 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Zero-Overhead Freshness for Recommendation Systems via Inference-Side Model Updates
Dec 17, 2025Deep Learning Recommendation Models (DLRMs) underpin personalized services but face a critical freshness-accuracy tradeoff due to massive parameter synchronization overheads. Production DLRMs deploy decoupled training/inference clusters, where synchronizing petabyte-scale embedding tables (EMTs) causes multi-minute staleness, degrading recommendation quality and revenue. We observe that (1) inference nodes exhibit sustained CPU underutilization (peak <= 20%), and (2) EMT gradients possess intrinsic low-rank structure, enabling compact update representation. We present LiveUpdate, a system that eliminates inter-cluster synchronization by colocating Low-Rank Adaptation (LoRA) trainers within inference nodes. LiveUpdate addresses two core challenges: (1) dynamic rank adaptation via singular value monitoring to constrain memory overhead (<2% of EMTs), and (2) NUMA-aware resource scheduling with hardware-enforced QoS to eliminate update inference contention (P99 latency impact <20ms). Evaluations show LiveUpdate reduces update costs by 2x versus delta-update baselines while achieving higher accuracy within 1-hour windows. By transforming idle inference resources into freshness engines, LiveUpdate delivers online model updates while outperforming state-of-the-art delta-update methods by 0.04% to 0.24% in accuracy.
FuseFL: One-Shot Federated Learning through the Lens of Causality with Progressive Model Fusion
Oct 27, 2024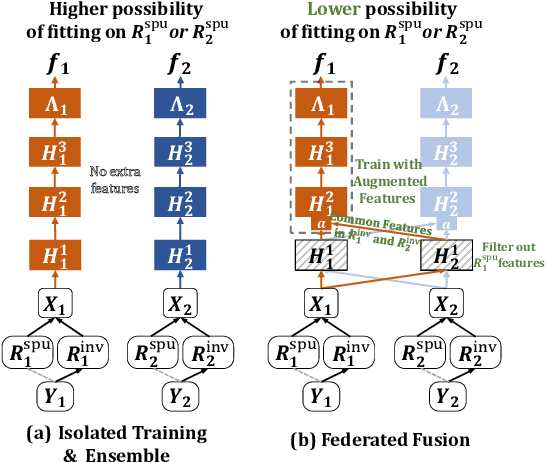
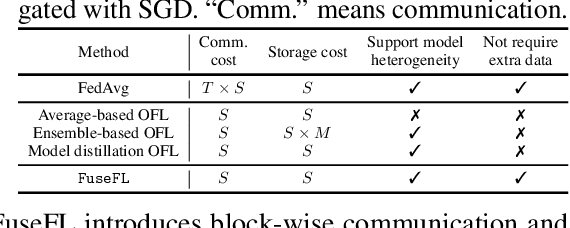
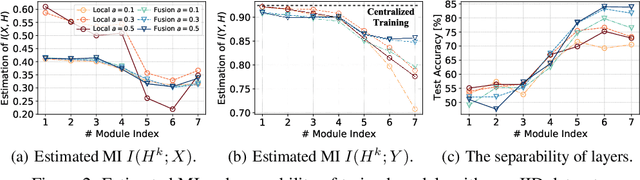
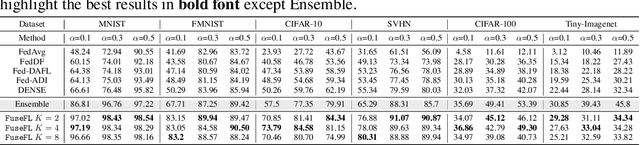
One-shot Federated Learning (OFL) significantly reduces communication costs in FL by aggregating trained models only once. However, the performance of advanced OFL methods is far behind the normal FL. In this work, we provide a causal view to find that this performance drop of OFL methods comes from the isolation problem, which means that local isolatedly trained models in OFL may easily fit to spurious correlations due to the data heterogeneity. From the causal perspective, we observe that the spurious fitting can be alleviated by augmenting intermediate features from other clients. Built upon our observation, we propose a novel learning approach to endow OFL with superb performance and low communication and storage costs, termed as FuseFL. Specifically, FuseFL decomposes neural networks into several blocks, and progressively trains and fuses each block following a bottom-up manner for feature augmentation, introducing no additional communication costs. Comprehensive experiments demonstrate that FuseFL outperforms existing OFL and ensemble FL by a significant margin. We conduct comprehensive experiments to show that FuseFL supports high scalability of clients, heterogeneous model training, and low memory costs. Our work is the first attempt using causality to analyze and alleviate data heterogeneity of OFL.
