 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Chain of Behavior for User Trajectory Prediction
Jan 26, 2026Modeling long-term user behavior trajectories is essential for understanding evolving preferences and enabling proactive recommendations. However, most sequential recommenders focus on next-item prediction, overlooking dependencies across multiple future actions. We propose Generative Chain of Behavior (GCB), a generative framework that models user interactions as an autoregressive chain of semantic behaviors over multiple future steps. GCB first encodes items into semantic IDs via RQ-VAE with k-means refinement, forming a discrete latent space that preserves semantic proximity. On top of this space, a transformer-based autoregressive generator predicts multi-step future behaviors conditioned on user history, capturing long-horizon intent transitions and generating coherent trajectories. Experiments on benchmark datasets show that GCB consistently outperforms state-of-the-art sequential recommenders in multi-step accuracy and trajectory consistency. Beyond these gains, GCB offers a unified generative formulation for capturing user preference evolution.
A Survey of Foundation Model-Powered Recommender Systems: From Feature-Based, Generative to Agentic Paradigms
Apr 23, 2025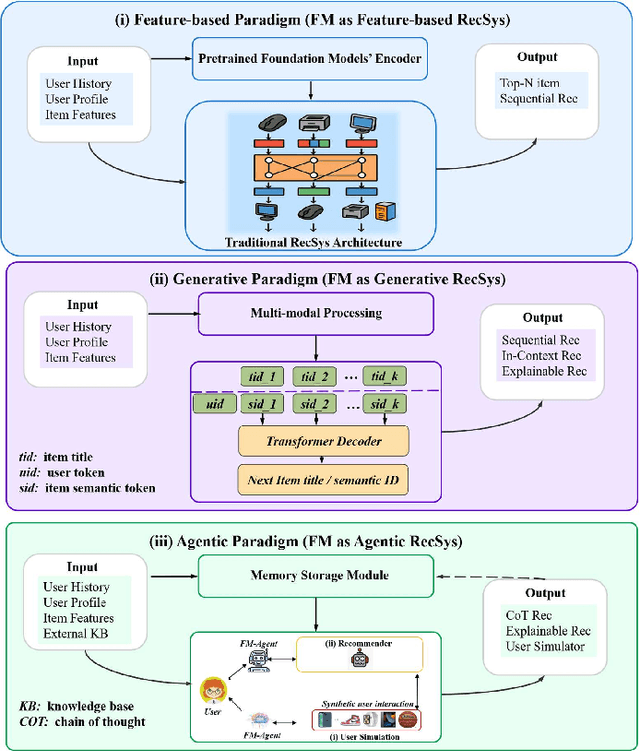
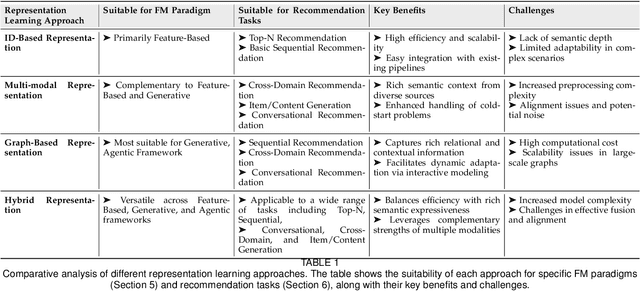
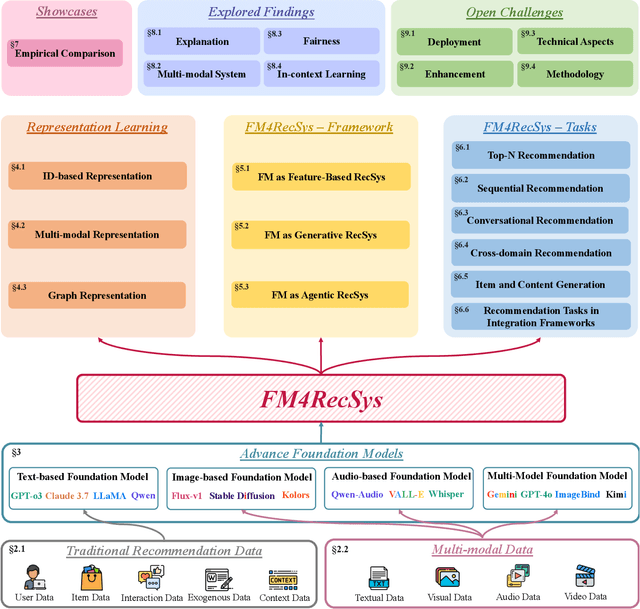
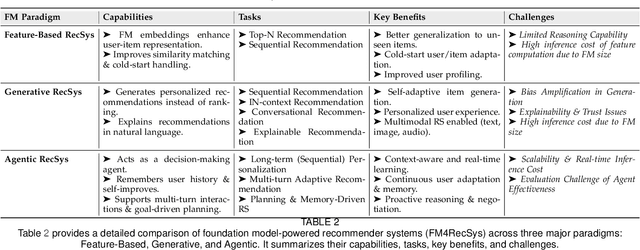
Recommender systems (RS) have become essential in filtering information and personalizing content for users. RS techniques have traditionally relied on modeling interactions between users and items as well as the features of content using models specific to each task. The emergence of foundation models (FMs), large scale models trained on vast amounts of data such as GPT, LLaMA and CLIP, is reshaping the recommendation paradigm. This survey provides a comprehensive overview of the Foundation Models for Recommender Systems (FM4RecSys), covering their integration in three paradigms: (1) Feature-Based augmentation of representations, (2) Generative recommendation approaches, and (3) Agentic interactive systems. We first review the data foundations of RS, from traditional explicit or implicit feedback to multimodal content sources. We then introduce FMs and their capabilities for representation learning, natural language understanding, and multi-modal reasoning in RS contexts. The core of the survey discusses how FMs enhance RS under different paradigms. Afterward, we examine FM applications in various recommendation tasks. Through an analysis of recent research, we highlight key opportunities that have been realized as well as challenges encountered. Finally, we outline open research directions and technical challenges for next-generation FM4RecSys. This survey not only reviews the state-of-the-art methods but also provides a critical analysis of the trade-offs among the feature-based, the generative, and the agentic paradigms, outlining key open issues and future research directions.
Dual Conditional Diffusion Models for Sequential Recommendation
Oct 29, 2024



