 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-Fly Adaptive Distillation of Transformer to Dual-State Linear Attention
Jun 12, 2025Large language models (LLMs) excel at capturing global token dependencies via self-attention but face prohibitive compute and memory costs on lengthy inputs. While sub-quadratic methods (e.g., linear attention) can reduce these costs, they often degrade accuracy due to overemphasizing recent tokens. In this work, we first propose dual-state linear attention (DSLA), a novel design that maintains two specialized hidden states-one for preserving historical context and one for tracking recency-thereby mitigating the short-range bias typical of linear-attention architectures. To further balance efficiency and accuracy under dynamic workload conditions, we introduce DSLA-Serve, an online adaptive distillation framework that progressively replaces Transformer layers with DSLA layers at inference time, guided by a sensitivity-based layer ordering. DSLA-Serve uses a chained fine-tuning strategy to ensure that each newly converted DSLA layer remains consistent with previously replaced layers, preserving the overall quality. Extensive evaluations on commonsense reasoning, long-context QA, and text summarization demonstrate that DSLA-Serve yields 2.3x faster inference than Llama2-7B and 3.0x faster than the hybrid Zamba-7B, while retaining comparable performance across downstream tasks. Our ablation studies show that DSLA's dual states capture both global and local dependencies, addressing the historical-token underrepresentation seen in prior linear attentions. Codes are available at https://github.com/utnslab/DSLA-Serve.
Read-ME: Refactorizing LLMs as Router-Decoupled Mixture of Experts with System Co-Design
Oct 24, 2024



The proliferation of large language models (LLMs) has led to the adoption of Mixture-of-Experts (MoE) architectures that dynamically leverage specialized subnetworks for improved efficiency and performance. Despite their benefits, MoE models face significant challenges during inference, including inefficient memory management and suboptimal batching, due to misaligned design choices between the model architecture and the system policies. Furthermore, the conventional approach of training MoEs from scratch is increasingly prohibitive in terms of cost. In this paper, we propose a novel framework Read-ME that transforms pre-trained dense LLMs into smaller MoE models (in contrast to "upcycling" generalist MoEs), avoiding the high costs of ground-up training. Our approach employs activation sparsity to extract experts. To compose experts, we examine the widely-adopted layer-wise router design and show its redundancy, and thus we introduce the pre-gating router decoupled from the MoE backbone that facilitates system-friendly pre-computing and lookahead scheduling, enhancing expert-aware batching and caching. Our codesign therefore addresses critical gaps on both the algorithmic and system fronts, establishing a scalable and efficient alternative for LLM inference in resource-constrained settings. Read-ME outperforms other popular open-source dense models of similar scales, achieving improvements of up to 10.1% on MMLU, and improving mean end-to-end latency up to 6.1%. Codes are available at: https://github.com/VITA-Group/READ-ME.
FFN-SkipLLM: A Hidden Gem for Autoregressive Decoding with Adaptive Feed Forward Skipping
Apr 05, 2024Autoregressive Large Language Models (e.g., LLaMa, GPTs) are omnipresent achieving remarkable success in language understanding and generation. However, such impressive capability typically comes with a substantial model size, which presents significant challenges for autoregressive token-by-token generation. To mitigate computation overload incurred during generation, several early-exit and layer-dropping strategies have been proposed. Despite some promising success due to the redundancy across LLMs layers on metrics like Rough-L/BLUE, our careful knowledge-intensive evaluation unveils issues such as generation collapse, hallucination of wrong facts, and noticeable performance drop even at the trivial exit ratio of 10-15% of layers. We attribute these errors primarily to ineffective handling of the KV cache through state copying during early-exit. In this work, we observed the saturation of computationally expensive feed-forward blocks of LLM layers and proposed FFN-SkipLLM, which is a novel fine-grained skip strategy of autoregressive LLMs. More specifically, FFN-SkipLLM is an input-adaptive feed-forward skipping strategy that can skip 25-30% of FFN blocks of LLMs with marginal change in performance on knowledge-intensive generation tasks without any requirement to handle KV cache. Our extensive experiments and ablation across benchmarks like MT-Bench, Factoid-QA, and variable-length text summarization illustrate how our simple and ease-at-use method can facilitate faster autoregressive decoding.