FusionLLM: A Decentralized LLM Training System on Geo-distributed GPUs with Adaptive Compression
Oct 16, 2024



To alleviate hardware scarcity in training large deep neural networks (DNNs), particularly large language models (LLMs), we present FusionLLM, a decentralized training system designed and implemented for training DNNs using geo-distributed GPUs across different computing clusters or individual devices. Decentralized training faces significant challenges regarding system design and efficiency, including: 1) the need for remote automatic differentiation (RAD), 2) support for flexible model definitions and heterogeneous software, 3) heterogeneous hardware leading to low resource utilization or the straggler problem, and 4) slow network communication. To address these challenges, in the system design, we represent the model as a directed acyclic graph of operators (OP-DAG). Each node in the DAG represents the operator in the DNNs, while the edge represents the data dependency between operators. Based on this design, 1) users are allowed to customize any DNN without caring low-level operator implementation; 2) we enable the task scheduling with the more fine-grained sub-tasks, offering more optimization space; 3) a DAG runtime executor can implement RAD withour requiring the consistent low-level ML framework versions. To enhance system efficiency, we implement a workload estimator and design an OP-Fence scheduler to cluster devices with similar bandwidths together and partition the DAG to increase throughput. Additionally, we propose an AdaTopK compressor to adaptively compress intermediate activations and gradients at the slowest communication links. To evaluate the convergence and efficiency of our system and algorithms, we train ResNet-101 and GPT-2 on three real-world testbeds using 48 GPUs connected with 8 Mbps~10 Gbps networks. Experimental results demonstrate that our system and method can achieve 1.45 - 9.39x speedup compared to baseline methods while ensuring convergence.
Bandwidth-Aware and Overlap-Weighted Compression for Communication-Efficient Federated Learning
Aug 27, 2024
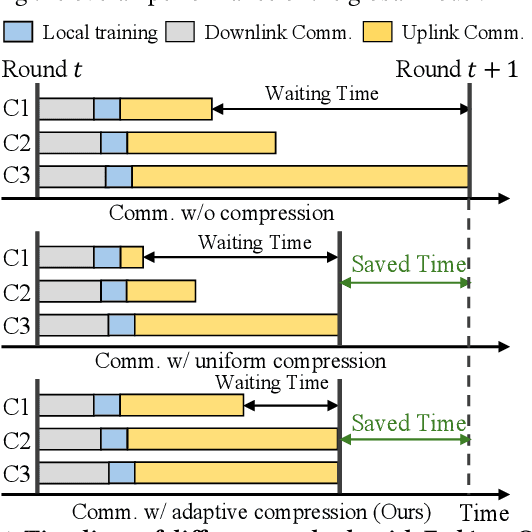

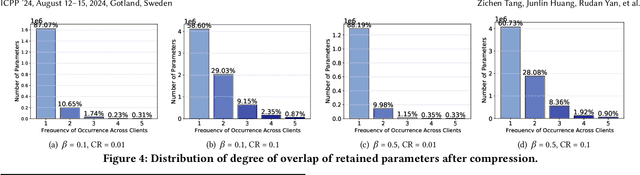
Current data compression methods, such as sparsification in Federated Averaging (FedAvg), effectively enhance the communication efficiency of Federated Learning (FL). However, these methods encounter challenges such as the straggler problem and diminished model performance due to heterogeneous bandwidth and non-IID (Independently and Identically Distributed) data. To address these issues, we introduce a bandwidth-aware compression framework for FL, aimed at improving communication efficiency while mitigating the problems associated with non-IID data. First, our strategy dynamically adjusts compression ratios according to bandwidth, enabling clients to upload their models at a close pace, thus exploiting the otherwise wasted time to transmit more data. Second, we identify the non-overlapped pattern of retained parameters after compression, which results in diminished client update signals due to uniformly averaged weights. Based on this finding, we propose a parameter mask to adjust the client-averaging coefficients at the parameter level, thereby more closely approximating the original updates, and improving the training convergence under heterogeneous environments. Our evaluations reveal that our method significantly boosts model accuracy, with a maximum improvement of 13% over the uncompressed FedAvg. Moreover, it achieves a $3.37\times$ speedup in reaching the target accuracy compared to FedAvg with a Top-K compressor, demonstrating its effectiveness in accelerating convergence with compression. The integration of common compression techniques into our framework further establishes its potential as a versatile foundation for future cross-device, communication-efficient FL research, addressing critical challenges in FL and advancing the field of distributed machine learning.
