 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
HALoS: Hierarchical Asynchronous Local SGD over Slow Networks for Geo-Distributed Large Language Model Training
Jun 05, 2025Training large language models (LLMs) increasingly relies on geographically distributed accelerators, causing prohibitive communication costs across regions and uneven utilization of heterogeneous hardware. We propose HALoS, a hierarchical asynchronous optimization framework that tackles these issues by introducing local parameter servers (LPSs) within each region and a global parameter server (GPS) that merges updates across regions. This hierarchical design minimizes expensive inter-region communication, reduces straggler effects, and leverages fast intra-region links. We provide a rigorous convergence analysis for HALoS under non-convex objectives, including theoretical guarantees on the role of hierarchical momentum in asynchronous training. Empirically, HALoS attains up to 7.5x faster convergence than synchronous baselines in geo-distributed LLM training and improves upon existing asynchronous methods by up to 2.1x. Crucially, HALoS preserves the model quality of fully synchronous SGD-matching or exceeding accuracy on standard language modeling and downstream benchmarks-while substantially lowering total training time. These results demonstrate that hierarchical, server-side update accumulation and global model merging are powerful tools for scalable, efficient training of new-era LLMs in heterogeneous, geo-distributed environments.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Accelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
Jul 05, 2024DLRM is a state-of-the-art recommendation system model that has gained widespread adoption across various industry applications. The large size of DLRM models, however, necessitates the use of multiple devices/GPUs for efficient training. A significant bottleneck in this process is the time-consuming all-to-all communication required to collect embedding data from all devices. To mitigate this, we introduce a method that employs error-bounded lossy compression to reduce the communication data size and accelerate DLRM training. We develop a novel error-bounded lossy compression algorithm, informed by an in-depth analysis of embedding data features, to achieve high compression ratios. Moreover, we introduce a dual-level adaptive strategy for error-bound adjustment, spanning both table-wise and iteration-wise aspects, to balance the compression benefits with the potential impacts on accuracy. We further optimize our compressor for PyTorch tensors on GPUs, minimizing compression overhead. Evaluation shows that our method achieves a 1.38$\times$ training speedup with a minimal accuracy impact.
UpDLRM: Accelerating Personalized Recommendation using Real-World PIM Architecture
Jun 20, 2024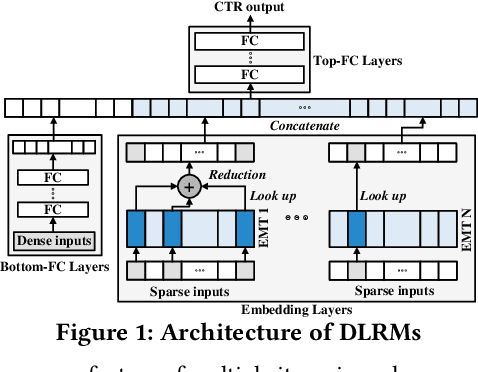

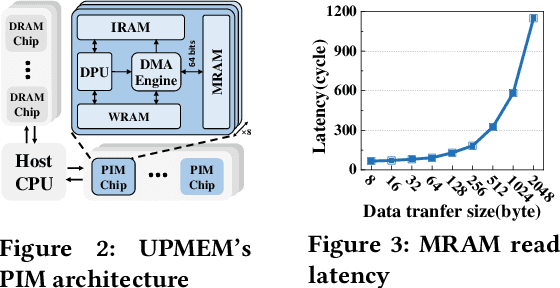
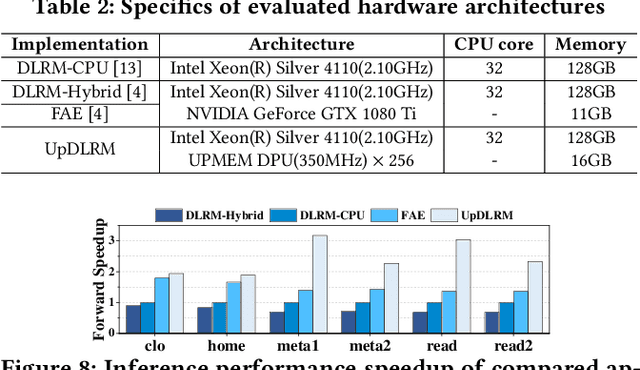
Deep Learning Recommendation Models (DLRMs) have gained popularity in recommendation systems due to their effectiveness in handling large-scale recommendation tasks. The embedding layers of DLRMs have become the performance bottleneck due to their intensive needs on memory capacity and memory bandwidth. In this paper, we propose UpDLRM, which utilizes real-world processingin-memory (PIM) hardware, UPMEM DPU, to boost the memory bandwidth and reduce recommendation latency. The parallel nature of the DPU memory can provide high aggregated bandwidth for the large number of irregular memory accesses in embedding lookups, thus offering great potential to reduce the inference latency. To fully utilize the DPU memory bandwidth, we further studied the embedding table partitioning problem to achieve good workload-balance and efficient data caching. Evaluations using real-world datasets show that, UpDLRM achieves much lower inference time for DLRM compared to both CPU-only and CPU-GPU hybrid counterparts.