 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatAD: Reasoning-Enhanced Time-Series Anomaly Detection with Multi-Turn Instruction Evolution
Jan 20, 2026LLM-driven Anomaly Detection (AD) helps enhance the understanding and explanatory abilities of anomalous behaviors in Time Series (TS). Existing methods face challenges of inadequate reasoning ability, deficient multi-turn dialogue capability, and narrow generalization. To this end, we 1) propose a multi-agent-based TS Evolution algorithm named TSEvol. On top of it, we 2) introduce the AD reasoning and multi-turn dialogue Dataset TSEData-20K and contribute the Chatbot family for AD, including ChatAD-Llama3-8B, Qwen2.5-7B, and Mistral-7B. Furthermore, 3) we propose the TS Kahneman-Tversky Optimization (TKTO) to enhance ChatAD's cross-task generalization capability. Lastly, 4) we propose a LLM-driven Learning-based AD Benchmark LLADBench to evaluate the performance of ChatAD and nine baselines across seven datasets and tasks. Our three ChatAD models achieve substantial gains, up to 34.50% in accuracy, 34.71% in F1, and a 37.42% reduction in false positives. Besides, via KTKO, our optimized ChatAD achieves competitive performance in reasoning and cross-task generalization on classification, forecasting, and imputation.
Demystifying and Enhancing the Efficiency of Large Language Model Based Search Agents
May 17, 2025Large Language Model (LLM)-based search agents have shown remarkable capabilities in solving complex tasks by dynamically decomposing problems and addressing them through interleaved reasoning and retrieval. However, this interleaved paradigm introduces substantial efficiency bottlenecks. First, we observe that both highly accurate and overly approximate retrieval methods degrade system efficiency: exact search incurs significant retrieval overhead, while coarse retrieval requires additional reasoning steps during generation. Second, we identify inefficiencies in system design, including improper scheduling and frequent retrieval stalls, which lead to cascading latency -- where even minor delays in retrieval amplify end-to-end inference time. To address these challenges, we introduce SearchAgent-X, a high-efficiency inference framework for LLM-based search agents. SearchAgent-X leverages high-recall approximate retrieval and incorporates two key techniques: priority-aware scheduling and non-stall retrieval. Extensive experiments demonstrate that SearchAgent-X consistently outperforms state-of-the-art systems such as vLLM and HNSW-based retrieval across diverse tasks, achieving up to 3.4$\times$ higher throughput and 5$\times$ lower latency, without compromising generation quality. SearchAgent-X is available at https://github.com/tiannuo-yang/SearchAgent-X.
Federated Model Heterogeneous Matryoshka Representation Learning
Jun 01, 2024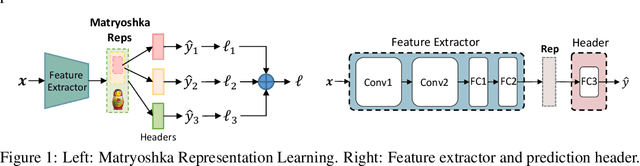



Model heterogeneous federated learning (MHeteroFL) enables FL clients to collaboratively train models with heterogeneous structures in a distributed fashion. However, existing MHeteroFL methods rely on training loss to transfer knowledge between the client model and the server model, resulting in limited knowledge exchange. To address this limitation, we propose the Federated model heterogeneous Matryoshka Representation Learning (FedMRL) approach for supervised learning tasks. It adds an auxiliary small homogeneous model shared by clients with heterogeneous local models. (1) The generalized and personalized representations extracted by the two models' feature extractors are fused by a personalized lightweight representation projector. This step enables representation fusion to adapt to local data distribution. (2) The fused representation is then used to construct Matryoshka representations with multi-dimensional and multi-granular embedded representations learned by the global homogeneous model header and the local heterogeneous model header. This step facilitates multi-perspective representation learning and improves model learning capability. Theoretical analysis shows that FedMRL achieves a $O(1/T)$ non-convex convergence rate. Extensive experiments on benchmark datasets demonstrate its superior model accuracy with low communication and computational costs compared to seven state-of-the-art baselines. It achieves up to 8.48% and 24.94% accuracy improvement compared with the state-of-the-art and the best same-category baseline, respectively.
