 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairKV: Balancing Per-Head KV Cache for Fast Multi-GPU Inference
Feb 19, 2025
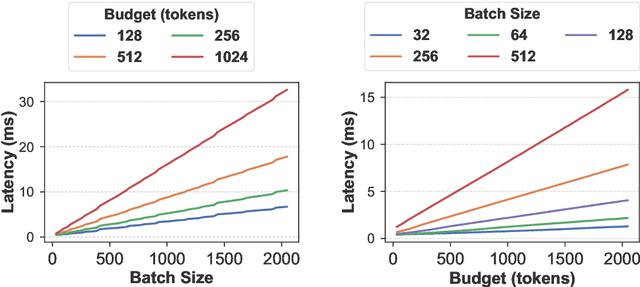
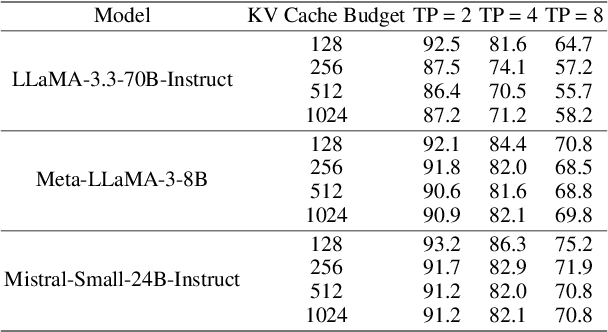
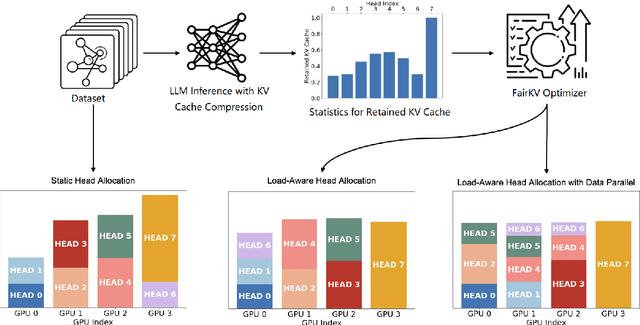
KV cache techniques in Transformer models aim to reduce redundant computations at the expense of substantially increased memory usage, making KV cache compression an important and popular research topic. Recently, state-of-the-art KV cache compression methods implement imbalanced, per-head allocation algorithms that dynamically adjust the KV cache budget for each attention head, achieving excellent performance in single-GPU scenarios. However, we observe that such imbalanced compression leads to significant load imbalance when deploying multi-GPU inference, as some GPUs become overburdened while others remain underutilized. In this paper, we propose FairKV, a method designed to ensure fair memory usage among attention heads in systems employing imbalanced KV cache compression. The core technique of FairKV is Fair-Copying, which replicates a small subset of memory-intensive attention heads across GPUs using data parallelism to mitigate load imbalance. Our experiments on popular models, including LLaMA 70b and Mistral 24b model, demonstrate that FairKV increases throughput by 1.66x compared to standard tensor parallelism inference. Our code will be released as open source upon acceptance.
