 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoarePrompt: Structural Reasoning About Program Correctness in Natural Language
Mar 25, 2025



While software requirements are often expressed in natural language, verifying the correctness of a program against natural language requirements is a hard and underexplored problem. Large language models (LLMs) are promising candidates for addressing this challenge, however our experience shows that they are ineffective in this task, often failing to detect even straightforward bugs. To address this gap, we introduce HoarePrompt, a novel approach that adapts fundamental ideas from program analysis and verification to natural language artifacts. Drawing inspiration from the strongest postcondition calculus, HoarePrompt employs a systematic, step-by-step process in which an LLM generates natural language descriptions of reachable program states at various points in the code. To manage loops, we propose few-shot-driven k-induction, an adaptation of the k-induction method widely used in model checking. Once program states are described, HoarePrompt leverages the LLM to assess whether the program, annotated with these state descriptions, conforms to the natural language requirements. For evaluating the quality of classifiers of program correctness with respect to natural language requirements, we constructed CoCoClaNeL, a challenging dataset of solutions to programming competition problems. Our experiments show that HoarePrompt improves the MCC by 62% compared to directly using Zero-shot-CoT prompts for correctness classification. Furthermore, HoarePrompt outperforms a classifier that assesses correctness via LLM-based test generation by increasing the MCC by 93%. The inductive reasoning mechanism contributes a 28% boost to MCC, underscoring its effectiveness in managing loops.
Grammar-Based Code Representation: Is It a Worthy Pursuit for LLMs?
Mar 07, 2025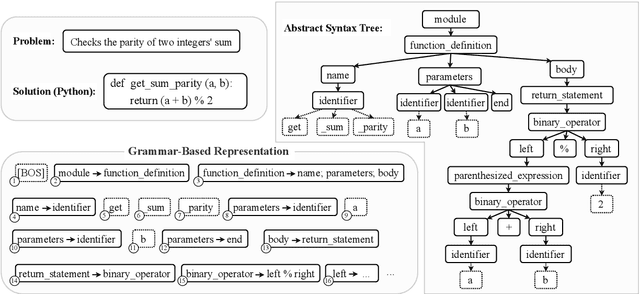
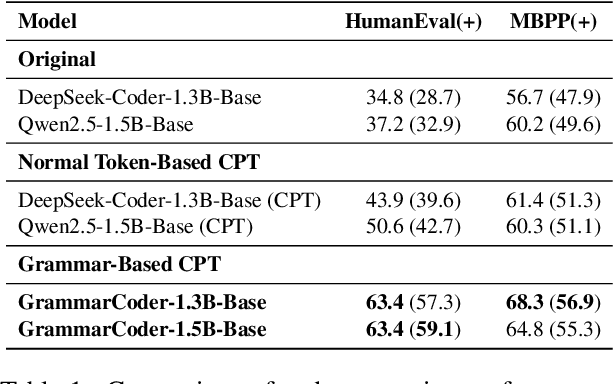
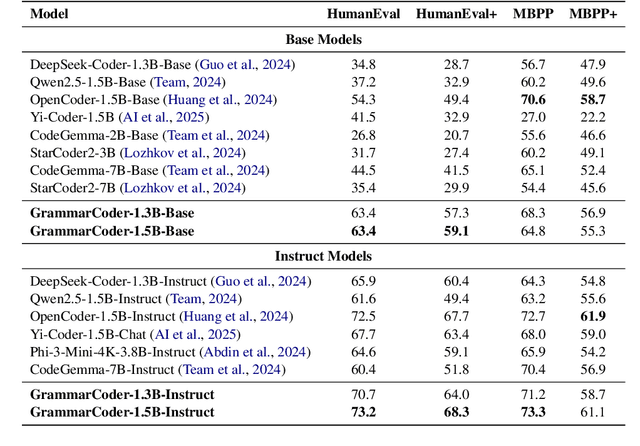
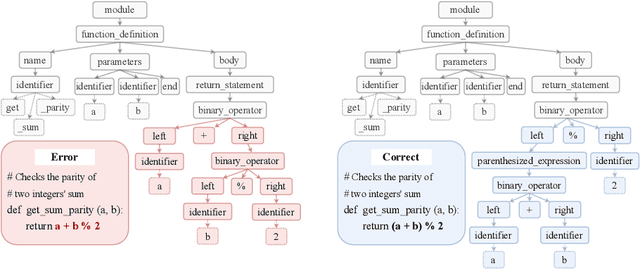
Grammar serves as a cornerstone in programming languages and software engineering, providing frameworks to define the syntactic space and program structure. Existing research demonstrates the effectiveness of grammar-based code representations in small-scale models, showing their ability to reduce syntax errors and enhance performance. However, as language models scale to the billion level or beyond, syntax-level errors become rare, making it unclear whether grammar information still provides performance benefits. To explore this, we develop a series of billion-scale GrammarCoder models, incorporating grammar rules in the code generation process. Experiments on HumanEval (+) and MBPP (+) demonstrate a notable improvement in code generation accuracy. Further analysis shows that grammar-based representations enhance LLMs' ability to discern subtle code differences, reducing semantic errors caused by minor variations. These findings suggest that grammar-based code representations remain valuable even in billion-scale models, not only by maintaining syntax correctness but also by improving semantic differentiation.
