 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeSim: Toward Free-viewpoint Camera Simulation in Driving Scenes
Dec 04, 2024



We propose FreeSim, a camera simulation method for autonomous driving. FreeSim emphasizes high-quality rendering from viewpoints beyond the recorded ego trajectories. In such viewpoints, previous methods have unacceptable degradation because the training data of these viewpoints is unavailable. To address such data scarcity, we first propose a generative enhancement model with a matched data construction strategy. The resulting model can generate high-quality images in a viewpoint slightly deviated from the recorded trajectories, conditioned on the degraded rendering of this viewpoint. We then propose a progressive reconstruction strategy, which progressively adds generated images of unrecorded views into the reconstruction process, starting from slightly off-trajectory viewpoints and moving progressively farther away. With this progressive generation-reconstruction pipeline, FreeSim supports high-quality off-trajectory view synthesis under large deviations of more than 3 meters.
FreeVS: Generative View Synthesis on Free Driving Trajectory
Oct 23, 2024



Existing reconstruction-based novel view synthesis methods for driving scenes focus on synthesizing camera views along the recorded trajectory of the ego vehicle. Their image rendering performance will severely degrade on viewpoints falling out of the recorded trajectory, where camera rays are untrained. We propose FreeVS, a novel fully generative approach that can synthesize camera views on free new trajectories in real driving scenes. To control the generation results to be 3D consistent with the real scenes and accurate in viewpoint pose, we propose the pseudo-image representation of view priors to control the generation process. Viewpoint transformation simulation is applied on pseudo-images to simulate camera movement in each direction. Once trained, FreeVS can be applied to any validation sequences without reconstruction process and synthesis views on novel trajectories. Moreover, we propose two new challenging benchmarks tailored to driving scenes, which are novel camera synthesis and novel trajectory synthesis, emphasizing the freedom of viewpoints. Given that no ground truth images are available on novel trajectories, we also propose to evaluate the consistency of images synthesized on novel trajectories with 3D perception models. Experiments on the Waymo Open Dataset show that FreeVS has a strong image synthesis performance on both the recorded trajectories and novel trajectories. Project Page: https://freevs24.github.io/
DrivingDojo Dataset: Advancing Interactive and Knowledge-Enriched Driving World Model
Oct 14, 2024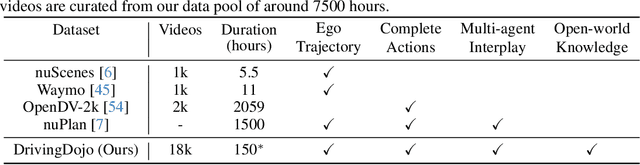
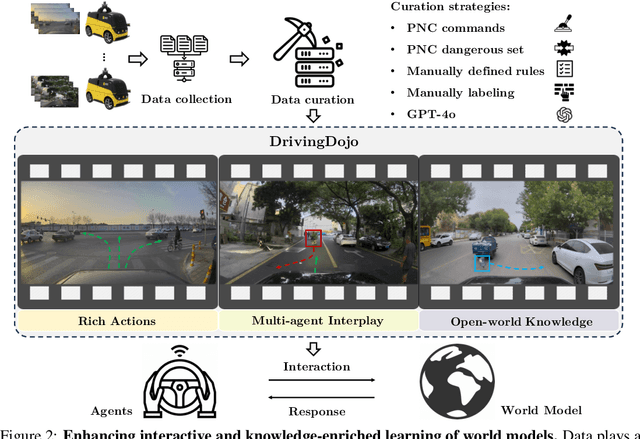

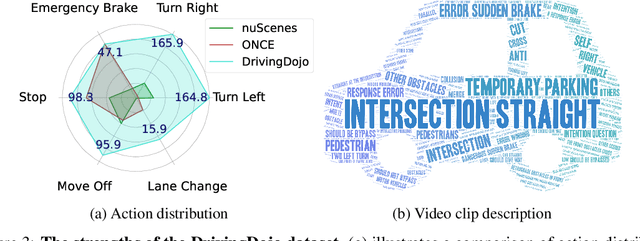
Driving world models have gained increasing attention due to their ability to model complex physical dynamics. However, their superb modeling capability is yet to be fully unleashed due to the limited video diversity in current driving datasets. We introduce DrivingDojo, the first dataset tailor-made for training interactive world models with complex driving dynamics. Our dataset features video clips with a complete set of driving maneuvers, diverse multi-agent interplay, and rich open-world driving knowledge, laying a stepping stone for future world model development. We further define an action instruction following (AIF) benchmark for world models and demonstrate the superiority of the proposed dataset for generating action-controlled future predictions.
Immortal Tracker: Tracklet Never Dies
Nov 26, 2021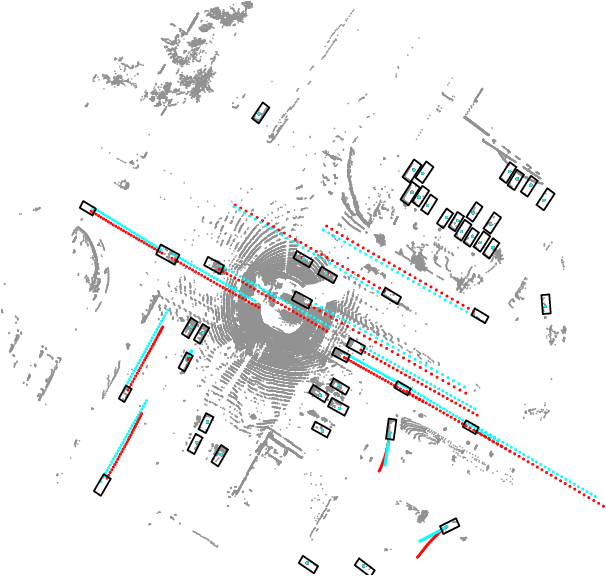

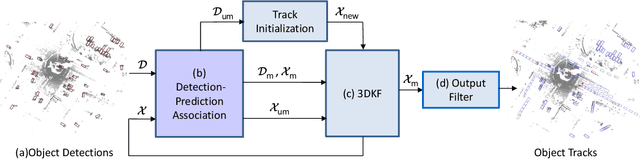
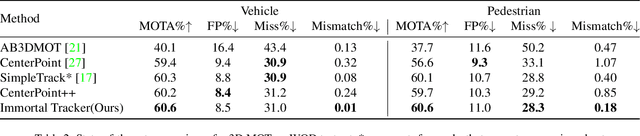
Previous online 3D Multi-Object Tracking(3DMOT) methods terminate a tracklet when it is not associated with new detections for a few frames. But if an object just goes dark, like being temporarily occluded by other objects or simply getting out of FOV, terminating a tracklet prematurely will result in an identity switch. We reveal that premature tracklet termination is the main cause of identity switches in modern 3DMOT systems. To address this, we propose Immortal Tracker, a simple tracking system that utilizes trajectory prediction to maintain tracklets for objects gone dark. We employ a simple Kalman filter for trajectory prediction and preserve the tracklet by prediction when the target is not visible. With this method, we can avoid 96% vehicle identity switches resulting from premature tracklet termination. Without any learned parameters, our method achieves a mismatch ratio at the 0.0001 level and competitive MOTA for the vehicle class on the Waymo Open Dataset test set. Our mismatch ratio is tens of times lower than any previously published method. Similar results are reported on nuScenes. We believe the proposed Immortal Tracker can offer a simple yet powerful solution for pushing the limit of 3DMOT. Our code is available at https://github.com/ImmortalTracker/ImmortalTracker.