 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Spatio-temporal Graph Learning for Alignment-free RGBT Video Object Detection
Apr 16, 2025
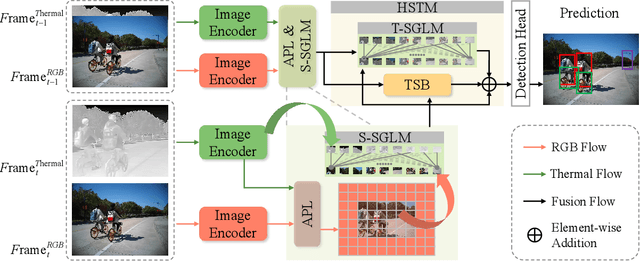
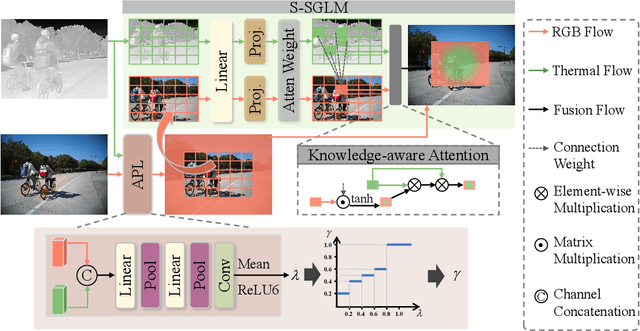
RGB-Thermal Video Object Detection (RGBT VOD) can address the limitation of traditional RGB-based VOD in challenging lighting conditions, making it more practical and effective in many applications. However, similar to most RGBT fusion tasks, it still mainly relies on manually aligned multimodal image pairs. In this paper, we propose a novel Multimodal Spatio-temporal Graph learning Network (MSGNet) for alignment-free RGBT VOD problem by leveraging the robust graph representation learning model. Specifically, we first design an Adaptive Partitioning Layer (APL) to estimate the corresponding regions of the Thermal image within the RGB image (high-resolution), achieving a preliminary inexact alignment. Then, we introduce the Spatial Sparse Graph Learning Module (S-SGLM) which employs a sparse information passing mechanism on the estimated inexact alignment to achieve reliable information interaction between different modalities. Moreover, to fully exploit the temporal cues for RGBT VOD problem, we introduce Hybrid Structured Temporal Modeling (HSTM), which involves a Temporal Sparse Graph Learning Module (T-SGLM) and Temporal Star Block (TSB). T-SGLM aims to filter out some redundant information between adjacent frames by employing the sparse aggregation mechanism on the temporal graph. Meanwhile, TSB is dedicated to achieving the complementary learning of local spatial relationships. Extensive comparative experiments conducted on both the aligned dataset VT-VOD50 and the unaligned dataset UVT-VOD2024 demonstrate the effectiveness and superiority of our proposed method. Our project will be made available on our website for free public access.
Unity is Strength: Unifying Convolutional and Transformeral Features for Better Person Re-Identification
Dec 23, 2024Person Re-identification (ReID) aims to retrieve the specific person across non-overlapping cameras, which greatly helps intelligent transportation systems. As we all know, Convolutional Neural Networks (CNNs) and Transformers have the unique strengths to extract local and global features, respectively. Considering this fact, we focus on the mutual fusion between them to learn more comprehensive representations for persons. In particular, we utilize the complementary integration of deep features from different model structures. We propose a novel fusion framework called FusionReID to unify the strengths of CNNs and Transformers for image-based person ReID. More specifically, we first deploy a Dual-branch Feature Extraction (DFE) to extract features through CNNs and Transformers from a single image. Moreover, we design a novel Dual-attention Mutual Fusion (DMF) to achieve sufficient feature fusions. The DMF comprises Local Refinement Units (LRU) and Heterogenous Transmission Modules (HTM). LRU utilizes depth-separable convolutions to align deep features in channel dimensions and spatial sizes. HTM consists of a Shared Encoding Unit (SEU) and two Mutual Fusion Units (MFU). Through the continuous stacking of HTM, deep features after LRU are repeatedly utilized to generate more discriminative features. Extensive experiments on three public ReID benchmarks demonstrate that our method can attain superior performances than most state-of-the-arts. The source code is available at https://github.com/924973292/FusionReID.