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Jan 26, 2024



The rapid development of large language models has revolutionized code intelligence in software development. However, the predominance of closed-source models has restricted extensive research and development. To address this, we introduce the DeepSeek-Coder series, a range of open-source code models with sizes from 1.3B to 33B, trained from scratch on 2 trillion tokens. These models are pre-trained on a high-quality project-level code corpus and employ a fill-in-the-blank task with a 16K window to enhance code generation and infilling. Our extensive evaluations demonstrate that DeepSeek-Coder not only achieves state-of-the-art performance among open-source code models across multiple benchmarks but also surpasses existing closed-source models like Codex and GPT-3.5. Furthermore, DeepSeek-Coder models are under a permissive license that allows for both research and unrestricted commercial use.
Reliability Assurance for Deep Neural Network Architectures Against Numerical Defects
Feb 13, 2023With the widespread deployment of deep neural networks (DNNs), ensuring the reliability of DNN-based systems is of great importance. Serious reliability issues such as system failures can be caused by numerical defects, one of the most frequent defects in DNNs. To assure high reliability against numerical defects, in this paper, we propose the RANUM approach including novel techniques for three reliability assurance tasks: detection of potential numerical defects, confirmation of potential-defect feasibility, and suggestion of defect fixes. To the best of our knowledge, RANUM is the first approach that confirms potential-defect feasibility with failure-exhibiting tests and suggests fixes automatically. Extensive experiments on the benchmarks of 63 real-world DNN architectures show that RANUM outperforms state-of-the-art approaches across the three reliability assurance tasks. In addition, when the RANUM-generated fixes are compared with developers' fixes on open-source projects, in 37 out of 40 cases, RANUM-generated fixes are equivalent to or even better than human fixes.
Lyra: A Benchmark for Turducken-Style Code Generation
Aug 27, 2021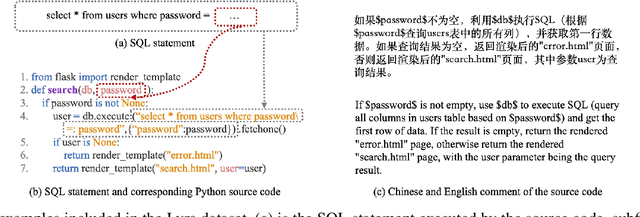
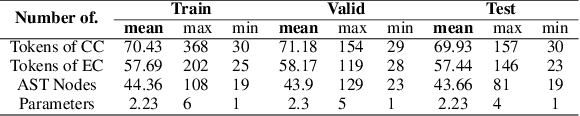
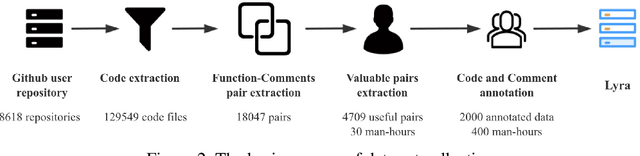
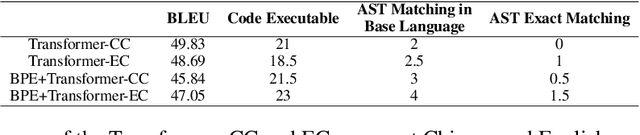
Code generation is crucial to reduce manual software development efforts. Recently, neural techniques have been used to generate source code automatically. While promising, these approaches are evaluated on tasks for generating code in single programming languages. However, in actual development, one programming language is often embedded in another. For example, SQL statements are often embedded as strings in base programming languages such as Python and Java, and JavaScript programs are often embedded in sever-side programming languages, such as PHP, Java, and Python. We call this a turducken-style programming. In this paper, we define a new code generation task: given a natural language comment, this task aims to generate a program in a base language with an embedded language. To our knowledge, this is the first turducken-style code generation task. For this task, we present Lyra: a dataset in Python with embedded SQL. This dataset contains 2,000 carefully annotated database manipulation programs from real usage projects. Each program is paired with both a Chinese comment and an English comment. In our experiment, we adopted Transformer, a state-of-the-art technique, as the baseline. In the best setting, Transformer achieves 0.5% and 1.5% AST exact matching accuracy using Chinese and English comments, respectively. Therefore, we believe that Lyra provides a new challenge for code generation.
