 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Free RGB-T Salient Object Detection: A Large-scale Dataset and Progressive Correlation Network
Dec 19, 2024



Alignment-free RGB-Thermal (RGB-T) salient object detection (SOD) aims to achieve robust performance in complex scenes by directly leveraging the complementary information from unaligned visible-thermal image pairs, without requiring manual alignment. However, the labor-intensive process of collecting and annotating image pairs limits the scale of existing benchmarks, hindering the advancement of alignment-free RGB-T SOD. In this paper, we construct a large-scale and high-diversity unaligned RGB-T SOD dataset named UVT20K, comprising 20,000 image pairs, 407 scenes, and 1256 object categories. All samples are collected from real-world scenarios with various challenges, such as low illumination, image clutter, complex salient objects, and so on. To support the exploration for further research, each sample in UVT20K is annotated with a comprehensive set of ground truths, including saliency masks, scribbles, boundaries, and challenge attributes. In addition, we propose a Progressive Correlation Network (PCNet), which models inter- and intra-modal correlations on the basis of explicit alignment to achieve accurate predictions in unaligned image pairs. Extensive experiments conducted on unaligned and aligned datasets demonstrate the effectiveness of our method.Code and dataset are available at https://github.com/Angknpng/PCNet.
Unveiling the Limits of Alignment: Multi-modal Dynamic Local Fusion Network and A Benchmark for Unaligned RGBT Video Object Detection
Oct 16, 2024



Current RGB-Thermal Video Object Detection (RGBT VOD) methods still depend on manually aligning data at the image level, which hampers its practical application in real-world scenarios since image pairs captured by multispectral sensors often differ in both fields of view and resolution. To address this limitation, we propose a Multi-modal Dynamic Local fusion Network (MDLNet) designed to handle unaligned RGBT image pairs. Specifically, our proposed Multi-modal Dynamic Local Fusion (MDLF) module includes a set of predefined boxes, each enhanced with random Gaussian noise to generate a dynamic box. Each box selects a local region from the original high-resolution RGB image. This region is then fused with the corresponding information from another modality and reinserted into the RGB. This method adapts to various data alignment scenarios by interacting with local features across different ranges. Simultaneously, we introduce a Cascaded