pFedAFM: Adaptive Feature Mixture for Batch-Level Personalization in Heterogeneous Federated Learning
Apr 27, 2024



Model-heterogeneous personalized federated learning (MHPFL) enables FL clients to train structurally different personalized models on non-independent and identically distributed (non-IID) local data. Existing MHPFL methods focus on achieving client-level personalization, but cannot address batch-level data heterogeneity. To bridge this important gap, we propose a model-heterogeneous personalized Federated learning approach with Adaptive Feature Mixture (pFedAFM) for supervised learning tasks. It consists of three novel designs: 1) A sharing global homogeneous small feature extractor is assigned alongside each client's local heterogeneous model (consisting of a heterogeneous feature extractor and a prediction header) to facilitate cross-client knowledge fusion. The two feature extractors share the local heterogeneous model's prediction header containing rich personalized prediction knowledge to retain personalized prediction capabilities. 2) An iterative training strategy is designed to alternately train the global homogeneous small feature extractor and the local heterogeneous large model for effective global-local knowledge exchange. 3) A trainable weight vector is designed to dynamically mix the features extracted by both feature extractors to adapt to batch-level data heterogeneity. Theoretical analysis proves that pFedAFM can converge over time. Extensive experiments on 2 benchmark datasets demonstrate that it significantly outperforms 7 state-of-the-art MHPFL methods, achieving up to 7.93% accuracy improvement while incurring low communication and computation costs.
VDTuner: Automated Performance Tuning for Vector Data Management Systems
Apr 16, 2024Vector data management systems (VDMSs) have become an indispensable cornerstone in large-scale information retrieval and machine learning systems like large language models. To enhance the efficiency and flexibility of similarity search, VDMS exposes many tunable index parameters and system parameters for users to specify. However, due to the inherent characteristics of VDMS, automatic performance tuning for VDMS faces several critical challenges, which cannot be well addressed by the existing auto-tuning methods. In this paper, we introduce VDTuner, a learning-based automatic performance tuning framework for VDMS, leveraging multi-objective Bayesian optimization. VDTuner overcomes the challenges associated with VDMS by efficiently exploring a complex multi-dimensional parameter space without requiring any prior knowledge. Moreover, it is able to achieve a good balance between search speed and recall rate, delivering an optimal configuration. Extensive evaluations demonstrate that VDTuner can markedly improve VDMS performance (14.12% in search speed and 186.38% in recall rate) compared with default setting, and is more efficient compared with state-of-the-art baselines (up to 3.57 times faster in terms of tuning time). In addition, VDTuner is scalable to specific user preference and cost-aware optimization objective. VDTuner is available online at https://github.com/tiannuo-yang/VDTuner.
pFedMoE: Data-Level Personalization with Mixture of Experts for Model-Heterogeneous Personalized Federated Learning
Feb 11, 2024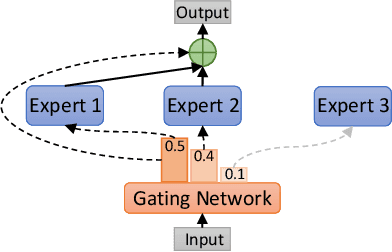



Federated learning (FL) has been widely adopted for collaborative training on decentralized data. However, it faces the challenges of data, system, and model heterogeneity. This has inspired the emergence of model-heterogeneous personalized federated learning (MHPFL). Nevertheless, the problem of ensuring data and model privacy, while achieving good model performance and keeping communication and computation costs low remains open in MHPFL. To address this problem, we propose a model-heterogeneous personalized Federated learning with Mixture of Experts (pFedMoE) method. It assigns a shared homogeneous small feature extractor and a local gating network for each client's local heterogeneous large model. Firstly, during local training, the local heterogeneous model's feature extractor acts as a local expert for personalized feature (representation) extraction, while the shared homogeneous small feature extractor serves as a global expert for generalized feature extraction. The local gating network produces personalized weights for extracted representations from both experts on each data sample. The three models form a local heterogeneous MoE. The weighted mixed representation fuses generalized and personalized features and is processed by the local heterogeneous large model's header with personalized prediction information. The MoE and prediction header are updated simultaneously. Secondly, the trained local homogeneous small feature extractors are sent to the server for cross-client information fusion via aggregation. Overall, pFedMoE enhances local model personalization at a fine-grained data level, while supporting model heterogeneity.
