 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeGraftor: Training-Free Cross-Image Feature Grafting for Subject-Driven Text-to-Image Generation
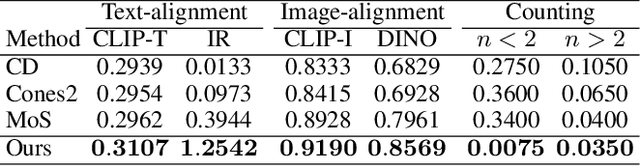
Apr 22, 2025Subject-driven image generation aims to synthesize novel scenes that faithfully preserve subject identity from reference images while adhering to textual guidance, yet existing methods struggle with a critical trade-off between fidelity and efficiency. Tuning-based approaches rely on time-consuming and resource-intensive subject-specific optimization, while zero-shot methods fail to maintain adequate subject consistency. In this work, we propose FreeGraftor, a training-free framework that addresses these limitations through cross-image feature grafting. Specifically, FreeGraftor employs semantic matching and position-constrained attention fusion to transfer visual details from reference subjects to the generated image. Additionally, our framework incorporates a novel noise initialization strategy to preserve geometry priors of reference subjects for robust feature matching. Extensive qualitative and quantitative experiments demonstrate that our method enables precise subject identity transfer while maintaining text-aligned scene synthesis. Without requiring model fine-tuning or additional training, FreeGraftor significantly outperforms existing zero-shot and training-free approaches in both subject fidelity and text alignment. Furthermore, our framework can seamlessly extend to multi-subject generation, making it practical for real-world deployment. Our code is available at https://github.com/Nihukat/FreeGraftor.
Concept Conductor: Orchestrating Multiple Personalized Concepts in Text-to-Image Synthesis
Aug 07, 2024
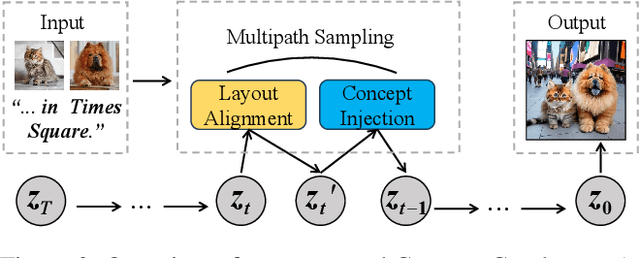
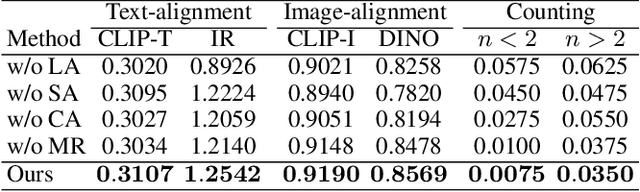
The customization of text-to-image models has seen significant advancements, yet generating multiple personalized concepts remains a challenging task. Current methods struggle with attribute leakage and layout confusion when handling multiple concepts, leading to reduced concept fidelity and semantic consistency. In this work, we introduce a novel training-free framework, Concept Conductor, designed to ensure visual fidelity and correct layout in multi-concept customization. Concept Conductor isolates the sampling processes of multiple custom models to prevent attribute leakage between different concepts and corrects erroneous layouts through self-attention-based spatial guidance. Additionally, we present a concept injection technique that employs shape-aware masks to specify the generation area for each concept. This technique injects the structure and appearance of personalized concepts through feature fusion in the attention layers, ensuring harmony in the final image. Extensive qualitative and quantitative experiments demonstrate that Concept Conductor can consistently generate composite images with accurate layouts while preserving the visual details of each concept. Compared to existing baselines, Concept Conductor shows significant performance improvements. Our method supports the combination of any number of concepts and maintains high fidelity even when dealing with visually similar concepts. The code and models are available at https://github.com/Nihukat/Concept-Conductor.
Constructing Hierarchical Image-tags Bimodal Representations for Word Tags Alternative Choice
Jul 04, 2013


This paper describes our solution to the multi-modal learning challenge of ICML. This solution comprises constructing three-level representations in three consecutive stages and choosing correct tag words with a data-specific strategy. Firstly, we use typical methods to obtain level-1 representations. Each image is represented using MPEG-7 and gist descriptors with additional features released by the contest organizers. And the corresponding word tags are represented by bag-of-words model with a dictionary of 4000 words. Secondly, we learn the level-2 representations using two stacked RBMs for each modality. Thirdly, we propose a bimodal auto-encoder to learn the similarities/dissimilarities between the pairwise image-tags as level-3 representations. Finally, during the test phase, based on one observation of the dataset, we come up with a data-specific strategy to choose the correct tag words leading to a leap of an improved overall performance. Our final average accuracy on the private test set is 100%, which ranks the first place in this challenge.
Challenges in Representation Learning: A report on three machine learning contests
Jul 01, 2013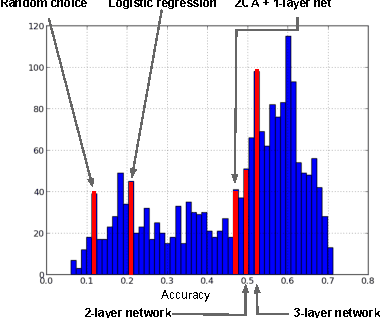

The ICML 2013 Workshop on Challenges in Representation Learning focused on three challenges: the black box learning challenge, the facial expression recognition challenge, and the multimodal learning challenge. We describe the datasets created for these challenges and summarize the results of the competitions. We provide suggestions for organizers of future challenges and some comments on what kind of knowledge can be gained from machine learning competitions.