Lyra: A Benchmark for Turducken-Style Code Generation
Aug 27, 2021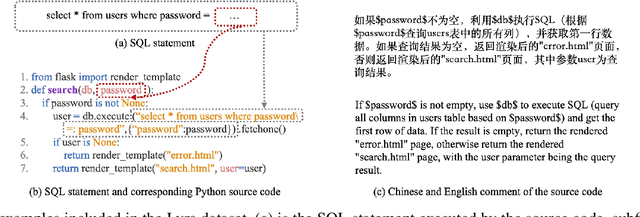
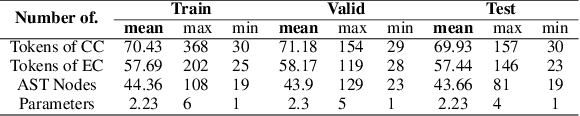
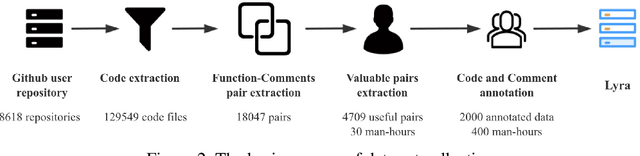
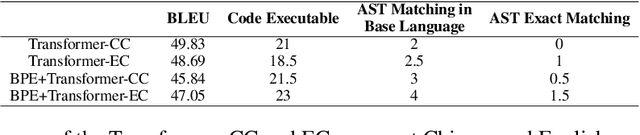
Code generation is crucial to reduce manual software development efforts. Recently, neural techniques have been used to generate source code automatically. While promising, these approaches are evaluated on tasks for generating code in single programming languages. However, in actual development, one programming language is often embedded in another. For example, SQL statements are often embedded as strings in base programming languages such as Python and Java, and JavaScript programs are often embedded in sever-side programming languages, such as PHP, Java, and Python. We call this a turducken-style programming. In this paper, we define a new code generation task: given a natural language comment, this task aims to generate a program in a base language with an embedded language. To our knowledge, this is the first turducken-style code generation task. For this task, we present Lyra: a dataset in Python with embedded SQL. This dataset contains 2,000 carefully annotated database manipulation programs from real usage projects. Each program is paired with both a Chinese comment and an English comment. In our experiment, we adopted Transformer, a state-of-the-art technique, as the baseline. In the best setting, Transformer achieves 0.5% and 1.5% AST exact matching accuracy using Chinese and English comments, respectively. Therefore, we believe that Lyra provides a new challenge for code generation.
Survey of Imbalanced Data Methodologies
Apr 06, 2021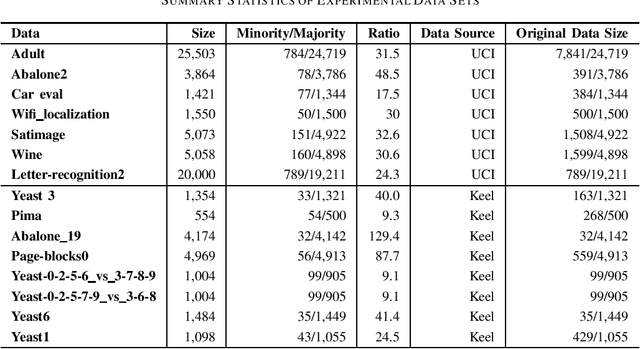

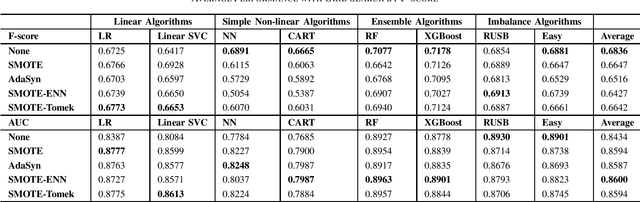
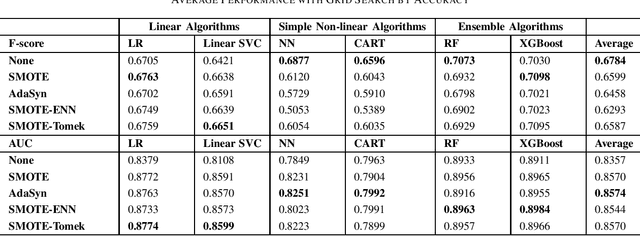
Imbalanced data set is a problem often found and well-studied in financial industry. In this paper, we reviewed and compared some popular methodologies handling data imbalance. We then applied the under-sampling/over-sampling methodologies to several modeling algorithms on UCI and Keel data sets. The performance was analyzed for class-imbalance methods, modeling algorithms and grid search criteria comparison.