 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVistaGEN: Consistent Driving Video Generation with Fine-Grained Control Using Multiview Visual-Language Reasoning
Mar 30, 2026Driving video generation has achieved much progress in controllability, video resolution, and length, but fails to support fine-grained object-level controllability for diverse driving videos, while preserving the spatiotemporal consistency, especially in long video generation. In this paper, we present a new driving video generation technique, called VistaGEN, which enables fine-grained control of specific entities, including 3D objects, images, and text descriptions, while maintaining spatiotemporal consistency in long video sequences. Our key innovation is the incorporation of multiview visual-language reasoning into the long driving video generation. To this end, we inject visual-language features into a multiview video generator to enable fine-grained controllability. More importantly, we propose a multiview vision-language evaluator (MV-VLM) to intelligently and automatically evaluate spatiotemporal consistency of the generated content, thus formulating a novel generation-evaluation-regeneration closed-loop generation mechanism. This mechanism ensures high-quality, coherent outputs, facilitating the creation of complex and reliable driving scenarios. Besides, within the closed-loop generation, we introduce an object-level refinement module to refine the unsatisfied results evaluated from the MV-VLM and then feed them back to the video generator for regeneration. Extensive evaluation shows that our VistaGEN achieves diverse driving video generation results with fine-grained controllability, especially for long-tail objects, and much better spatiotemporal consistency than previous approaches.
When Convenience Becomes Risk: A Semantic View of Under-Specification in Host-Acting Agents
Mar 22, 2026Host-acting agents promise a convenient interaction model in which users specify goals and the system determines how to realize them. We argue that this convenience introduces a distinct security problem: semantic under-specification in goal specification. User instructions are typically goal-oriented, yet they often leave process constraints, safety boundaries, persistence, and exposure insufficiently specified. As a result, the agent must complete missing execution semantics before acting, and this completion can produce risky host-side plans even when the user-stated goal is benign. In this paper, we develop a semantic threat model, present a taxonomy of semantic-induced risky completion patterns, and study the phenomenon through an OpenClaw-centered case study and execution-trace analysis. We further derive defense design principles for making execution boundaries explicit and constraining risky completion. These findings suggest that securing host-acting agents requires governing not only which actions are allowed at execution time, but also how goal-only instructions are translated into executable plans.
Recurrent Preference Memory for Efficient Long-Sequence Generative Recommendation
Feb 13, 2026Generative recommendation (GenRec) models typically model user behavior via full attention, but scaling to lifelong sequences is hindered by prohibitive computational costs and noise accumulation from stochastic interactions. To address these challenges, we introduce Rec2PM, a framework that compresses long user interaction histories into compact Preference Memory tokens. Unlike traditional recurrent methods that suffer from serial training, Rec2PM employs a novel self-referential teacher-forcing strategy: it leverages a global view of the history to generate reference memories, which serve as supervision targets for parallelized recurrent updates. This allows for fully parallel training while maintaining the capability for iterative updates during inference. Additionally, by representing memory as token embeddings rather than extensive KV caches, Rec2PM achieves extreme storage efficiency. Experiments on large-scale benchmarks show that Rec2PM significantly reduces inference latency and memory footprint while achieving superior accuracy compared to full-sequence models. Analysis reveals that the Preference Memory functions as a denoising Information Bottleneck, effectively filtering interaction noise to capture robust long-term interests.
PRISM: Parallel Residual Iterative Sequence Model
Feb 12, 2026Generative sequence modeling faces a fundamental tension between the expressivity of Transformers and the efficiency of linear sequence models. Existing efficient architectures are theoretically bounded by shallow, single-step linear updates, while powerful iterative methods like Test-Time Training (TTT) break hardware parallelism due to state-dependent gradients. We propose PRISM (Parallel Residual Iterative Sequence Model) to resolve this tension. PRISM introduces a solver-inspired inductive bias that captures key structural properties of multi-step refinement in a parallelizable form. We employ a Write-Forget Decoupling strategy that isolates non-linearity within the injection operator. To bypass the serial dependency of explicit solvers, PRISM utilizes a two-stage proxy architecture: a short-convolution anchors the initial residual using local history energy, while a learned predictor estimates the refinement updates directly from the input. This design distills structural patterns associated with iterative correction into a parallelizable feedforward operator. Theoretically, we prove that this formulation achieves Rank-$L$ accumulation, structurally expanding the update manifold beyond the single-step Rank-$1$ bottleneck. Empirically, it achieves comparable performance to explicit optimization methods while achieving 174x higher throughput.