Dynamic Labeling for Unlabeled Graph Neural Networks
Feb 23, 2021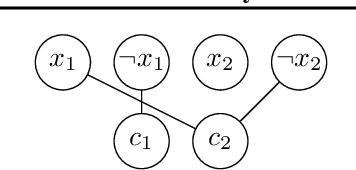
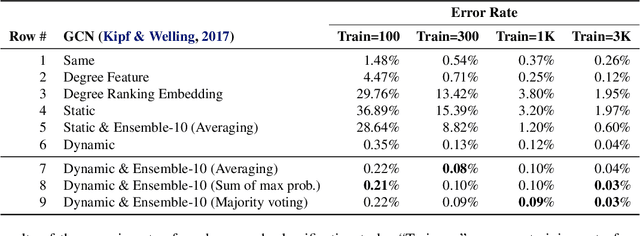
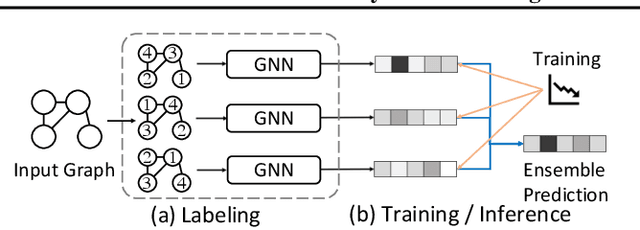
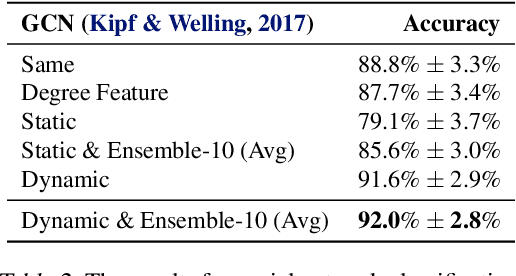
Existing graph neural networks (GNNs) largely rely on node embeddings, which represent a node as a vector by its identity, type, or content. However, graphs with unlabeled nodes widely exist in real-world applications (e.g., anonymized social networks). Previous GNNs either assign random labels to nodes (which introduces artefacts to the GNN) or assign one embedding to all nodes (which fails to distinguish one node from another). In this paper, we analyze the limitation of existing approaches in two types of classification tasks, graph classification and node classification. Inspired by our analysis, we propose two techniques, Dynamic Labeling and Preferential Dynamic Labeling, that satisfy desired properties statistically or asymptotically for each type of the task. Experimental results show that we achieve high performance in various graph-related tasks.
OCoR: An Overlapping-Aware Code Retriever
Aug 20, 2020
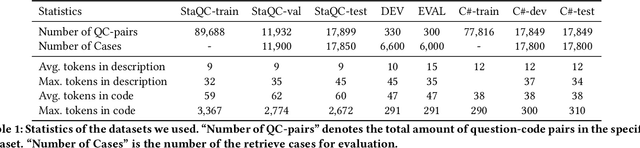
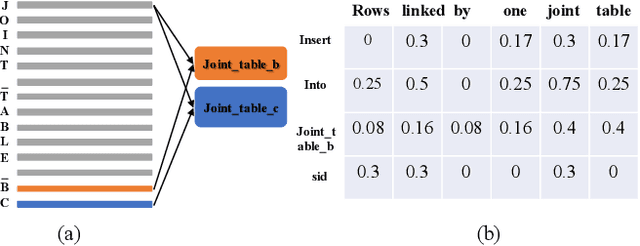
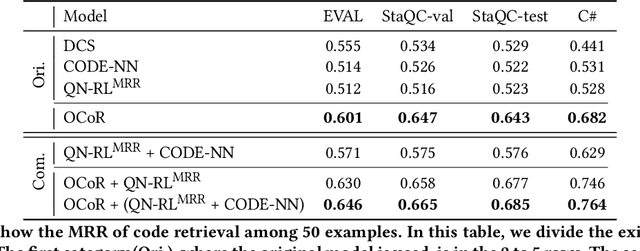
Code retrieval helps developers reuse the code snippet in the open-source projects. Given a natural language description, code retrieval aims to search for the most relevant code among a set of code. Existing state-of-the-art approaches apply neural networks to code retrieval. However, these approaches still fail to capture an important feature: overlaps. The overlaps between different names used by different people indicate that two different names may be potentially related (e.g., "message" and "msg"), and the overlaps between identifiers in code and words in natural language descriptions indicate that the code snippet and the description may potentially be related. To address these problems, we propose a novel neural architecture named OCoR, where we introduce two specifically-designed components to capture overlaps: the first embeds identifiers by character to capture the overlaps between identifiers, and the second introduces a novel overlap matrix to represent the degrees of overlaps between each natural language word and each identifier. The evaluation was conducted on two established datasets. The experimental results show that OCoR significantly outperforms the existing state-of-the-art approaches and achieves 13.1% to 22.3% improvements. Moreover, we also conducted several in-depth experiments to help understand the performance of different components in OCoR.
