 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Harness for Real-World Compilers
Mar 20, 2026Compilers are critical to modern computing, yet fixing compiler bugs is difficult. While recent large language model (LLM) advancements enable automated bug repair, compiler bugs pose unique challenges due to their complexity, deep cross-domain expertise requirements, and sparse, non-descriptive bug reports, necessitating compiler-specific tools. To bridge the gap, we introduce llvm-autofix, the first agentic harness designed to assist LLM agents in understanding and fixing compiler bugs. Our focus is on LLVM, one of the most widely used compiler infrastructures. Central to llvm-autofix are agent-friendly LLVM tools, a benchmark llvm-bench of reproducible LLVM bugs, and a tailored minimal agent llvm-autofix-mini for fixing LLVM bugs. Our evaluation demonstrates a performance decline of 60% in frontier models when tackling compiler bugs compared with common software bugs. Our minimal agent llvm-autofix-mini also outperforms the state-of-the-art by approximately 22%. This emphasizes the necessity for specialized harnesses like ours to close the loop between LLMs and compiler engineering. We believe this work establishes a foundation for advancing LLM capabilities in complex systems like compilers. GitHub: https://github.com/dtcxzyw/llvm-autofix
PyFi: Toward Pyramid-like Financial Image Understanding for VLMs via Adversarial Agents
Dec 11, 2025This paper proposes PyFi, a novel framework for pyramid-like financial image understanding that enables vision language models (VLMs) to reason through question chains in a progressive, simple-to-complex manner. At the core of PyFi is PyFi-600K, a dataset comprising 600K financial question-answer pairs organized into a reasoning pyramid: questions at the base require only basic perception, while those toward the apex demand increasing levels of capability in financial visual understanding and expertise. This data is scalable because it is synthesized without human annotations, using PyFi-adv, a multi-agent adversarial mechanism under the Monte Carlo Tree Search (MCTS) paradigm, in which, for each image, a challenger agent competes with a solver agent by generating question chains that progressively probe deeper capability levels in financial visual reasoning. Leveraging this dataset, we present fine-grained, hierarchical, and comprehensive evaluations of advanced VLMs in the financial domain. Moreover, fine-tuning Qwen2.5-VL-3B and Qwen2.5-VL-7B on the pyramid-structured question chains enables these models to answer complex financial questions by decomposing them into sub-questions with gradually increasing reasoning demands, yielding average accuracy improvements of 19.52% and 8.06%, respectively, on the dataset. All resources of code, dataset and models are available at: https://github.com/AgenticFinLab/PyFi .
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
OASIS: Order-Augmented Strategy for Improved Code Search
Mar 11, 2025



Code embeddings capture the semantic representations of code and are crucial for various code-related large language model (LLM) applications, such as code search. Previous training primarily relies on optimizing the InfoNCE loss by comparing positive natural language (NL)-code pairs with in-batch negatives. However, due to the sparse nature of code contexts, training solely by comparing the major differences between positive and negative pairs may fail to capture deeper semantic nuances. To address this issue, we propose a novel order-augmented strategy for improved code search (OASIS). It leverages order-based similarity labels to train models to capture subtle differences in similarity among negative pairs. Extensive benchmark evaluations demonstrate that our OASIS model significantly outperforms previous state-of-the-art models focusing solely on major positive-negative differences. It underscores the value of exploiting subtle differences among negative pairs with order labels for effective code embedding training.
Grammar-Based Code Representation: Is It a Worthy Pursuit for LLMs?
