 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOP-ReID: Multi-spectral Object Re-Identification with Token Permutation
Dec 15, 2023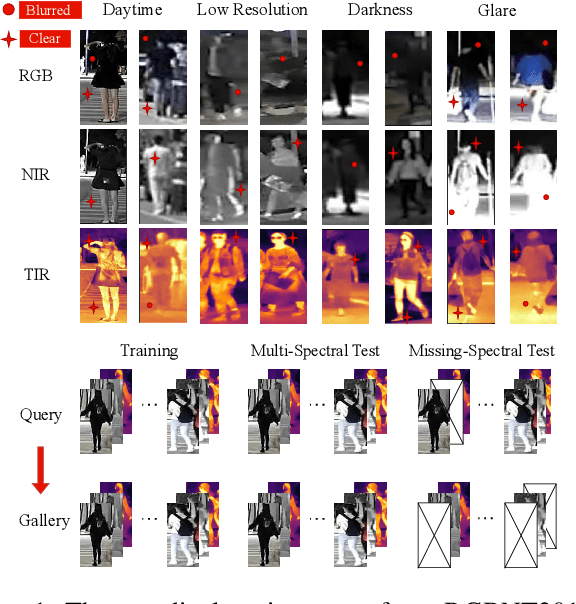
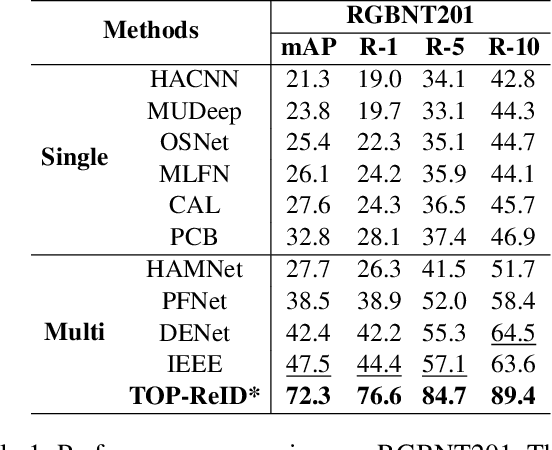
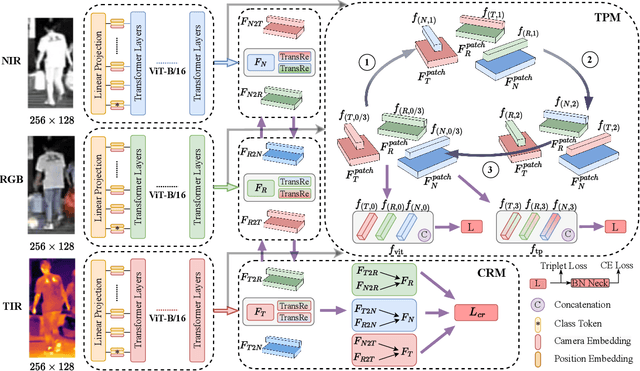
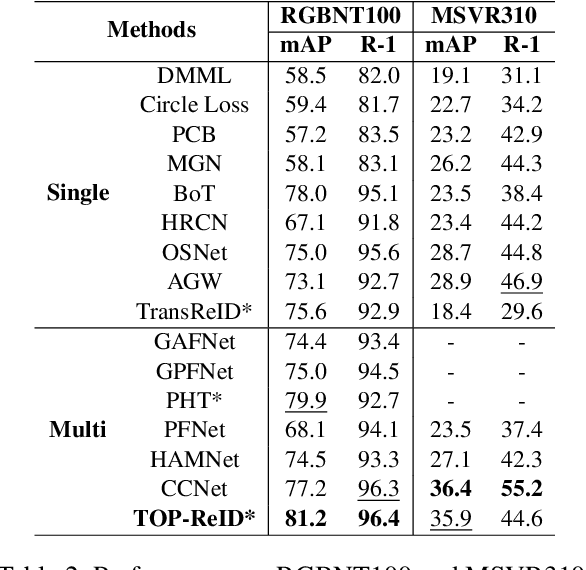
Multi-spectral object Re-identification (ReID) aims to retrieve specific objects by leveraging complementary information from different image spectra. It delivers great advantages over traditional single-spectral ReID in complex visual environment. However, the significant distribution gap among different image spectra poses great challenges for effective multi-spectral feature representations. In addition, most of current Transformer-based ReID methods only utilize the global feature of class tokens to achieve the holistic retrieval, ignoring the local discriminative ones. To address the above issues, we step further to utilize all the tokens of Transformers and propose a cyclic token permutation framework for multi-spectral object ReID, dubbled TOP-ReID. More specifically, we first deploy a multi-stream deep network based on vision Transformers to preserve distinct information from different image spectra. Then, we propose a Token Permutation Module (TPM) for cyclic multi-spectral feature aggregation. It not only facilitates the spatial feature alignment across different image spectra, but also allows the class token of each spectrum to perceive the local details of other spectra. Meanwhile, we propose a Complementary Reconstruction Module (CRM), which introduces dense token-level reconstruction constraints to reduce the distribution gap across different image spectra. With the above modules, our proposed framework can generate more discriminative multi-spectral features for robust object ReID. Extensive experiments on three ReID benchmarks (i.e., RGBNT201, RGBNT100 and MSVR310) verify the effectiveness of our methods. The code is available at https://github.com/924973292/TOP-ReID.
