 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Spatio-temporal Graph Learning for Alignment-free RGBT Video Object Detection
Paper and Code
Apr 16, 2025
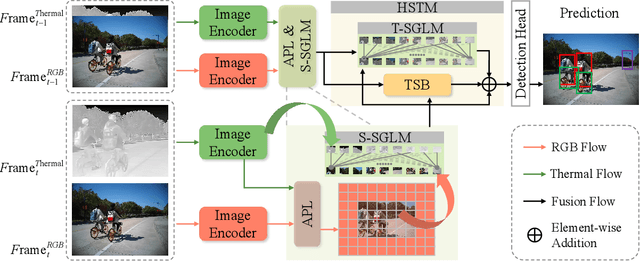
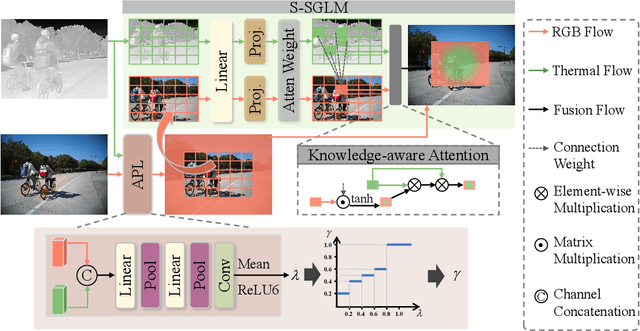
RGB-Thermal Video Object Detection (RGBT VOD) can address the limitation of traditional RGB-based VOD in challenging lighting conditions, making it more practical and effective in many applications. However, similar to most RGBT fusion tasks, it still mainly relies on manually aligned multimodal image pairs. In this paper, we propose a novel Multimodal Spatio-temporal Graph learning Network (MSGNet) for alignment-free RGBT VOD problem by leveraging the robust graph representation learning model. Specifically, we first design an Adaptive Partitioning Layer (APL) to estimate the corresponding regions of the Thermal image within the RGB image (high-resolution), achieving a preliminary inexact alignment. Then, we introduce the Spatial Sparse Graph Learning Module (S-SGLM) which employs a sparse information passing mechanism on the estimated inexact alignment to achieve reliable information interaction between different modalities. Moreover, to fully exploit the temporal cues for RGBT VOD problem, we introduce Hybrid Structured Temporal Modeling (HSTM), which involves a Temporal Sparse Graph Learning Module (T-SGLM) and Temporal Star Block (TSB). T-SGLM aims to filter out some redundant information between adjacent frames by employing the sparse aggregation mechanism on the temporal graph. Meanwhile, TSB is dedicated to achieving the complementary learning of local spatial relationships. Extensive comparative experiments conducted on both the aligned dataset VT-VOD50 and the unaligned dataset UVT-VOD2024 demonstrate the effectiveness and superiority of our proposed method. Our project will be made available on our website for free public access.