 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
FFN-SkipLLM: A Hidden Gem for Autoregressive Decoding with Adaptive Feed Forward Skipping
Apr 05, 2024Autoregressive Large Language Models (e.g., LLaMa, GPTs) are omnipresent achieving remarkable success in language understanding and generation. However, such impressive capability typically comes with a substantial model size, which presents significant challenges for autoregressive token-by-token generation. To mitigate computation overload incurred during generation, several early-exit and layer-dropping strategies have been proposed. Despite some promising success due to the redundancy across LLMs layers on metrics like Rough-L/BLUE, our careful knowledge-intensive evaluation unveils issues such as generation collapse, hallucination of wrong facts, and noticeable performance drop even at the trivial exit ratio of 10-15% of layers. We attribute these errors primarily to ineffective handling of the KV cache through state copying during early-exit. In this work, we observed the saturation of computationally expensive feed-forward blocks of LLM layers and proposed FFN-SkipLLM, which is a novel fine-grained skip strategy of autoregressive LLMs. More specifically, FFN-SkipLLM is an input-adaptive feed-forward skipping strategy that can skip 25-30% of FFN blocks of LLMs with marginal change in performance on knowledge-intensive generation tasks without any requirement to handle KV cache. Our extensive experiments and ablation across benchmarks like MT-Bench, Factoid-QA, and variable-length text summarization illustrate how our simple and ease-at-use method can facilitate faster autoregressive decoding.
MOSEL: Inference Serving Using Dynamic Modality Selection
Oct 27, 2023Rapid advancements over the years have helped machine learning models reach previously hard-to-achieve goals, sometimes even exceeding human capabilities. However, to attain the desired accuracy, the model sizes and in turn their computational requirements have increased drastically. Thus, serving predictions from these models to meet any target latency and cost requirements of applications remains a key challenge, despite recent work in building inference-serving systems as well as algorithmic approaches that dynamically adapt models based on inputs. In this paper, we introduce a form of dynamism, modality selection, where we adaptively choose modalities from inference inputs while maintaining the model quality. We introduce MOSEL, an automated inference serving system for multi-modal ML models that carefully picks input modalities per request based on user-defined performance and accuracy requirements. MOSEL exploits modality configurations extensively, improving system throughput by 3.6$\times$ with an accuracy guarantee and shortening job completion times by 11$\times$.
Mirovia: A Benchmarking Suite for Modern Heterogeneous Computing
Jun 25, 2019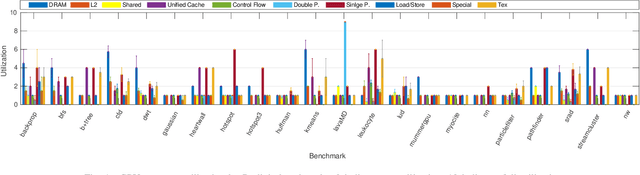

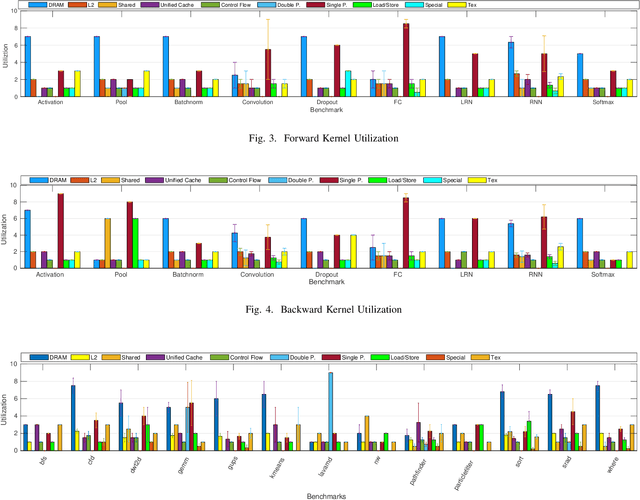

This paper presents Mirovia, a benchmark suite developed for modern day heterogeneous computing. Previous benchmark suites such as Rodinia and SHOC are well written and have many desirable features. However, these tools were developed years ago when hardware was less powerful and software had fewer features. For example, unified memory was introduced in CUDA 6 as a new programming model and wasn't available when Rodinia was released. Meanwhile, the increasing demand for graphics processing units (GPUs) due to the recent rise in popularity of deep neural networks (DNNs) has opened doors for many new research problems. It is essential to consider DNNs as first-class citizens in a comprehensive benchmark suite. However, the main focus is usually limited to inference and model performance evaluation, which is not desirable for hardware architects studying for emerging platforms. Drawing inspiration from Rodinia and SHOC, Mirovia is a benchmark suite that is designed to take advantage of modern GPU architectures, while also representing a diverse set of application domains. By adopting applications from Rodinia and SHOC, and including newly written applications with special focus on DNNs, Mirovia better characterizes modern heterogeneous systems.