Alignment-Free RGB-T Salient Object Detection: A Large-scale Dataset and Progressive Correlation Network
Dec 19, 2024



Alignment-free RGB-Thermal (RGB-T) salient object detection (SOD) aims to achieve robust performance in complex scenes by directly leveraging the complementary information from unaligned visible-thermal image pairs, without requiring manual alignment. However, the labor-intensive process of collecting and annotating image pairs limits the scale of existing benchmarks, hindering the advancement of alignment-free RGB-T SOD. In this paper, we construct a large-scale and high-diversity unaligned RGB-T SOD dataset named UVT20K, comprising 20,000 image pairs, 407 scenes, and 1256 object categories. All samples are collected from real-world scenarios with various challenges, such as low illumination, image clutter, complex salient objects, and so on. To support the exploration for further research, each sample in UVT20K is annotated with a comprehensive set of ground truths, including saliency masks, scribbles, boundaries, and challenge attributes. In addition, we propose a Progressive Correlation Network (PCNet), which models inter- and intra-modal correlations on the basis of explicit alignment to achieve accurate predictions in unaligned image pairs. Extensive experiments conducted on unaligned and aligned datasets demonstrate the effectiveness of our method.Code and dataset are available at https://github.com/Angknpng/PCNet.
LFSamba: Marry SAM with Mamba for Light Field Salient Object Detection
Nov 11, 2024



A light field camera can reconstruct 3D scenes using captured multi-focus images that contain rich spatial geometric information, enhancing applications in stereoscopic photography, virtual reality, and robotic vision. In this work, a state-of-the-art salient object detection model for multi-focus light field images, called LFSamba, is introduced to emphasize four main insights: (a) Efficient feature extraction, where SAM is used to extract modality-aware discriminative features; (b) Inter-slice relation modeling, leveraging Mamba to capture long-range dependencies across multiple focal slices, thus extracting implicit depth cues; (c) Inter-modal relation modeling, utilizing Mamba to integrate all-focus and multi-focus images, enabling mutual enhancement; (d) Weakly supervised learning capability, developing a scribble annotation dataset from an existing pixel-level mask dataset, establishing the first scribble-supervised baseline for light field salient object detection.https://github.com/liuzywen/LFScribble
Unveiling the Limits of Alignment: Multi-modal Dynamic Local Fusion Network and A Benchmark for Unaligned RGBT Video Object Detection
Oct 16, 2024



Current RGB-Thermal Video Object Detection (RGBT VOD) methods still depend on manually aligning data at the image level, which hampers its practical application in real-world scenarios since image pairs captured by multispectral sensors often differ in both fields of view and resolution. To address this limitation, we propose a Multi-modal Dynamic Local fusion Network (MDLNet) designed to handle unaligned RGBT image pairs. Specifically, our proposed Multi-modal Dynamic Local Fusion (MDLF) module includes a set of predefined boxes, each enhanced with random Gaussian noise to generate a dynamic box. Each box selects a local region from the original high-resolution RGB image. This region is then fused with the corresponding information from another modality and reinserted into the RGB. This method adapts to various data alignment scenarios by interacting with local features across different ranges. Simultaneously, we introduce a Cascaded Temporal Scrambler (CTS) within an end-to-end architecture. This module leverages consistent spatiotemporal information from consecutive frames to enhance the representation capability of the current frame while maintaining network efficiency. We have curated an open dataset called UVT-VOD2024 for unaligned RGBT VOD. It consists of 30,494 pairs of unaligned RGBT images captured directly from a multispectral camera. We conduct a comprehensive evaluation and comparison with MDLNet and state-of-the-art (SOTA) models, demonstrating the superior effectiveness of MDLNet. We will release our code and UVT-VOD2024 to the public for further research.