NLocalSAT: Boosting Local Search with Solution Prediction
Jan 26, 2020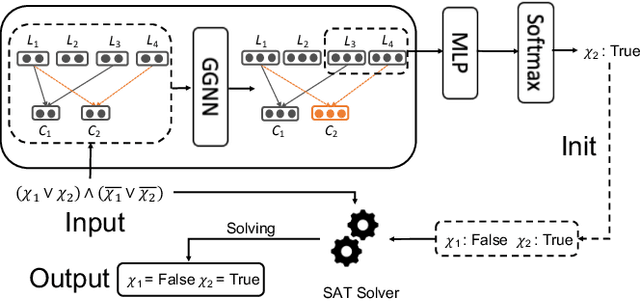
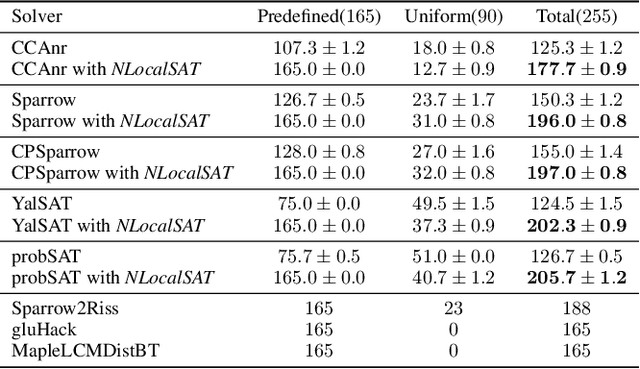
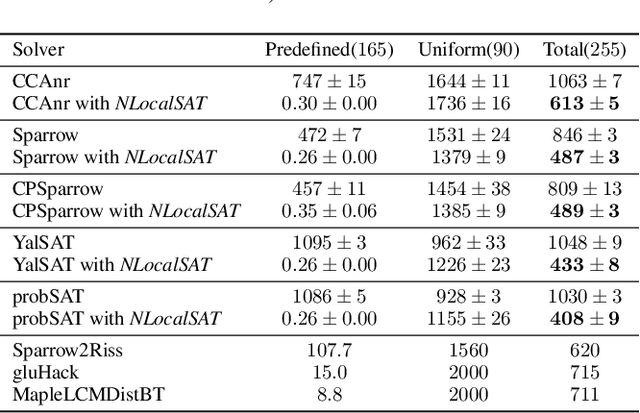
The boolean satisfiability problem is a famous NP-complete problem in computer science. An effective way for this problem is the stochastic local search (SLS). However, in this method, the initialization is assigned in a random manner, which impacts the effectiveness of SLS solvers. To address this problem, we propose NLocalSAT. NLocalSAT combines SLS with a solution prediction model, which boosts SLS by changing initialization assignments with a neural network. We evaluated NLocalSAT on five SLS solvers (CCAnr, Sparrow, CPSparrow, YalSAT, and probSAT) with problems in the random track of SAT Competition 2018. The experimental results show that solvers with NLocalSAT achieve 27%~62% improvement over the original SLS solvers.
