 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Demystifying and Enhancing the Efficiency of Large Language Model Based Search Agents
May 17, 2025Large Language Model (LLM)-based search agents have shown remarkable capabilities in solving complex tasks by dynamically decomposing problems and addressing them through interleaved reasoning and retrieval. However, this interleaved paradigm introduces substantial efficiency bottlenecks. First, we observe that both highly accurate and overly approximate retrieval methods degrade system efficiency: exact search incurs significant retrieval overhead, while coarse retrieval requires additional reasoning steps during generation. Second, we identify inefficiencies in system design, including improper scheduling and frequent retrieval stalls, which lead to cascading latency -- where even minor delays in retrieval amplify end-to-end inference time. To address these challenges, we introduce SearchAgent-X, a high-efficiency inference framework for LLM-based search agents. SearchAgent-X leverages high-recall approximate retrieval and incorporates two key techniques: priority-aware scheduling and non-stall retrieval. Extensive experiments demonstrate that SearchAgent-X consistently outperforms state-of-the-art systems such as vLLM and HNSW-based retrieval across diverse tasks, achieving up to 3.4$\times$ higher throughput and 5$\times$ lower latency, without compromising generation quality. SearchAgent-X is available at https://github.com/tiannuo-yang/SearchAgent-X.
FreeGraftor: Training-Free Cross-Image Feature Grafting for Subject-Driven Text-to-Image Generation
Apr 22, 2025Subject-driven image generation aims to synthesize novel scenes that faithfully preserve subject identity from reference images while adhering to textual guidance, yet existing methods struggle with a critical trade-off between fidelity and efficiency. Tuning-based approaches rely on time-consuming and resource-intensive subject-specific optimization, while zero-shot methods fail to maintain adequate subject consistency. In this work, we propose FreeGraftor, a training-free framework that addresses these limitations through cross-image feature grafting. Specifically, FreeGraftor employs semantic matching and position-constrained attention fusion to transfer visual details from reference subjects to the generated image. Additionally, our framework incorporates a novel noise initialization strategy to preserve geometry priors of reference subjects for robust feature matching. Extensive qualitative and quantitative experiments demonstrate that our method enables precise subject identity transfer while maintaining text-aligned scene synthesis. Without requiring model fine-tuning or additional training, FreeGraftor significantly outperforms existing zero-shot and training-free approaches in both subject fidelity and text alignment. Furthermore, our framework can seamlessly extend to multi-subject generation, making it practical for real-world deployment. Our code is available at https://github.com/Nihukat/FreeGraftor.
Concept Conductor: Orchestrating Multiple Personalized Concepts in Text-to-Image Synthesis
Aug 07, 2024
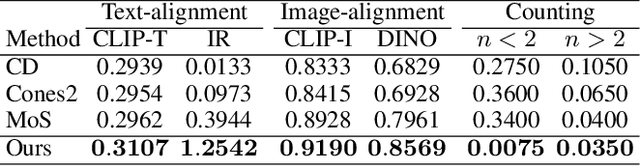
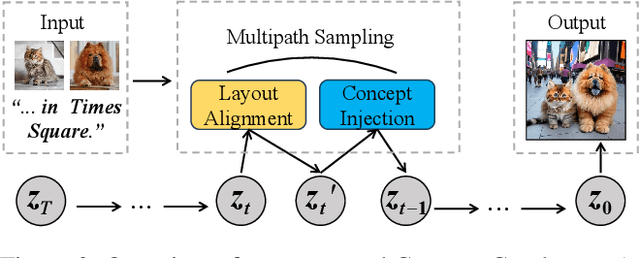
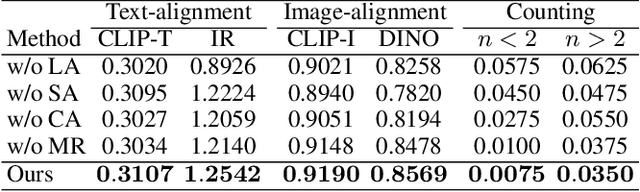
The customization of text-to-image models has seen significant advancements, yet generating multiple personalized concepts remains a challenging task. Current methods struggle with attribute leakage and layout confusion when handling multiple concepts, leading to reduced concept fidelity and semantic consistency. In this work, we introduce a novel training-free framework, Concept Conductor, designed to ensure visual fidelity and correct layout in multi-concept customization. Concept Conductor isolates the sampling processes of multiple custom models to prevent attribute leakage between different concepts and corrects erroneous layouts through self-attention-based spatial guidance. Additionally, we present a concept injection technique that employs shape-aware masks to specify the generation area for each concept. This technique injects the structure and appearance of personalized concepts through feature fusion in the attention layers, ensuring harmony in the final image. Extensive qualitative and quantitative experiments demonstrate that Concept Conductor can consistently generate composite images with accurate layouts while preserving the visual details of each concept. Compared to existing baselines, Concept Conductor shows significant performance improvements. Our method supports the combination of any number of concepts and maintains high fidelity even when dealing with visually similar concepts. The code and models are available at https://github.com/Nihukat/Concept-Conductor.