DDistill-SR: Reparameterized Dynamic Distillation Network for Lightweight Image Super-Resolution
Dec 22, 2023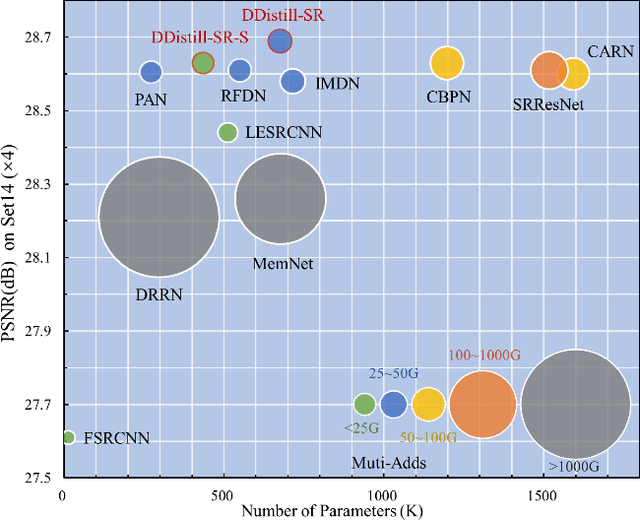
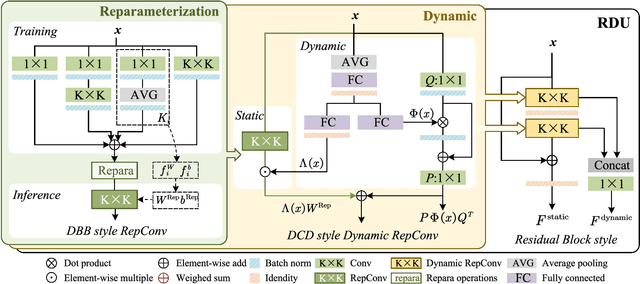
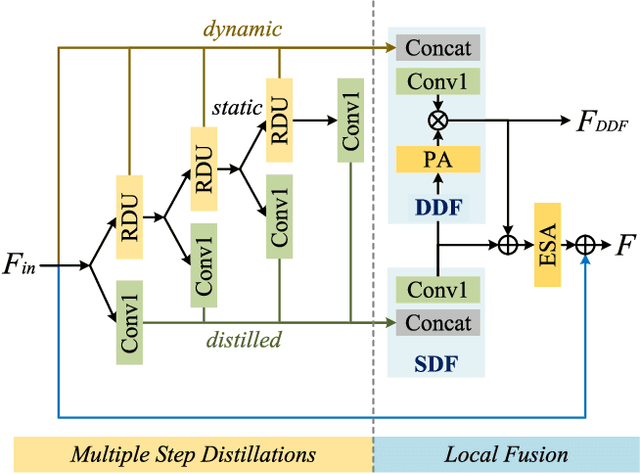
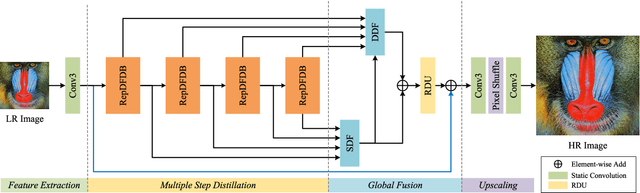
Recent research on deep convolutional neural networks (CNNs) has provided a significant performance boost on efficient super-resolution (SR) tasks by trading off the performance and applicability. However, most existing methods focus on subtracting feature processing consumption to reduce the parameters and calculations without refining the immediate features, which leads to inadequate information in the restoration. In this paper, we propose a lightweight network termed DDistill-SR, which significantly improves the SR quality by capturing and reusing more helpful information in a static-dynamic feature distillation manner. Specifically, we propose a plug-in reparameterized dynamic unit (RDU) to promote the performance and inference cost trade-off. During the training phase, the RDU learns to linearly combine multiple reparameterizable blocks by analyzing varied input statistics to enhance layer-level representation. In the inference phase, the RDU is equally converted to simple dynamic convolutions that explicitly capture robust dynamic and static feature maps. Then, the information distillation block is constructed by several RDUs to enforce hierarchical refinement and selective fusion of spatial context information. Furthermore, we propose a dynamic distillation fusion (DDF) module to enable dynamic signals aggregation and communication between hierarchical modules to further improve performance. Empirical results show that our DDistill-SR outperforms the baselines and achieves state-of-the-art results on most super-resolution domains with much fewer parameters and less computational overhead. We have released the code of DDistill-SR at https://github.com/icandle/DDistill-SR.