Multi-scale Semantic Correlation Mining for Visible-Infrared Person Re-Identification
Nov 24, 2023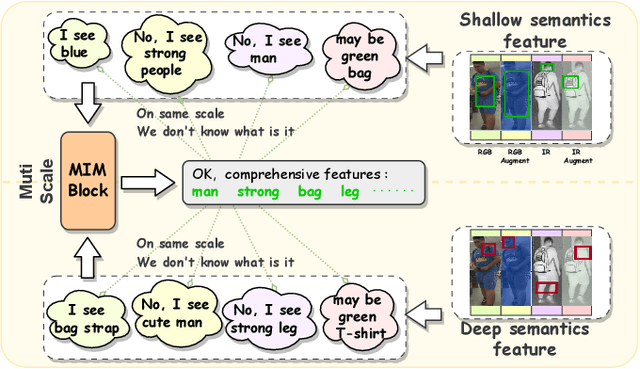
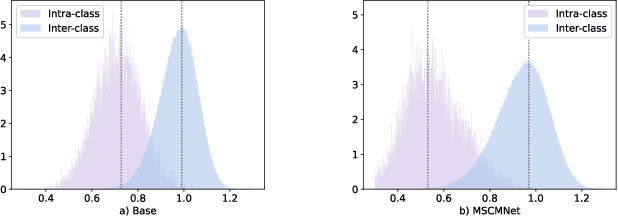
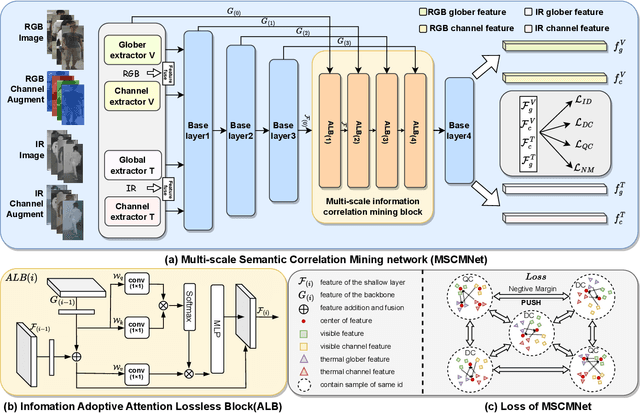
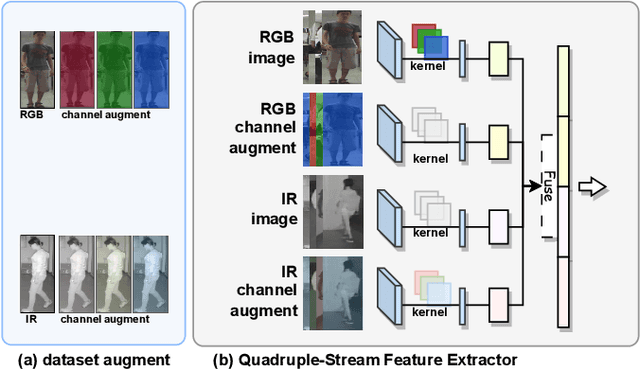
The main challenge in the Visible-Infrared Person Re-Identification (VI-ReID) task lies in how to extract discriminative features from different modalities for matching purposes. While the existing well works primarily focus on minimizing the modal discrepancies, the modality information can not thoroughly be leveraged. To solve this problem, a Multi-scale Semantic Correlation Mining network (MSCMNet) is proposed to comprehensively exploit semantic features at multiple scales and simultaneously reduce modality information loss as small as possible in feature extraction. The proposed network contains three novel components. Firstly, after taking into account the effective utilization of modality information, the Multi-scale Information Correlation Mining Block (MIMB) is designed to explore semantic correlations across multiple scales. Secondly, in order to enrich the semantic information that MIMB can utilize, a quadruple-stream feature extractor (QFE) with non-shared parameters is specifically designed to extract information from different dimensions of the dataset. Finally, the Quadruple Center Triplet Loss (QCT) is further proposed to address the information discrepancy in the comprehensive features. Extensive experiments on the SYSU-MM01, RegDB, and LLCM datasets demonstrate that the proposed MSCMNet achieves the greatest accuracy.