Adapting Segment Anything Model to Multi-modal Salient Object Detection with Semantic Feature Fusion Guidance
Aug 27, 2024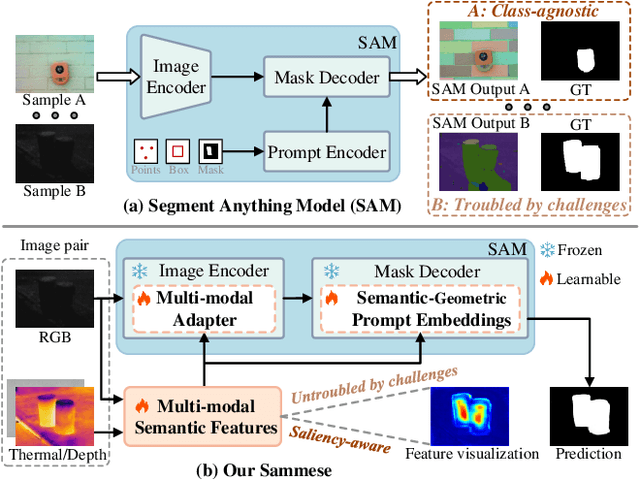
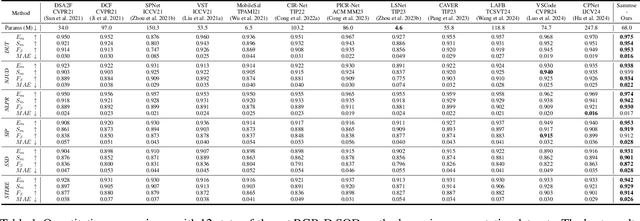
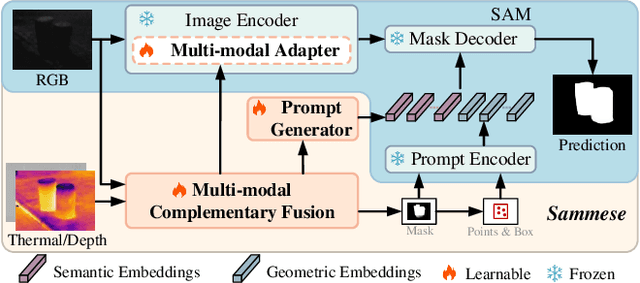

Although most existing multi-modal salient object detection (SOD) methods demonstrate effectiveness through training models from scratch, the limited multi-modal data hinders these methods from reaching optimality. In this paper, we propose a novel framework to explore and exploit the powerful feature representation and zero-shot generalization ability of the pre-trained Segment Anything Model (SAM) for multi-modal SOD. Despite serving as a recent vision fundamental model, driving the class-agnostic SAM to comprehend and detect salient objects accurately is non-trivial, especially in challenging scenes. To this end, we develop \underline{SAM} with se\underline{m}antic f\underline{e}ature fu\underline{s}ion guidanc\underline{e} (Sammese), which incorporates multi-modal saliency-specific knowledge into SAM to adapt SAM to multi-modal SOD tasks. However, it is difficult for SAM trained on single-modal data to directly mine the complementary benefits of multi-modal inputs and comprehensively utilize them to achieve accurate saliency prediction.To address these issues, we first design a multi-modal complementary fusion module to extract robust multi-modal semantic features by integrating information from visible and thermal or depth image pairs. Then, we feed the extracted multi-modal semantic features into both the SAM image encoder and mask decoder for fine-tuning and prompting, respectively. Specifically, in the image encoder, a multi-modal adapter is proposed to adapt the single-modal SAM to multi-modal information. In the mask decoder, a semantic-geometric prompt generation strategy is proposed to produce corresponding embeddings with various saliency cues. Extensive experiments on both RGB-D and RGB-T SOD benchmarks show the effectiveness of the proposed framework.
Learning Adaptive Fusion Bank for Multi-modal Salient Object Detection
Jun 03, 2024Multi-modal salient object detection (MSOD) aims to boost saliency detection performance by integrating visible sources with depth or thermal infrared ones. Existing methods generally design different fusion schemes to handle certain issues or challenges. Although these fusion schemes are effective at addressing specific issues or challenges, they may struggle to handle multiple complex challenges simultaneously. To solve this problem, we propose a novel adaptive fusion bank that makes full use of the complementary benefits from a set of basic fusion schemes to handle different challenges simultaneously for robust MSOD. We focus on handling five major challenges in MSOD, namely center bias, scale variation, image clutter, low illumination, and thermal crossover or depth ambiguity. The fusion bank proposed consists of five representative fusion schemes, which are specifically designed based on the characteristics of each challenge, respectively. The bank is scalable, and more fusion schemes could be incorporated into the bank for more challenges. To adaptively select the appropriate fusion scheme for multi-modal input, we introduce an adaptive ensemble module that forms the adaptive fusion bank, which is embedded into hierarchical layers for sufficient fusion of different source data. Moreover, we design an indirect interactive guidance module to accurately detect salient hollow objects via the skip integration of high-level semantic information and low-level spatial details. Extensive experiments on three RGBT datasets and seven RGBD datasets demonstrate that the proposed method achieves the outstanding performance compared to the state-of-the-art methods. The code and results are available at https://github.com/Angknpng/LAFB.