Mar 07, 2025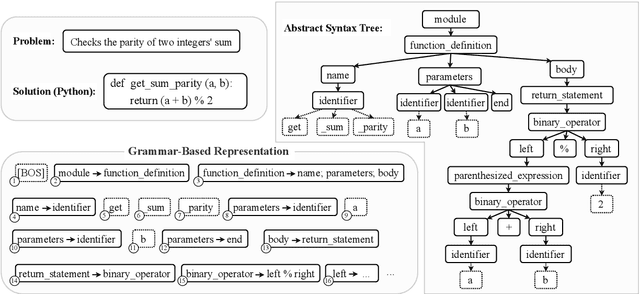
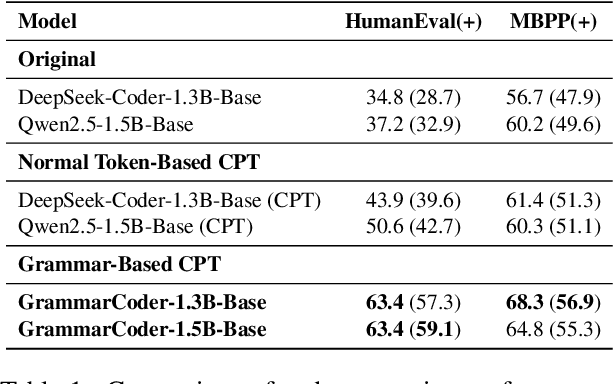
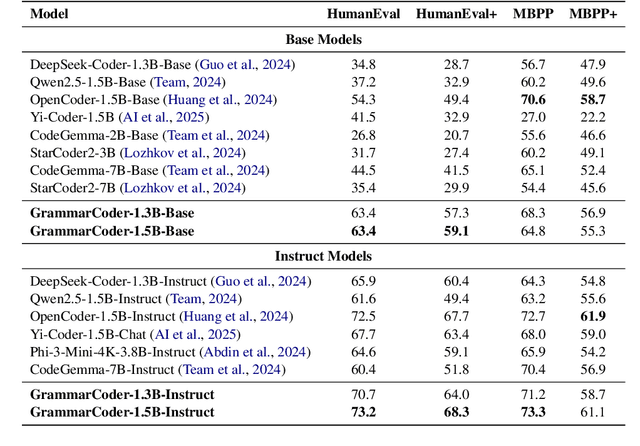
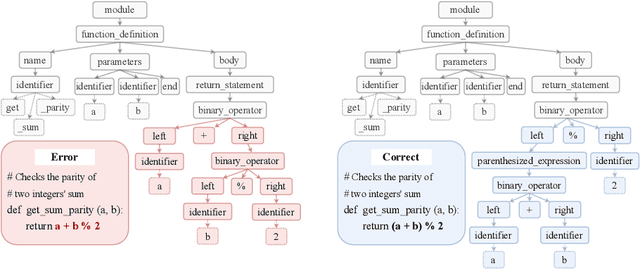
Grammar serves as a cornerstone in programming languages and software engineering, providing frameworks to define the syntactic space and program structure. Existing research demonstrates the effectiveness of grammar-based code representations in small-scale models, showing their ability to reduce syntax errors and enhance performance. However, as language models scale to the billion level or beyond, syntax-level errors become rare, making it unclear whether grammar information still provides performance benefits. To explore this, we develop a series of billion-scale GrammarCoder models, incorporating grammar rules in the code generation process. Experiments on HumanEval (+) and MBPP (+) demonstrate a notable improvement in code generation accuracy. Further analysis shows that grammar-based representations enhance LLMs' ability to discern subtle code differences, reducing semantic errors caused by minor variations. These findings suggest that grammar-based code representations remain valuable even in billion-scale models, not only by maintaining syntax correctness but also by improving semantic differentiation.