Learning Progressive Modality-shared Transformers for Effective Visible-Infrared Person Re-identification
Dec 01, 2022
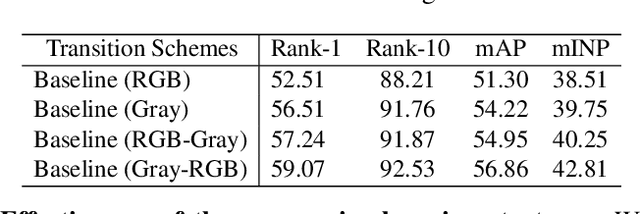
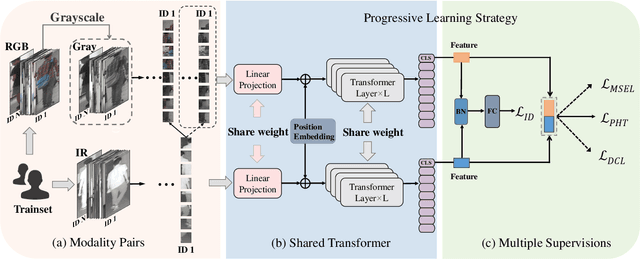
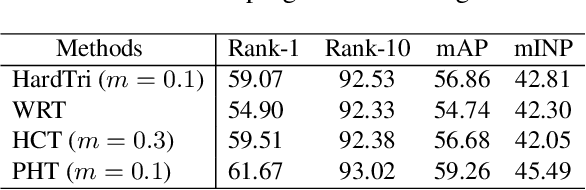
Visible-Infrared Person Re-Identification (VI-ReID) is a challenging retrieval task under complex modality changes. Existing methods usually focus on extracting discriminative visual features while ignoring the reliability and commonality of visual features between different modalities. In this paper, we propose a novel deep learning framework named Progressive Modality-shared Transformer (PMT) for effective VI-ReID. To reduce the negative effect of modality gaps, we first take the gray-scale images as an auxiliary modality and propose a progressive learning strategy. Then, we propose a Modality-Shared Enhancement Loss (MSEL) to guide the model to explore more reliable identity information from modality-shared features. Finally, to cope with the problem of large intra-class differences and small inter-class differences, we propose a Discriminative Center Loss (DCL) combined with the MSEL to further improve the discrimination of reliable features. Extensive experiments on SYSU-MM01 and RegDB datasets show that our proposed framework performs better than most state-of-the-art methods. For model reproduction, we release the source code at https://github.com/hulu88/PMT.
Planar Object Tracking in the Wild: A Benchmark
May 22, 2018



Planar object tracking is an actively studied problem in vision-based robotic applications. While several benchmarks have been constructed for evaluating state-of-the-art algorithms, there is a lack of video sequences captured in the wild rather than in constrained laboratory environment. In this paper, we present a carefully designed planar object tracking benchmark containing 210 videos of 30 planar objects sampled in the natural environment. In particular, for each object, we shoot seven videos involving various challenging factors, namely scale change, rotation, perspective distortion, motion blur, occlusion, out-of-view, and unconstrained. The ground truth is carefully annotated semi-manually to ensure the quality. Moreover, eleven state-of-the-art algorithms are evaluated on the benchmark using two evaluation metrics, with detailed analysis provided for the evaluation results. We expect the proposed benchmark to benefit future studies on planar object tracking.