 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Decompile: Decompiling Binary Code with Large Language Models
Mar 08, 2024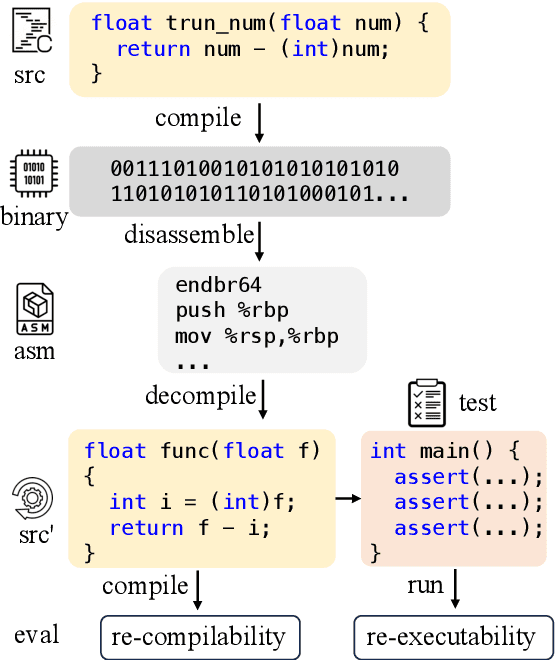

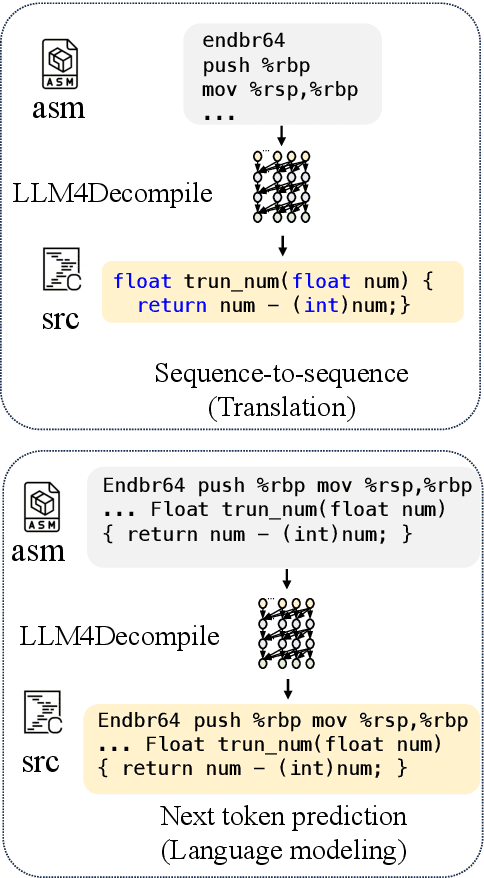

Decompilation aims to restore compiled code to human-readable source code, but struggles with details like names and structure. Large language models (LLMs) show promise for programming tasks, motivating their application to decompilation. However, there does not exist any open-source LLM for decompilation. Moreover, existing decompilation evaluation systems mainly consider token-level accuracy and largely ignore code executability, which is the most important feature of any program. Therefore, we release the first open-access decompilation LLMs ranging from 1B to 33B pre-trained on 4 billion tokens of C source code and the corresponding assembly code. The open-source LLMs can serve as baselines for further development in the field. To ensure practical program evaluation, we introduce Decompile-Eval, the first dataset that considers re-compilability and re-executability for decompilation. The benchmark emphasizes the importance of evaluating the decompilation model from the perspective of program semantics. Experiments indicate that our LLM4Decompile has demonstrated the capability to accurately decompile 21% of the assembly code, which achieves a 50% improvement over GPT-4. Our code, dataset, and models are released at https://github.com/albertan017/LLM4Decompile
HICL: Hashtag-Driven In-Context Learning for Social Media Natural Language Understanding
Aug 19, 2023
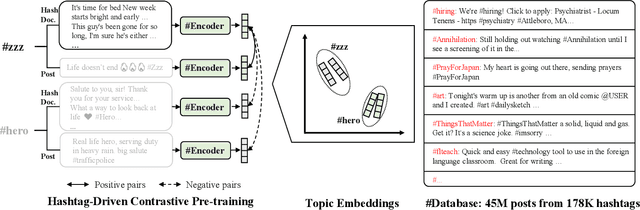
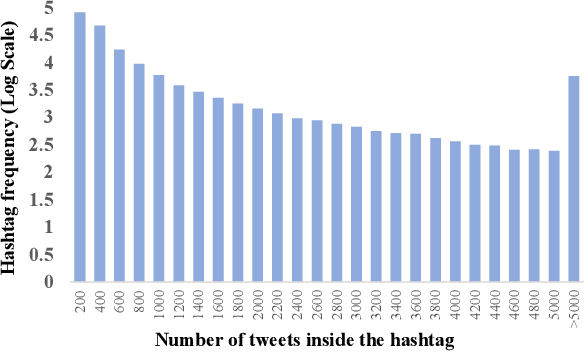
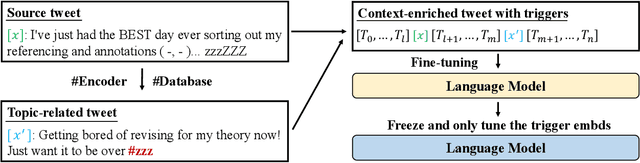
Natural language understanding (NLU) is integral to various social media applications. However, existing NLU models rely heavily on context for semantic learning, resulting in compromised performance when faced with short and noisy social media content. To address this issue, we leverage in-context learning (ICL), wherein language models learn to make inferences by conditioning on a handful of demonstrations to enrich the context and propose a novel hashtag-driven in-context learning (HICL) framework. Concretely, we pre-train a model #Encoder, which employs #hashtags (user-annotated topic labels) to drive BERT-based pre-training through contrastive learning. Our objective here is to enable #Encoder to gain the ability to incorporate topic-related semantic information, which allows it to retrieve topic-related posts to enrich contexts and enhance social media NLU with noisy contexts. To further integrate the retrieved context with the source text, we employ a gradient-based method to identify trigger terms useful in fusing information from both sources. For empirical studies, we collected 45M tweets to set up an in-context NLU benchmark, and the experimental results on seven downstream tasks show that HICL substantially advances the previous state-of-the-art results. Furthermore, we conducted extensive analyzes and found that: (1) combining source input with a top-retrieved post from #Encoder is more effective than using semantically similar posts; (2) trigger words can largely benefit in merging context from the source and retrieved posts.
Understanding Social Media Cross-Modality Discourse in Linguistic Space
Feb 26, 2023The multimedia communications with texts and images are popular on social media. However, limited studies concern how images are structured with texts to form coherent meanings in human cognition. To fill in the gap, we present a novel concept of cross-modality discourse, reflecting how human readers couple image and text understandings. Text descriptions are first derived from images (named as subtitles) in the multimedia contexts. Five labels -- entity-level insertion, projection and concretization and scene-level restatement and extension -- are further employed to shape the structure of subtitles and texts and present their joint meanings. As a pilot study, we also build the very first dataset containing 16K multimedia tweets with manually annotated discourse labels. The experimental results show that the multimedia encoder based on multi-head attention with captions is able to obtain the-state-of-the-art results.