Alignment-Free RGBT Salient Object Detection: Semantics-guided Asymmetric Correlation Network and A Unified Benchmark
Jun 03, 2024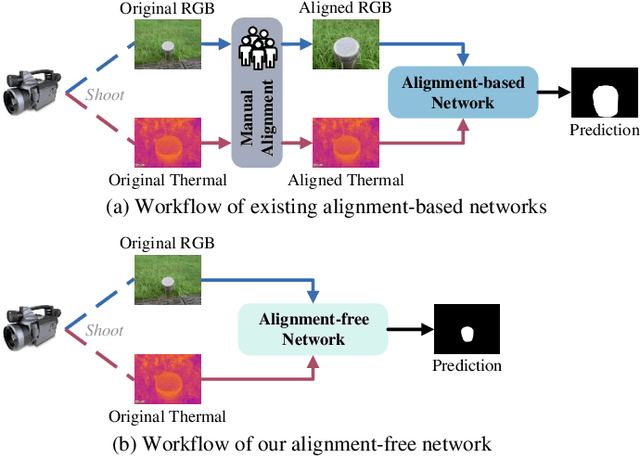

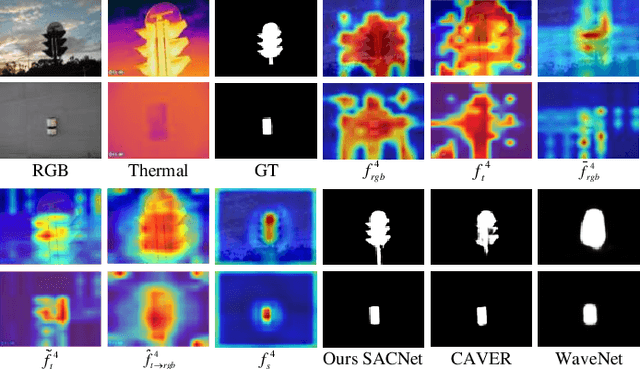

RGB and Thermal (RGBT) Salient Object Detection (SOD) aims to achieve high-quality saliency prediction by exploiting the complementary information of visible and thermal image pairs, which are initially captured in an unaligned manner. However, existing methods are tailored for manually aligned image pairs, which are labor-intensive, and directly applying these methods to original unaligned image pairs could significantly degrade their performance. In this paper, we make the first attempt to address RGBT SOD for initially captured RGB and thermal image pairs without manual alignment. Specifically, we propose a Semantics-guided Asymmetric Correlation Network (SACNet) that consists of two novel components: 1) an asymmetric correlation module utilizing semantics-guided attention to model cross-modal correlations specific to unaligned salient regions; 2) an associated feature sampling module to sample relevant thermal features according to the corresponding RGB features for multi-modal feature integration. In addition, we construct a unified benchmark dataset called UVT2000, containing 2000 RGB and thermal image pairs directly captured from various real-world scenes without any alignment, to facilitate research on alignment-free RGBT SOD. Extensive experiments on both aligned and unaligned datasets demonstrate the effectiveness and superior performance of our method. The dataset and code are available at https://github.com/Angknpng/SACNet.
Ultrasound SAM Adapter: Adapting SAM for Breast Lesion Segmentation in Ultrasound Images
Apr 23, 2024



Segment Anything Model (SAM) has recently achieved amazing results in the field of natural image segmentation. However, it is not effective for medical image segmentation, owing to the large domain gap between natural and medical images. In this paper, we mainly focus on ultrasound image segmentation. As we know that it is very difficult to train a foundation model for ultrasound image data due to the lack of large-scale annotated ultrasound image data. To address these issues, in this paper, we develop a novel Breast Ultrasound SAM Adapter, termed Breast Ultrasound Segment Anything Model (BUSSAM), which migrates the SAM to the field of breast ultrasound image segmentation by using the adapter technique. To be specific, we first design a novel CNN image encoder, which is fully trained on the BUS dataset. Our CNN image encoder is more lightweight, and focuses more on features of local receptive field, which provides the complementary information to the ViT branch in SAM. Then, we design a novel Cross-Branch Adapter to allow the CNN image encoder to fully interact with the ViT image encoder in SAM module. Finally, we add both of the Position Adapter and the Feature Adapter to the ViT branch to fine-tune the original SAM. The experimental results on AMUBUS and BUSI datasets demonstrate that our proposed model outperforms other medical image segmentation models significantly. Our code will be available at: https://github.com/bscs12/BUSSAM.