LLM4Decompile: Decompiling Binary Code with Large Language Models
Mar 08, 2024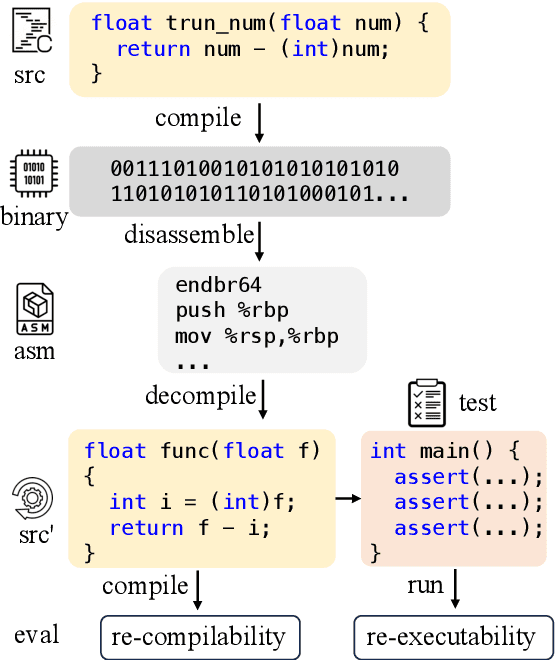

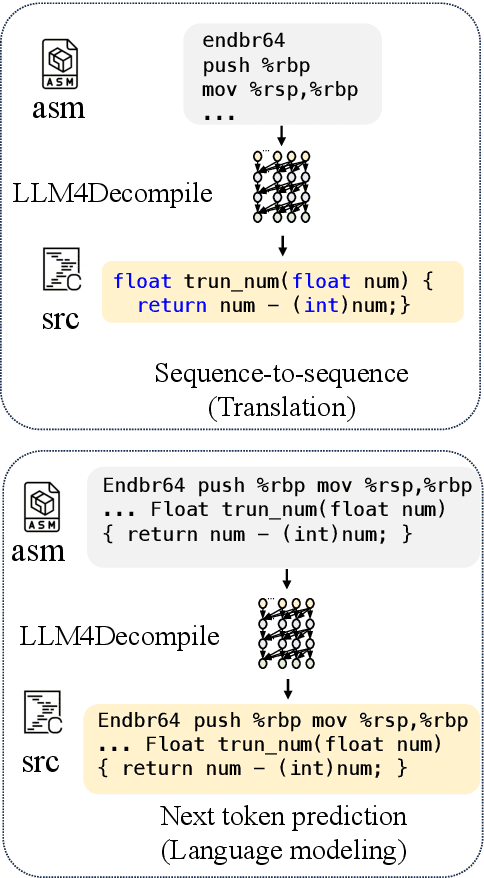

Decompilation aims to restore compiled code to human-readable source code, but struggles with details like names and structure. Large language models (LLMs) show promise for programming tasks, motivating their application to decompilation. However, there does not exist any open-source LLM for decompilation. Moreover, existing decompilation evaluation systems mainly consider token-level accuracy and largely ignore code executability, which is the most important feature of any program. Therefore, we release the first open-access decompilation LLMs ranging from 1B to 33B pre-trained on 4 billion tokens of C source code and the corresponding assembly code. The open-source LLMs can serve as baselines for further development in the field. To ensure practical program evaluation, we introduce Decompile-Eval, the first dataset that considers re-compilability and re-executability for decompilation. The benchmark emphasizes the importance of evaluating the decompilation model from the perspective of program semantics. Experiments indicate that our LLM4Decompile has demonstrated the capability to accurately decompile 21% of the assembly code, which achieves a 50% improvement over GPT-4. Our code, dataset, and models are released at https://github.com/albertan017/LLM4Decompile
HICL: Hashtag-Driven In-Context Learning for Social Media Natural Language Understanding
Aug 19, 2023
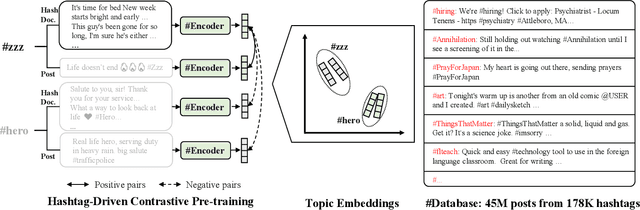
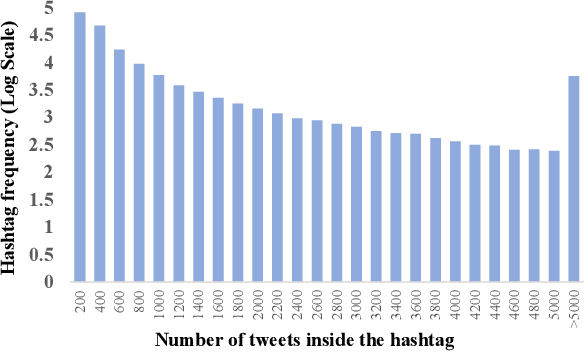
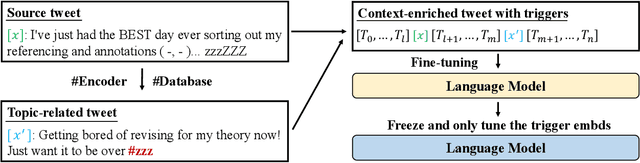
Natural language understanding (NLU) is integral to various social media applications. However, existing NLU models rely heavily on context for semantic learning, resulting in compromised performance when faced with short and noisy social media content. To address this issue, we leverage in-context learning (ICL), wherein language models learn to make inferences by conditioning on a handful of demonstrations to enrich the context and propose a novel hashtag-driven in-context learning (HICL) framework. Concretely, we pre-train a model #Encoder, which employs #hashtags (user-annotated topic labels) to drive BERT-based pre-training through contrastive learning. Our objective here is to enable #Encoder to gain the ability to incorporate topic-related semantic information, which allows it to retrieve topic-related posts to enrich contexts and enhance social media NLU with noisy contexts. To further integrate the retrieved context with the source text, we