 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeepKV: Eliminating Output Perturbation in KV Cache Compression for Efficient LLMs Inference
Apr 14, 2025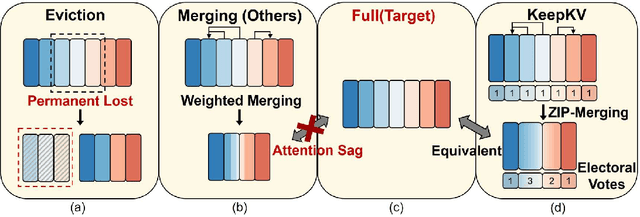
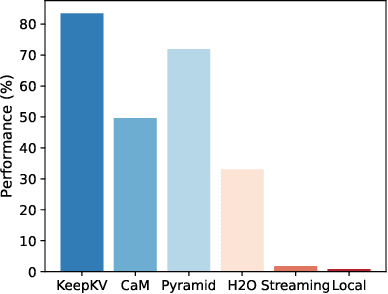
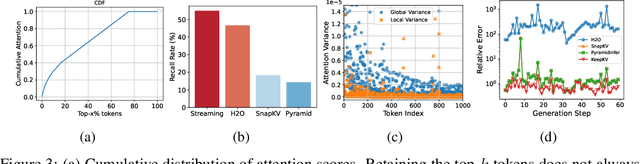
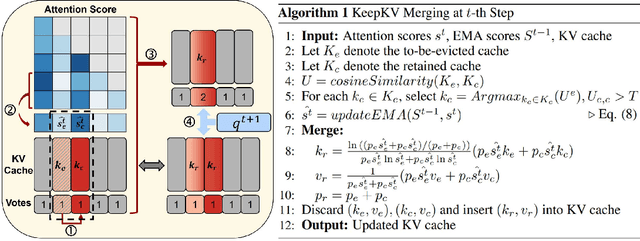
Efficient inference of large language models (LLMs) is hindered by an ever-growing key-value (KV) cache, making KV cache compression a critical research direction. Traditional methods selectively evict less important KV cache entries based on attention scores or position heuristics, which leads to information loss and hallucinations. Recently, merging-based strategies have been explored to retain more information by merging KV pairs that would be discarded; however, these existing approaches inevitably introduce inconsistencies in attention distributions before and after merging, causing output perturbation and degraded generation quality. To overcome this challenge, we propose KeepKV, a novel adaptive KV cache merging method designed to eliminate output perturbation while preserving performance under strict memory constraints. KeepKV introduces the Electoral Votes mechanism that records merging history and adaptively adjusts attention scores. Moreover, it further leverages a novel Zero Inference-Perturbation Merging methods, keeping attention consistency and compensating for attention loss resulting from cache merging. KeepKV successfully retains essential context information within a significantly compressed cache. Extensive experiments on various benchmarks and LLM architectures demonstrate that KeepKV substantially reduces memory usage, enhances inference throughput by more than 2x and keeps superior generation quality even with 10% KV cache budgets.
FairKV: Balancing Per-Head KV Cache for Fast Multi-GPU Inference
Feb 19, 2025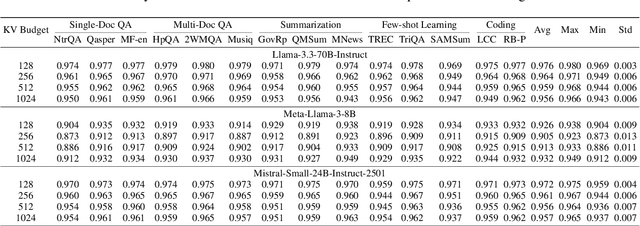
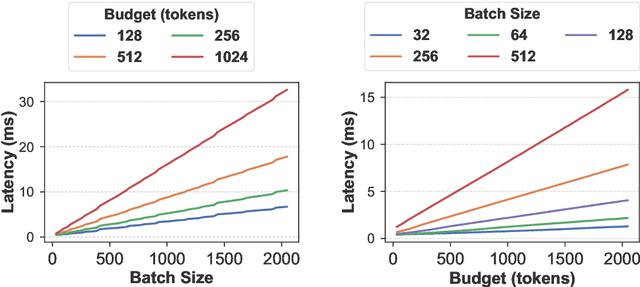
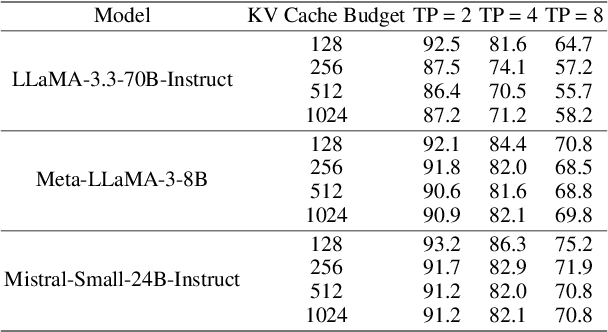
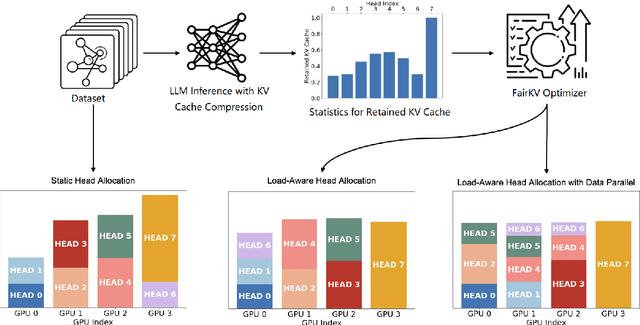
KV cache techniques in Transformer models aim to reduce redundant computations at the expense of substantially increased memory usage, making KV cache compression an important and popular research topic. Recently, state-of-the-art KV cache compression methods implement imbalanced, per-head allocation algorithms that dynamically adjust the KV cache budget for each attention head, achieving excellent performance in single-GPU scenarios. However, we observe that such imbalanced compression leads to significant load imbalance when deploying multi-GPU inference, as some GPUs become overburdened while others remain underutilized. In this paper, we propose FairKV, a method designed to ensure fair memory usage among attention heads in systems employing imbalanced KV cache compression. The core technique of FairKV is Fair-Copying, which replicates a small subset of memory-intensive attention heads across GPUs using data parallelism to mitigate load imbalance. Our experiments on popular models, including LLaMA 70b and Mistral 24b model, demonstrate that FairKV increases throughput by 1.66x compared to standard tensor parallelism inference. Our code will be released as open source upon acceptance.
Prediction Is All MoE Needs: Expert Load Distribution Goes from Fluctuating to Stabilizing
Apr 25, 2024MoE facilitates the development of large models by making the computational complexity of the model no longer scale linearly with increasing parameters. The learning sparse gating network selects a set of experts for each token to be processed; however, this may lead to differences in the number of tokens processed by each expert over several successive iterations, i.e., the expert load fluctuations, which reduces computational parallelization and resource utilization. To this end, we traced and analyzed loads of each expert in the training iterations for several large language models in this work, and defined the transient state with "obvious load fluctuation" and the stable state with "temporal locality". Moreover, given the characteristics of these two states and the computational overhead, we deployed three classical prediction algorithms that achieve accurate expert load prediction results. For the GPT3 350M model, the average error rates for predicting the expert load proportion over the next 1,000 and 2,000 steps are approximately 1.3% and 1.8%, respectively. This work can provide valuable guidance for expert placement or resource allocation for MoE model training. Based on this work, we will propose an expert placement scheme for transient and stable states in our coming work.