TreeGen: A Tree-Based Transformer Architecture for Code Generation
Nov 28, 2019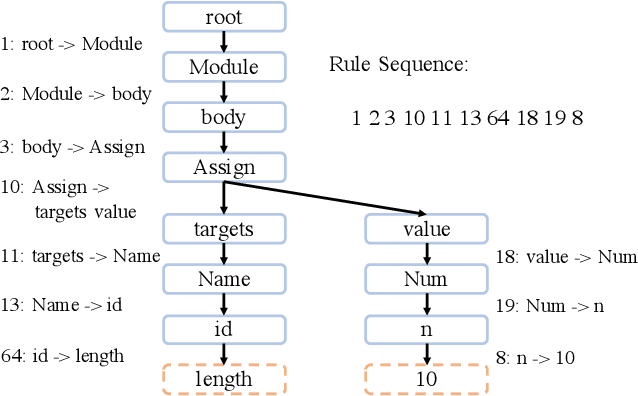
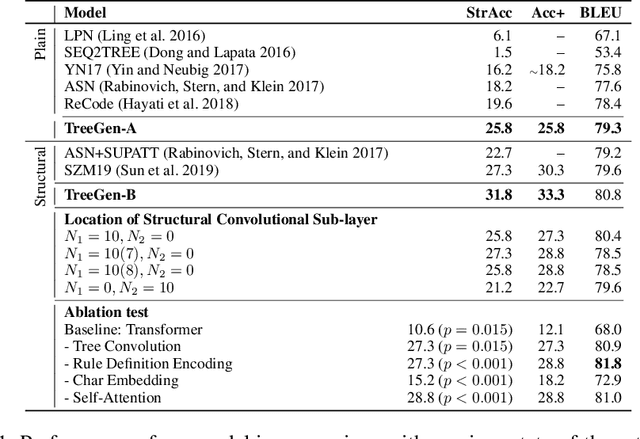

A code generation system generates programming language code based on an input natural language description. State-of-the-art approaches rely on neural networks for code generation. However, these code generators suffer from two problems. One is the long dependency problem, where a code element often depends on another far-away code element. A variable reference, for example, depends on its definition, which may appear quite a few lines before. The other problem is structure modeling, as programs contain rich structural information. In this paper, we propose a novel tree-based neural architecture, TreeGen, for code generation. TreeGen uses the attention mechanism of Transformers to alleviate the long-dependency problem, and introduces a novel AST reader (encoder) to incorporate grammar rules and AST structures into the network. We evaluated TreeGen on a Python benchmark, HearthStone, and two semantic parsing benchmarks, ATIS and GEO. TreeGen outperformed the previous state-of-the-art approach by 4.5 percentage points on HearthStone, and achieved the best accuracy among neural network-based approaches on ATIS (89.1%) and GEO (89.6%). We also conducted an ablation test to better understand each component of our model.
A Grammar-Based Structural CNN Decoder for Code Generation
Nov 14, 2018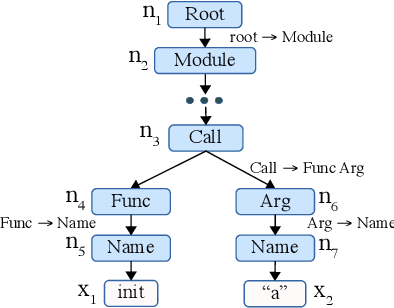

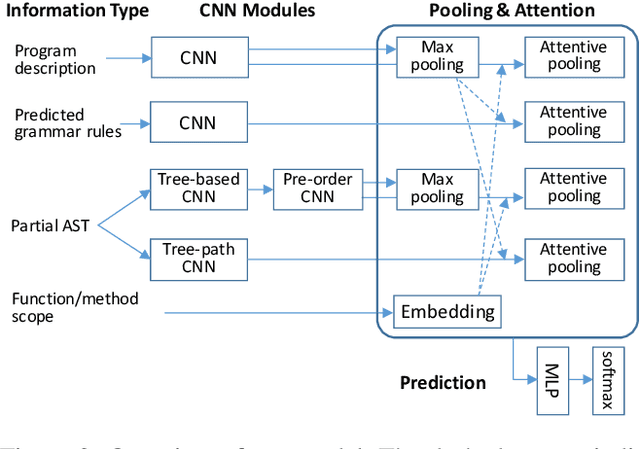

Code generation maps a program description to executable source code in a programming language. Existing approaches mainly rely on a recurrent neural network (RNN) as the decoder. However, we find that a program contains significantly more tokens than a natural language sentence, and thus it may be inappropriate for RNN to capture such a long sequence. In this paper, we propose a grammar-based structural convolutional neural network (CNN) for code generation. Our model generates a program by predicting the grammar rules of the programming language; we design several CNN modules, including the tree-based convolution and pre-order convolution, whose information is further aggregated by dedicated attentive pooling layers. Experimental results on the HearthStone benchmark dataset show that our CNN code generator significantly outperforms the previous state-of-the-art method by 5 percentage points; additional experiments on several semantic parsing tasks demonstrate the robustness of our model. We also conduct in-depth ablation test to better understand each component of our model.