We present LiveUpdate, a system that eliminates inter-cluster synchronization by colocating Low-Rank Adaptation (LoRA) trainers within inference nodes. LiveUpdate addresses two core challenges: (1) dynamic rank adaptation via singular value monitoring to constrain memory overhead (<2% of EMTs), and (2) NUMA-aware resource scheduling with hardware-enforced QoS to eliminate update inference contention (P99 latency impact <20ms). Evaluations show LiveUpdate reduces update costs by 2x versus delta-update baselines while achieving higher accuracy within 1-hour windows. By transforming idle inference resources into freshness engines, LiveUpdate delivers online model updates while outperforming state-of-the-art delta-update methods by 0.04% to 0.24% in accuracy.
UpDLRM: Accelerating Personalized Recommendation using Real-World PIM Architecture
Jun 20, 2024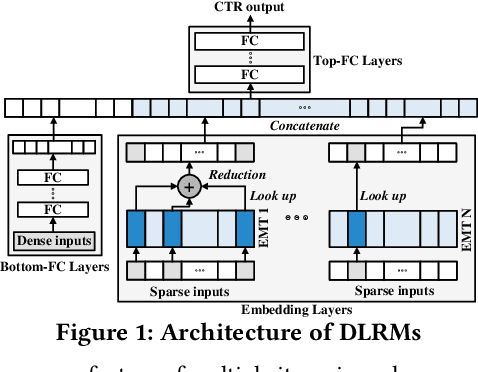

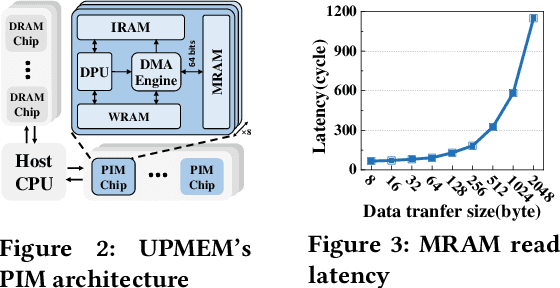
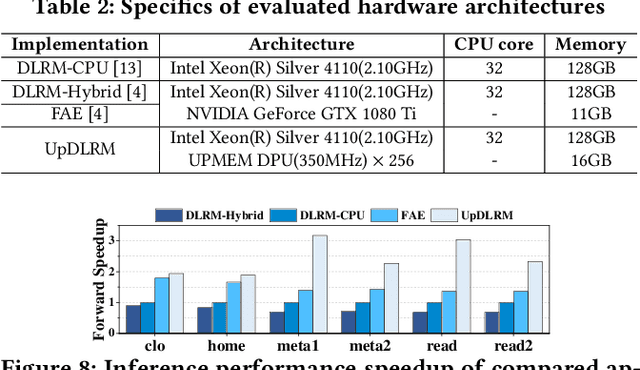
Deep Learning Recommendation Models (DLRMs) have gained popularity in recommendation systems due to their effectiveness in handling large-scale recommendation tasks. The embedding layers of DLRMs have become the performance bottleneck due to their intensive needs on memory capacity and memory bandwidth. In this paper, we propose UpDLRM, which utilizes real-world processingin-memory (PIM) hardware, UPMEM DPU, to boost the memory bandwidth and reduce recommendation latency. The parallel nature of the DPU memory can provide high aggregated bandwidth for the large number of irregular memory accesses in embedding lookups, thus offering great potential to reduce the inference latency. To fully utilize the DPU memory bandwidth, we further studied the embedding table partitioning problem to achieve good workload-balance and efficient data caching. Evaluations using real-world datasets show that, UpDLRM achieves much lower inference time for DLRM compared to both CPU-only and CPU-GPU hybrid counterparts.