UpDLRM: Accelerating Personalized Recommendation using Real-World PIM Architecture
Jun 20, 2024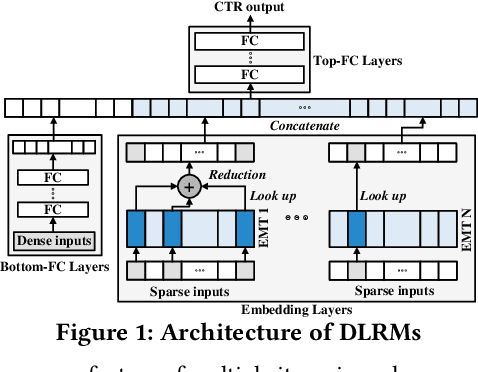

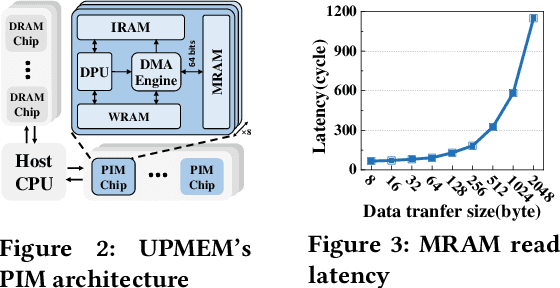
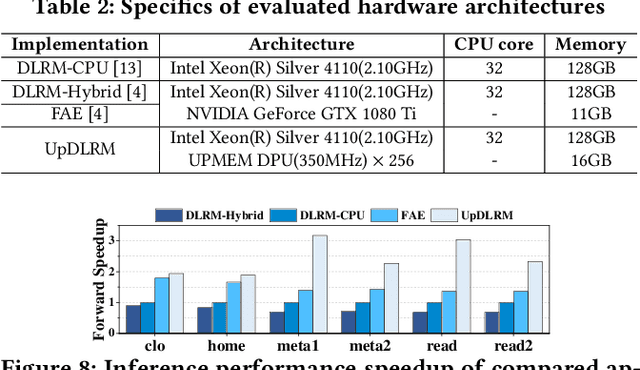
Deep Learning Recommendation Models (DLRMs) have gained popularity in recommendation systems due to their effectiveness in handling large-scale recommendation tasks. The embedding layers of DLRMs have become the performance bottleneck due to their intensive needs on memory capacity and memory bandwidth. In this paper, we propose UpDLRM, which utilizes real-world processingin-memory (PIM) hardware, UPMEM DPU, to boost the memory bandwidth and reduce recommendation latency. The parallel nature of the DPU memory can provide high aggregated bandwidth for the large number of irregular memory accesses in embedding lookups, thus offering great potential to reduce the inference latency. To fully utilize the DPU memory bandwidth, we further studied the embedding table partitioning problem to achieve good workload-balance and efficient data caching. Evaluations using real-world datasets show that, UpDLRM achieves much lower inference time for DLRM compared to both CPU-only and CPU-GPU hybrid counterparts.