 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-to-Hero: Zero-Shot Initialization Empowering Reference-Based Video Appearance Editing
May 29, 2025Appearance editing according to user needs is a pivotal task in video editing. Existing text-guided methods often lead to ambiguities regarding user intentions and restrict fine-grained control over editing specific aspects of objects. To overcome these limitations, this paper introduces a novel approach named {Zero-to-Hero}, which focuses on reference-based video editing that disentangles the editing process into two distinct problems. It achieves this by first editing an anchor frame to satisfy user requirements as a reference image and then consistently propagating its appearance across other frames. We leverage correspondence within the original frames to guide the attention mechanism, which is more robust than previously proposed optical flow or temporal modules in memory-friendly video generative models, especially when dealing with objects exhibiting large motions. It offers a solid ZERO-shot initialization that ensures both accuracy and temporal consistency. However, intervention in the attention mechanism results in compounded imaging degradation with over-saturated colors and unknown blurring issues. Starting from Zero-Stage, our Hero-Stage Holistically learns a conditional generative model for vidEo RestOration. To accurately evaluate the consistency of the appearance, we construct a set of videos with multiple appearances using Blender, enabling a fine-grained and deterministic evaluation. Our method outperforms the best-performing baseline with a PSNR improvement of 2.6 dB. The project page is at https://github.com/Tonniia/Zero2Hero.
Understanding Attention Mechanism in Video Diffusion Models
Apr 16, 2025Text-to-video (T2V) synthesis models, such as OpenAI's Sora, have garnered significant attention due to their ability to generate high-quality videos from a text prompt. In diffusion-based T2V models, the attention mechanism is a critical component. However, it remains unclear what intermediate features are learned and how attention blocks in T2V models affect various aspects of video synthesis, such as image quality and temporal consistency. In this paper, we conduct an in-depth perturbation analysis of the spatial and temporal attention blocks of T2V models using an information-theoretic approach. Our results indicate that temporal and spatial attention maps affect not only the timing and layout of the videos but also the complexity of spatiotemporal elements and the aesthetic quality of the synthesized videos. Notably, high-entropy attention maps are often key elements linked to superior video quality, whereas low-entropy attention maps are associated with the video's intra-frame structure. Based on our findings, we propose two novel methods to enhance video quality and enable text-guided video editing. These methods rely entirely on lightweight manipulation of the attention matrices in T2V models. The efficacy and effectiveness of our methods are further validated through experimental evaluation across multiple datasets.
DDistill-SR: Reparameterized Dynamic Distillation Network for Lightweight Image Super-Resolution
Dec 22, 2023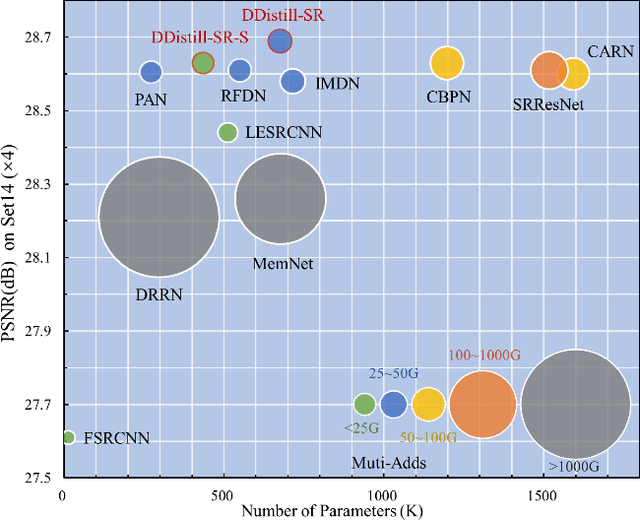
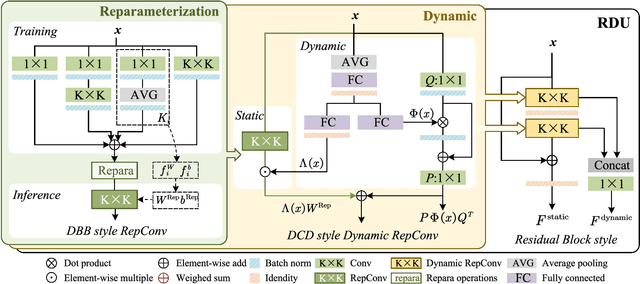
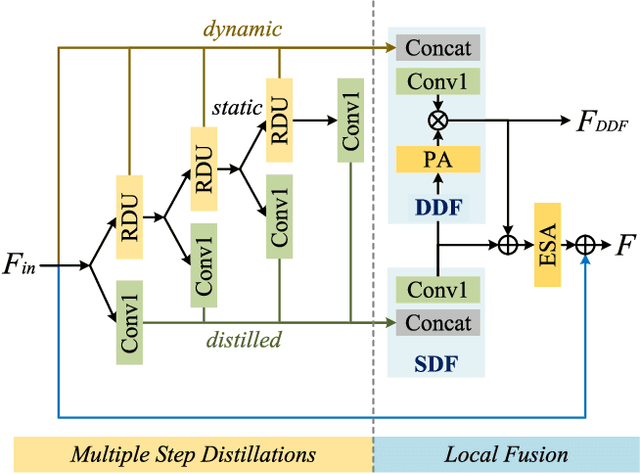
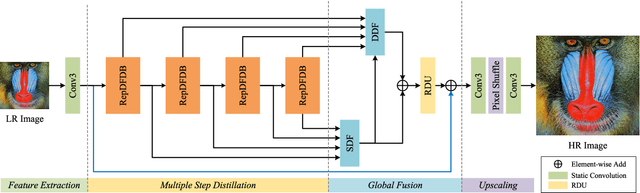
Recent research on deep convolutional neural networks (CNNs) has provided a significant performance boost on efficient super-resolution (SR) tasks by trading off the performance and applicability. However, most existing methods focus on subtracting feature processing consumption to reduce the parameters and calculations without refining the immediate features, which leads to inadequate information in the restoration. In this paper, we propose a lightweight network termed DDistill-SR, which significantly improves the SR quality by capturing and reusing more helpful information in a static-dynamic feature distillation manner. Specifically, we propose a plug-in reparameterized dynamic unit (RDU) to promote the performance and inference cost trade-off. During the training phase, the RDU learns to linearly combine multiple reparameterizable blocks by analyzing varied input statistics to enhance layer-level representation. In the inference phase, the RDU is equally converted to simple dynamic convolutions that explicitly capture robust dynamic and static feature maps. Then, the information distillation block is constructed by several RDUs to enforce hierarchical refinement and selective fusion of spatial context information. Furthermore, we propose a dynamic distillation fusion (DDF) module to enable dynamic signals aggregation and communication between hierarchical modules to further improve performance. Empirical results show that our DDistill-SR outperforms the baselines and achieves state-of-the-art results on most super-resolution domains with much fewer parameters and less computational overhead. We have released the code of DDistill-SR at https://github.com/icandle/DDistill-SR.
* Accepted by IEEE Transactions on Multimedia (TMM)