Differentially Private Subspace Fine-Tuning for Large Language Models
Jan 16, 2026Fine-tuning large language models on downstream tasks is crucial for realizing their cross-domain potential but often relies on sensitive data, raising privacy concerns. Differential privacy (DP) offers rigorous privacy guarantees and has been widely adopted in fine-tuning; however, naively injecting noise across the high-dimensional parameter space creates perturbations with large norms, degrading performance and destabilizing training. To address this issue, we propose DP-SFT, a two-stage subspace fine-tuning method that substantially reduces noise magnitude while preserving formal DP guarantees. Our intuition is that, during fine-tuning, significant parameter updates lie within a low-dimensional, task-specific subspace, while other directions change minimally. Hence, we only inject DP noise into this subspace to protect privacy without perturbing irrelevant parameters. In phase one, we identify the subspace by analyzing principal gradient directions to capture task-specific update signals. In phase two, we project full gradients onto this subspace, add DP noise, and map the perturbed gradients back to the original parameter space for model updates, markedly lowering noise impact. Experiments on multiple datasets demonstrate that DP-SFT enhances accuracy and stability under rigorous DP constraints, accelerates convergence, and achieves substantial gains over DP fine-tuning baselines.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
P/D-Device: Disaggregated Large Language Model between Cloud and Devices
Aug 12, 2025Serving disaggregated large language models has been widely adopted in industrial practice for enhanced performance. However, too many tokens generated in decoding phase, i.e., occupying the resources for a long time, essentially hamper the cloud from achieving a higher throughput. Meanwhile, due to limited on-device resources, the time to first token (TTFT), i.e., the latency of prefill phase, increases dramatically with the growth on prompt length. In order to concur with such a bottleneck on resources, i.e., long occupation in cloud and limited on-device computing capacity, we propose to separate large language model between cloud and devices. That is, the cloud helps a portion of the content for each device, only in its prefill phase. Specifically, after receiving the first token from the cloud, decoupling with its own prefill, the device responds to the user immediately for a lower TTFT. Then, the following tokens from cloud are presented via a speed controller for smoothed TPOT (the time per output token), until the device catches up with the progress. On-device prefill is then amortized using received tokens while the resource usage in cloud is controlled. Moreover, during cloud prefill, the prompt can be refined, using those intermediate data already generated, to further speed up on-device inference. We implement such a scheme P/D-Device, and confirm its superiority over other alternatives. We further propose an algorithm to decide the best settings. Real-trace experiments show that TTFT decreases at least 60%, maximum TPOT is about tens of milliseconds, and cloud throughput increases by up to 15x.
CAKE: Cascading and Adaptive KV Cache Eviction with Layer Preferences
Mar 16, 2025



Large language models (LLMs) excel at processing long sequences, boosting demand for key-value (KV) caching. While recent efforts to evict KV cache have alleviated the inference burden, they often fail to allocate resources rationally across layers with different attention patterns. In this paper, we introduce Cascading and Adaptive KV cache Eviction (CAKE), a novel approach that frames KV cache eviction as a "cake-slicing problem." CAKE assesses layer-specific preferences by considering attention dynamics in both spatial and temporal dimensions, allocates rational cache size for layers accordingly, and manages memory constraints in a cascading manner. This approach enables a global view of cache allocation, adaptively distributing resources across diverse attention mechanisms while maintaining memory budgets. CAKE also employs a new eviction indicator that considers the shifting importance of tokens over time, addressing limitations in existing methods that overlook temporal dynamics. Comprehensive experiments on LongBench and NeedleBench show that CAKE maintains model performance with only 3.2% of the KV cache and consistently outperforms current baselines across various models and memory constraints, particularly in low-memory settings. Additionally, CAKE achieves over 10x speedup in decoding latency compared to full cache when processing contexts of 128K tokens with FlashAttention-2. Our code is available at https://github.com/antgroup/cakekv.