A Spatial-Temporal Progressive Fusion Network for Breast Lesion Segmentation in Ultrasound Videos
Mar 18, 2024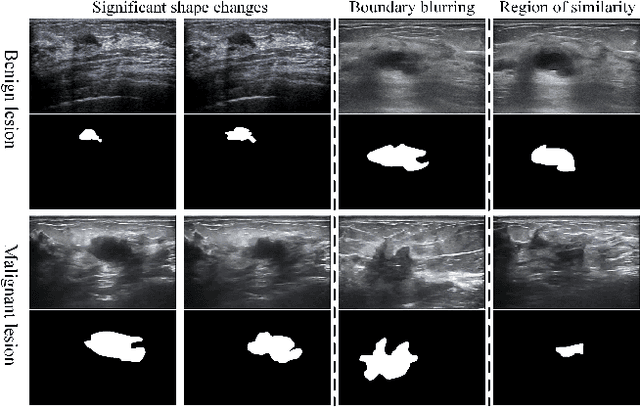
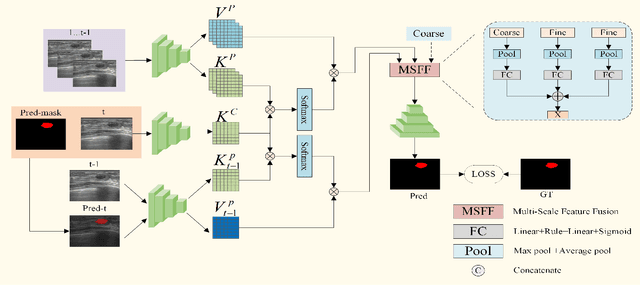
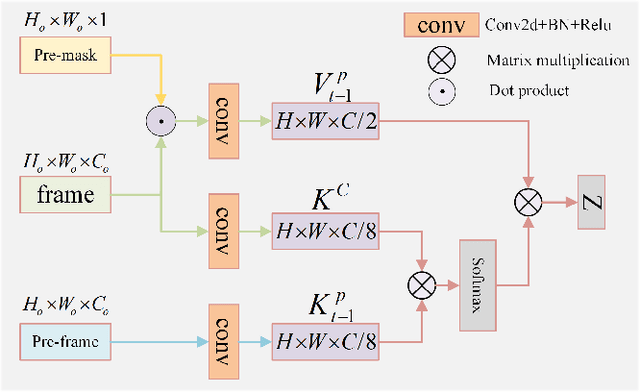
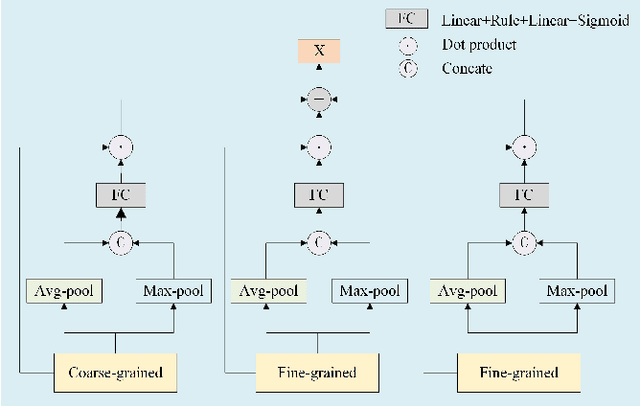
Ultrasound video-based breast lesion segmentation provides a valuable assistance in early breast lesion detection and treatment. However, existing works mainly focus on lesion segmentation based on ultrasound breast images which usually can not be adapted well to obtain desirable results on ultrasound videos. The main challenge for ultrasound video-based breast lesion segmentation is how to exploit the lesion cues of both intra-frame and inter-frame simultaneously. To address this problem, we propose a novel Spatial-Temporal Progressive Fusion Network (STPFNet) for video based breast lesion segmentation problem. The main aspects of the proposed STPFNet are threefold. First, we propose to adopt a unified network architecture to capture both spatial dependences within each ultrasound frame and temporal correlations between different frames together for ultrasound data representation. Second, we propose a new fusion module, termed Multi-Scale Feature Fusion (MSFF), to fuse spatial and temporal cues together for lesion detection. MSFF can help to determine the boundary contour of lesion region to overcome the issue of lesion boundary blurring. Third, we propose to exploit the segmentation result of previous frame as the prior knowledge to suppress the noisy background and learn more robust representation. In particular, we introduce a new publicly available ultrasound video breast lesion segmentation dataset, termed UVBLS200, which is specifically dedicated to breast lesion segmentation. It contains 200 videos, including 80 videos of benign lesions and 120 videos of malignant lesions. Experiments on the proposed dataset demonstrate that the proposed STPFNet achieves better breast lesion detection performance than state-of-the-art methods.