employ a gradient-based method to identify trigger terms useful in fusing information from both sources. For empirical studies, we collected 45M tweets to set up an in-context NLU benchmark, and the experimental results on seven downstream tasks show that HICL substantially advances the previous state-of-the-art results. Furthermore, we conducted extensive analyzes and found that: (1) combining source input with a top-retrieved post from #Encoder is more effective than using semantically similar posts; (2) trigger words can largely benefit in merging context from the source and retrieved posts.
DeepBillboard: Systematic Physical-World Testing of Autonomous Driving Systems
Dec 27, 2018
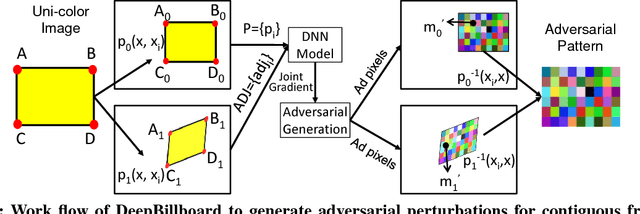

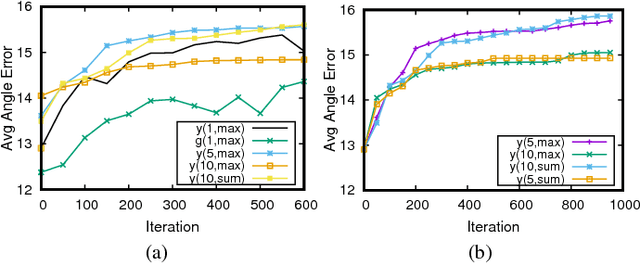
Deep Neural Networks (DNNs) have been widely applied in many autonomous systems such as autonomous driving. Recently, DNN testing has been intensively studied to automatically generate adversarial examples, which inject small-magnitude perturbations into inputs to test DNNs under extreme situations. While existing testing techniques prove to be effective, they mostly focus on generating digital adversarial perturbations (particularly for autonomous driving), e.g., changing image pixels, which may never happen in physical world. There is a critical missing piece in the literature on autonomous driving testing: understanding and exploiting both digital and physical adversarial perturbation generation for impacting steering decisions. In this paper, we present DeepBillboard, a systematic physical-world testing approach targeting at a common and practical driving scenario: drive-by billboards. DeepBillboard is capable of generating a robust and resilient printable adversarial billboard, which works under dynamic changing driving conditions including viewing angle, distance, and lighting. The objective is to maximize the possibility, degree, and duration of the steering-angle errors of an autonomous vehicle driving by the generated adversarial billboard. We have extensively evaluated the efficacy and robustness of DeepBillboard through conducting both digital and physical-world experiments. Results show that DeepBillboard is effective for various steering models and scenes. Furthermore, DeepBillboard is sufficiently robust and resilient for generating physical-world adversarial billboard tests for real-world driving under various weather conditions. To the best of our knowledge, this is the first study demonstrating the possibility of generating realistic and continuous physical-world tests for practical autonomous driving systems.