Sequential Encryption of Sparse Neural Networks Toward Optimum Representation of Irregular Sparsity
May 05, 2021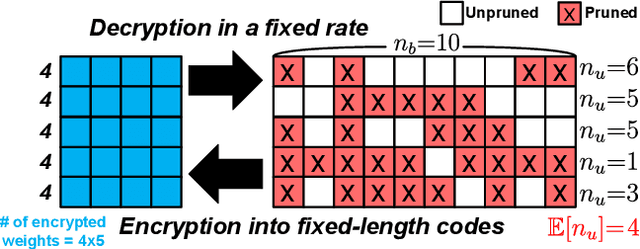
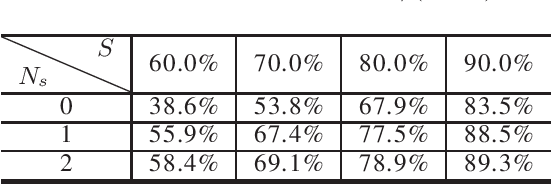
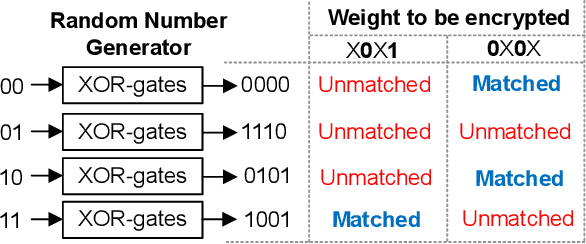
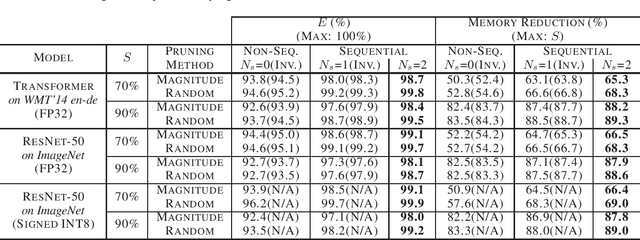
Even though fine-grained pruning techniques achieve a high compression ratio, conventional sparsity representations (such as CSR) associated with irregular sparsity degrade parallelism significantly. Practical pruning methods, thus, usually lower pruning rates (by structured pruning) to improve parallelism. In this paper, we study fixed-to-fixed (lossless) encryption architecture/algorithm to support fine-grained pruning methods such that sparse neural networks can be stored in a highly regular structure. We first estimate the maximum compression ratio of encryption-based compression using entropy. Then, as an effort to push the compression ratio to the theoretical maximum (by entropy), we propose a sequential fixed-to-fixed encryption scheme. We demonstrate that our proposed compression scheme achieves almost the maximum compression ratio for the Transformer and ResNet-50 pruned by various fine-grained pruning methods.
Q-Rater: Non-Convex Optimization for Post-Training Uniform Quantization
May 05, 2021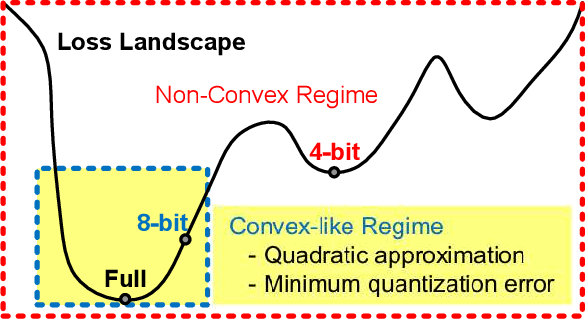
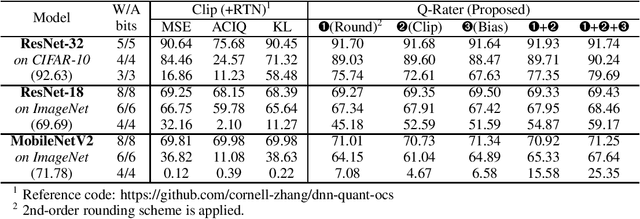
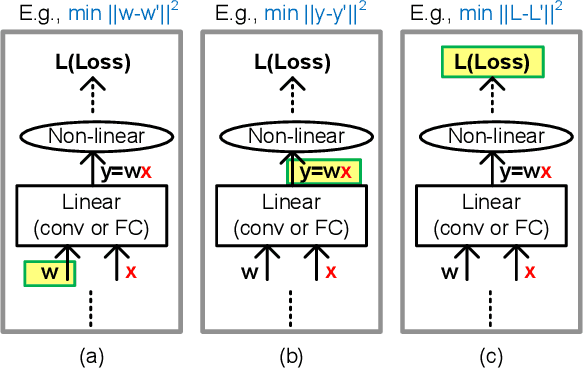
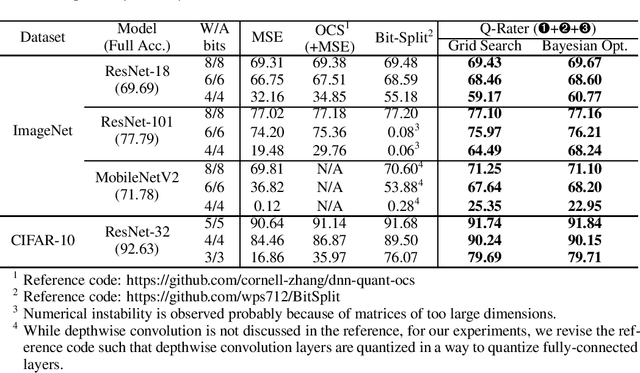
Various post-training uniform quantization methods have usually been studied based on convex optimization. As a result, most previous ones rely on the quantization error minimization and/or quadratic approximations. Such approaches are computationally efficient and reasonable when a large number of quantization bits are employed. When the number of quantization bits is relatively low, however, non-convex optimization is unavoidable to improve model accuracy. In this paper, we propose a new post-training uniform quantization technique considering non-convexity. We empirically show that hyper-parameters for clipping and rounding of weights and activations can be explored by monitoring task loss. Then, an optimally searched set of hyper-parameters is frozen to proceed to the next layer such that an incremental non-convex optimization is enabled for post-training quantization. Throughout extensive experimental results using various models, our proposed technique presents higher model accuracy, especially for a low-bit quantization.