* Accepted by IEEE Transactions on Multimedia (TMM)
FedSSA: Semantic Similarity-based Aggregation for Efficient Model-Heterogeneous Personalized Federated Learning
Dec 14, 2023


Federated learning (FL) is a privacy-preserving collaboratively machine learning paradigm. Traditional FL requires all data owners (a.k.a. FL clients) to train the same local model. This design is not well-suited for scenarios involving data and/or system heterogeneity. Model-Heterogeneous Personalized FL (MHPFL) has emerged to address this challenge. Existing MHPFL approaches often rely on having a public dataset with the same nature of the learning task, or incur high computation and communication costs. To address these limitations, we propose the Federated Semantic Similarity Aggregation (FedSSA) approach, which splits each client's model into a heterogeneous (structure-different) feature extractor and a homogeneous (structure-same) classification header. It performs local-to-global knowledge transfer via semantic similarity-based header parameter aggregation. In addition, global-to-local knowledge transfer is achieved via an adaptive parameter stabilization strategy which fuses the seen-class parameters of historical local headers with that of the latest global header for each client. In this way, FedSSA does not rely on public datasets, while only requiring partial header parameter transmission (thereby saving costs). Theoretical analysis proves the convergence of FedSSA. Extensive experiments demonstrate that FedSSA achieves up to $3.62 \times\%$ higher accuracy, $15.54$ times higher communication efficiency, and $15.52 \times$ higher computational efficiency compared to 7 state-of-the-art MHPFL baselines.
pFedES: Model Heterogeneous Personalized Federated Learning with Feature Extractor Sharing
Nov 12, 2023


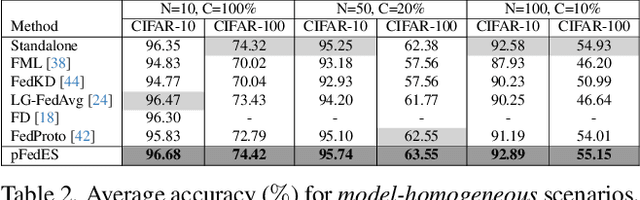
As a privacy-preserving collaborative machine learning paradigm, federated learning (FL) has attracted significant interest from academia and the industry alike. To allow each data owner (a.k.a., FL clients) to train a heterogeneous and personalized local model based on its local data distribution, system resources and requirements on model structure, the field of model-heterogeneous personalized federated learning (MHPFL) has emerged. Existing MHPFL approaches either rely on the availability of a public dataset with special characteristics to facilitate knowledge transfer, incur high computation and communication costs, or face potential model leakage risks. To address these limitations, we propose a model-heterogeneous personalized Federated learning approach based on feature Extractor Sharing (pFedES). It incorporates a small homogeneous feature extractor into each client's heterogeneous local model. Clients train them via the proposed iterative learning method to enable the exchange of global generalized knowledge and local personalized knowledge. The small local homogeneous extractors produced after local training are uploaded to the FL server and for aggregation to facilitate easy knowledge sharing among clients. We theoretically prove that pFedES can converge over wall-to-wall time. Extensive experiments on two real-world datasets against six state-of-the-art methods demonstrate that pFedES builds the most accurate model, while incurring low communication and computation costs. Compared with the best-performing baseline, it achieves 1.61% higher test accuracy, while reducing communication and computation costs by 99.6% and 82.9%, respectively.
FedLoRA: Model-Heterogeneous Personalized Federated Learning with LoRA Tuning
Oct 20, 2023



Federated learning (FL) is an emerging machine learning paradigm in which a central server coordinates multiple participants (a.k.a. FL clients) to train a model collaboratively on decentralized data with privacy protection. This paradigm constrains that all clients have to train models with the same structures (homogeneous). In practice, FL often faces statistical heterogeneity, system heterogeneity and model heterogeneity challenges. These challenging issues inspire the field of Model-Heterogeneous Personalized Federated Learning (MHPFL) which aims to train a personalized and heterogeneous local model for each FL client. Existing MHPFL approaches cannot achieve satisfactory model performance, acceptable computational overhead and efficient communication simultaneously. To bridge this gap, we propose a novel computation- and communication-efficient model-heterogeneous personalized Federated learning framework based on LoRA tuning (FedLoRA). It is designed to incorporate a homogeneous small adapter for each client's heterogeneous local model. Both models are trained following the proposed iterative training for global-local knowledge exchange. The homogeneous small local adapters are sent to the FL server to be aggregated into a global adapter. In this way, FL clients can train heterogeneous local models without incurring high computation and communication costs. We theoretically prove the non-convex convergence rate of FedLoRA. Extensive experiments on two real-world datasets demonstrate that FedLoRA outperforms six state-of-the-art baselines, beating the best approach by 1.35% in terms of test accuracy, 11.81 times computation overhead reduction and 7.41 times communication cost saving.