Recent advancements in diffusion models have shown promising results in sequential recommendation (SR). However, current diffusion-based methods still exhibit two key limitations. First, they implicitly model the diffusion process for target item embeddings rather than the discrete target item itself, leading to inconsistency in the recommendation process. Second, existing methods rely on either implicit or explicit conditional diffusion models, limiting their ability to fully capture the context of user behavior and leading to less robust target item embeddings. In this paper, we propose the Dual Conditional Diffusion Models for Sequential Recommendation (DCRec), introducing a discrete-to-continuous sequential recommendation diffusion framework. Our framework introduces a complete Markov chain to model the transition from the reversed target item representation to the discrete item index, bridging the discrete and continuous item spaces for diffusion models and ensuring consistency with the diffusion framework. Building on this framework, we present the Dual Conditional Diffusion Transformer (DCDT) that incorporates the implicit conditional and the explicit conditional for diffusion-based SR. Extensive experiments on public benchmark datasets demonstrate that DCRec outperforms state-of-the-art methods.
Flexiffusion: Segment-wise Neural Architecture Search for Flexible Denoising Schedule
Sep 26, 2024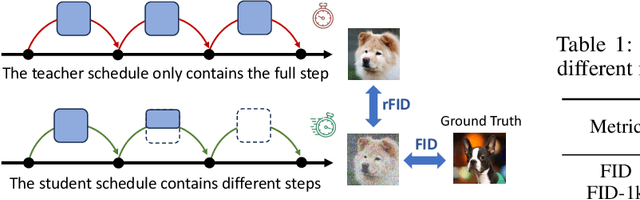
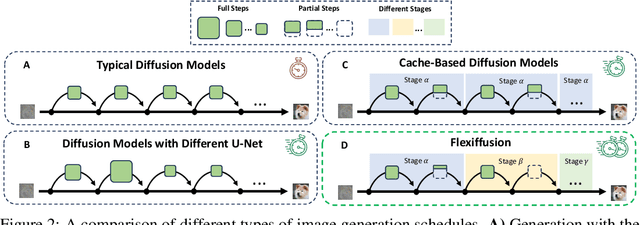


Diffusion models are cutting-edge generative models adept at producing diverse, high-quality images. Despite their effectiveness, these models often require significant computational resources owing to their numerous sequential denoising steps and the significant inference cost of each step. Recently, Neural Architecture Search (NAS) techniques have been employed to automatically search for faster generation processes. However, NAS for diffusion is inherently time-consuming as it requires estimating thousands of diffusion models to search for the optimal one. In this paper, we introduce Flexiffusion, a novel training-free NAS paradigm designed to accelerate diffusion models by concurrently optimizing generation steps and network structures. Specifically, we partition the generation process into isometric step segments, each sequentially composed of a full step, multiple partial steps, and several null steps. The full step computes all network blocks, while the partial step involves part of the blocks, and the null step entails no computation. Flexiffusion autonomously explores flexible step combinations for each segment, substantially reducing search costs and enabling greater acceleration compared to the state-of-the-art (SOTA) method for diffusion models. Our searched models reported speedup factors of $2.6\times$ and $1.5\times$ for the original LDM-4-G and the SOTA, respectively. The factors for Stable Diffusion V1.5 and the SOTA are $5.1\times$ and $2.0\times$. We also verified the performance of Flexiffusion on multiple datasets, and positive experiment results indicate that Flexiffusion can effectively reduce redundancy in diffusion models.
MatchNAS: Optimizing Edge AI in Sparse-Label Data Contexts via Automating Deep Neural Network Porting for Mobile Deployment
Feb 21, 2024



Recent years have seen the explosion of edge intelligence with powerful Deep Neural Networks (DNNs). One popular scheme is training DNNs on powerful cloud servers and subsequently porting them to mobile devices after being lightweight. Conventional approaches manually specialized DNNs for various edge platforms and retrain them with real-world data. However, as the number of platforms increases, these approaches become labour-intensive and computationally prohibitive. Additionally, real-world data tends to be sparse-label, further increasing the difficulty of lightweight models. In this paper, we propose MatchNAS, a novel scheme for porting DNNs to mobile devices. Specifically, we simultaneously optimise a large network family using both labelled and unlabelled data and then automatically search for tailored networks for different hardware platforms. MatchNAS acts as an intermediary that bridges the gap between cloud-based DNNs and edge-based DNNs.