FairKV: Balancing Per-Head KV Cache for Fast Multi-GPU Inference
Feb 19, 2025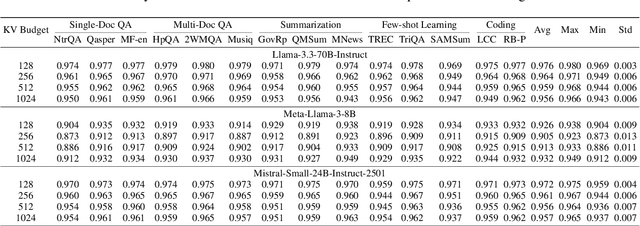
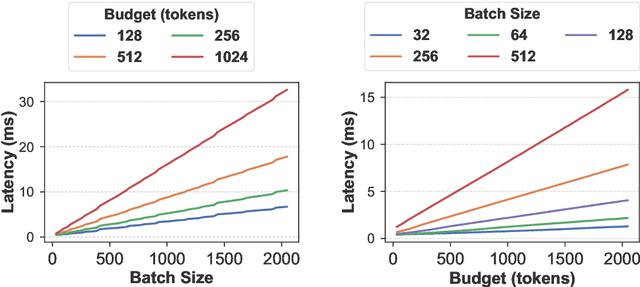
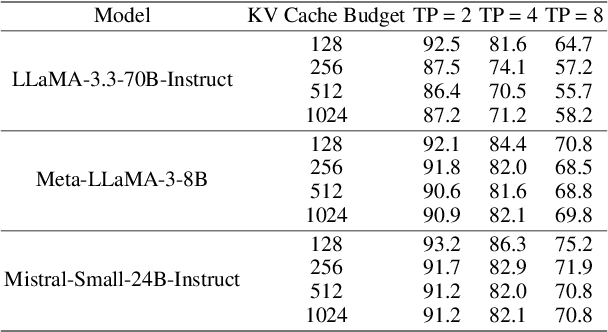
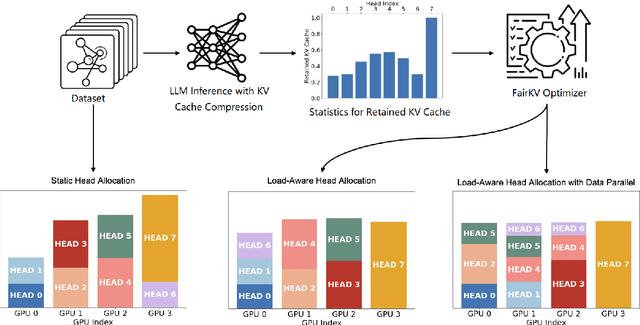
KV cache techniques in Transformer models aim to reduce redundant computations at the expense of substantially increased memory usage, making KV cache compression an important and popular research topic. Recently, state-of-the-art KV cache compression methods implement imbalanced, per-head allocation algorithms that dynamically adjust the KV cache budget for each attention head, achieving excellent performance in single-GPU scenarios. However, we observe that such imbalanced compression leads to significant load imbalance when deploying multi-GPU inference, as some GPUs become overburdened while others remain underutilized. In this paper, we propose FairKV, a method designed to ensure fair memory usage among attention heads in systems employing imbalanced KV cache compression. The core technique of FairKV is Fair-Copying, which replicates a small subset of memory-intensive attention heads across GPUs using data parallelism to mitigate load imbalance. Our experiments on popular models, including LLaMA 70b and Mistral 24b model, demonstrate that FairKV increases throughput by 1.66x compared to standard tensor parallelism inference. Our code will be released as open source upon acceptance.
DrivingDojo Dataset: Advancing Interactive and Knowledge-Enriched Driving World Model
Oct 14, 2024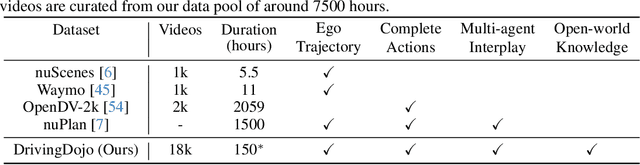
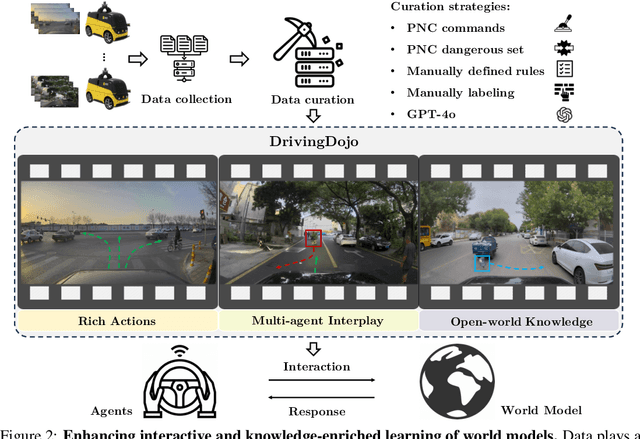

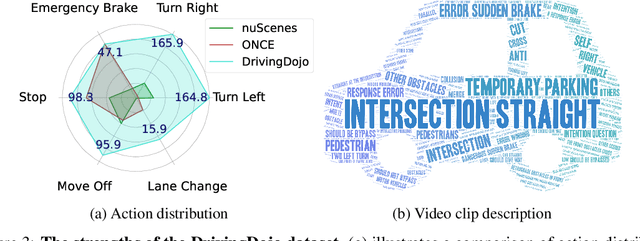
Driving world models have gained increasing attention due to their ability to model complex physical dynamics. However, their superb modeling capability is yet to be fully unleashed due to the limited video diversity in current driving datasets. We introduce DrivingDojo, the first dataset tailor-made for training interactive world models with complex driving dynamics. Our dataset features video clips with a complete set of driving maneuvers, diverse multi-agent interplay, and rich open-world driving knowledge, laying a stepping stone for future world model development. We further define an action instruction following (AIF) benchmark for world models and demonstrate the superiority of the proposed dataset for generating action-controlled future predictions.