 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALoS: Hierarchical Asynchronous Local SGD over Slow Networks for Geo-Distributed Large Language Model Training
Jun 05, 2025Training large language models (LLMs) increasingly relies on geographically distributed accelerators, causing prohibitive communication costs across regions and uneven utilization of heterogeneous hardware. We propose HALoS, a hierarchical asynchronous optimization framework that tackles these issues by introducing local parameter servers (LPSs) within each region and a global parameter server (GPS) that merges updates across regions. This hierarchical design minimizes expensive inter-region communication, reduces straggler effects, and leverages fast intra-region links. We provide a rigorous convergence analysis for HALoS under non-convex objectives, including theoretical guarantees on the role of hierarchical momentum in asynchronous training. Empirically, HALoS attains up to 7.5x faster convergence than synchronous baselines in geo-distributed LLM training and improves upon existing asynchronous methods by up to 2.1x. Crucially, HALoS preserves the model quality of fully synchronous SGD-matching or exceeding accuracy on standard language modeling and downstream benchmarks-while substantially lowering total training time. These results demonstrate that hierarchical, server-side update accumulation and global model merging are powerful tools for scalable, efficient training of new-era LLMs in heterogeneous, geo-distributed environments.
OMEGA: A Low-Latency GNN Serving System for Large Graphs
Jan 15, 2025



Graph Neural Networks (GNNs) have been widely adopted for their ability to compute expressive node representations in graph datasets. However, serving GNNs on large graphs is challenging due to the high communication, computation, and memory overheads of constructing and executing computation graphs, which represent information flow across large neighborhoods. Existing approximation techniques in training can mitigate the overheads but, in serving, still lead to high latency and/or accuracy loss. To this end, we propose OMEGA, a system that enables low-latency GNN serving for large graphs with minimal accuracy loss through two key ideas. First, OMEGA employs selective recomputation of precomputed embeddings, which allows for reusing precomputed computation subgraphs while selectively recomputing a small fraction to minimize accuracy loss. Second, we develop computation graph parallelism, which reduces communication overhead by parallelizing the creation and execution of computation graphs across machines. Our evaluation with large graph datasets and GNN models shows that OMEGA significantly outperforms state-of-the-art techniques.
Read-ME: Refactorizing LLMs as Router-Decoupled Mixture of Experts with System Co-Design
Oct 24, 2024



The proliferation of large language models (LLMs) has led to the adoption of Mixture-of-Experts (MoE) architectures that dynamically leverage specialized subnetworks for improved efficiency and performance. Despite their benefits, MoE models face significant challenges during inference, including inefficient memory management and suboptimal batching, due to misaligned design choices between the model architecture and the system policies. Furthermore, the conventional approach of training MoEs from scratch is increasingly prohibitive in terms of cost. In this paper, we propose a novel framework Read-ME that transforms pre-trained dense LLMs into smaller MoE models (in contrast to "upcycling" generalist MoEs), avoiding the high costs of ground-up training. Our approach employs activation sparsity to extract experts. To compose experts, we examine the widely-adopted layer-wise router design and show its redundancy, and thus we introduce the pre-gating router decoupled from the MoE backbone that facilitates system-friendly pre-computing and lookahead scheduling, enhancing expert-aware batching and caching. Our codesign therefore addresses critical gaps on both the algorithmic and system fronts, establishing a scalable and efficient alternative for LLM inference in resource-constrained settings. Read-ME outperforms other popular open-source dense models of similar scales, achieving improvements of up to 10.1% on MMLU, and improving mean end-to-end latency up to 6.1%. Codes are available at: https://github.com/VITA-Group/READ-ME.
Terra: Imperative-Symbolic Co-Execution of Imperative Deep Learning Programs
Jan 23, 2022

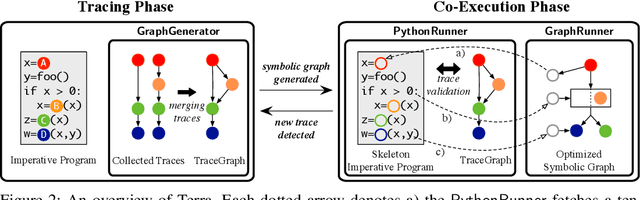
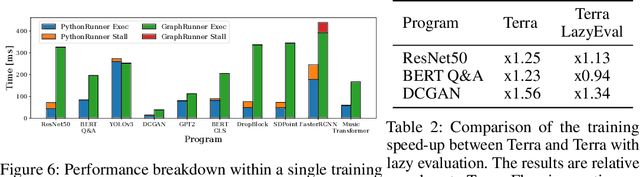
Imperative programming allows users to implement their deep neural networks (DNNs) easily and has become an essential part of recent deep learning (DL) frameworks. Recently, several systems have been proposed to combine the usability of imperative programming with the optimized performance of symbolic graph execution. Such systems convert imperative Python DL programs to optimized symbolic graphs and execute them. However, they cannot fully support the usability of imperative programming. For example, if an imperative DL program contains a Python feature with no corresponding symbolic representation (e.g., third-party library calls or unsupported dynamic control flows) they fail to execute the program. To overcome this limitation, we propose Terra, an imperative-symbolic co-execution system that can handle any imperative DL programs while achieving the optimized performance of symbolic graph execution. To achieve this, Terra builds a symbolic graph by decoupling DL operations from Python features. Then, Terra conducts the imperative execution to support all Python features, while delegating the decoupled operations to the symbolic execution. We evaluated the performance improvement and coverage of Terra with ten imperative DL programs for several DNN architectures. The results show that Terra can speed up the execution of all ten imperative DL programs, whereas AutoGraph, one of the state-of-the-art systems, fails to execute five of them.