Temporal Scrambler (CTS) within an end-to-end architecture. This module leverages consistent spatiotemporal information from consecutive frames to enhance the representation capability of the current frame while maintaining network efficiency. We have curated an open dataset called UVT-VOD2024 for unaligned RGBT VOD. It consists of 30,494 pairs of unaligned RGBT images captured directly from a multispectral camera. We conduct a comprehensive evaluation and comparison with MDLNet and state-of-the-art (SOTA) models, demonstrating the superior effectiveness of MDLNet. We will release our code and UVT-VOD2024 to the public for further research.
3-D Magnetotelluric Deep Learning Inversion Guided by Pseudo-Physical Information
Oct 12, 2024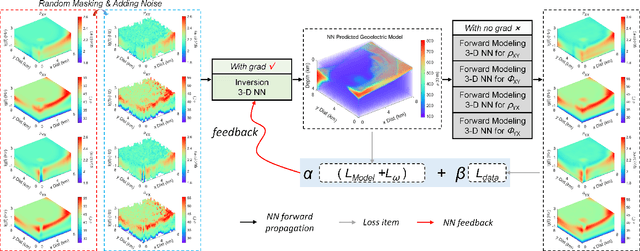
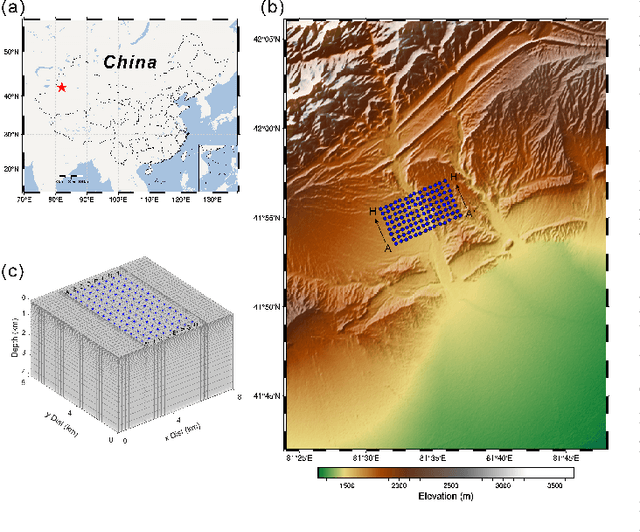
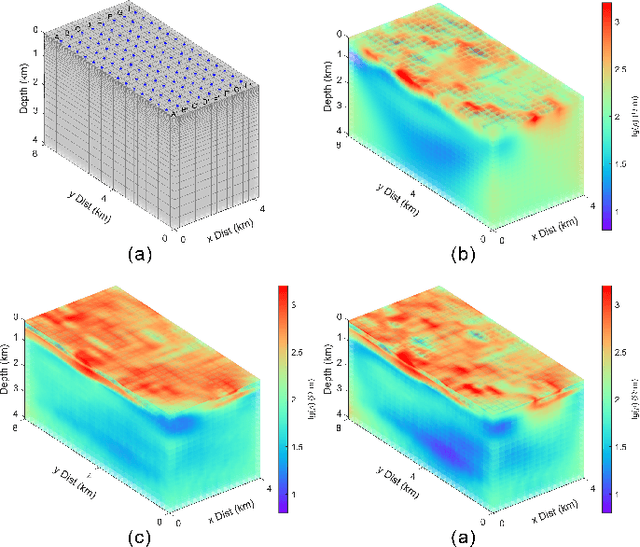
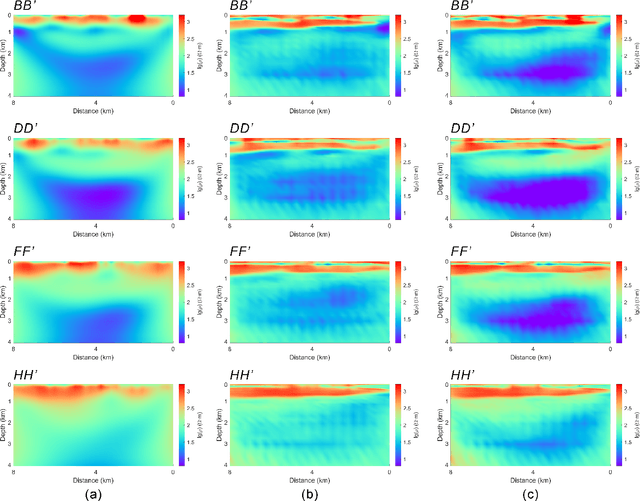
Magnetotelluric deep learning (DL) inversion methods based on joint data-driven and physics-driven have become a hot topic in recent years. When mapping observation data (or forward modeling data) to the resistivity model using neural networks (NNs), incorporating the error (loss) term of the inversion resistivity's forward modeling response--which introduces physical information about electromagnetic field propagation--can significantly enhance the inversion accuracy. To efficiently achieve data-physical dual-driven MT deep learning inversion for large-scale 3-D MT data, we propose using DL forward modeling networks to compute this portion of the loss. This approach introduces pseudo-physical information through the forward modeling of NN simulation, further guiding the inversion network fitting. Specifically, we first pre-train the forward modeling networks as fixed forward modeling operators, then transfer and integrate them into the inversion network training, and finally optimize the inversion network by minimizing the multinomial loss. Theoretical experimental results indicate that despite some simulation errors in DL forward modeling, the introduced pseudo-physical information still enhances inversion accuracy and significantly mitigates the overfitting problem during training. Additionally, we propose a new input mode that involves masking and adding noise to the data, simulating the field data environment of 3-D MT inversion, thereby making the method more flexible and effective for practical applications.
Adapting Segment Anything Model to Multi-modal Salient Object Detection with Semantic Feature Fusion Guidance
Aug 27, 2024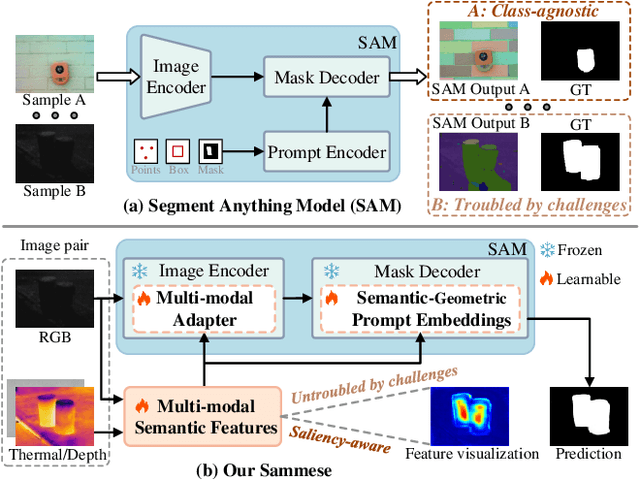
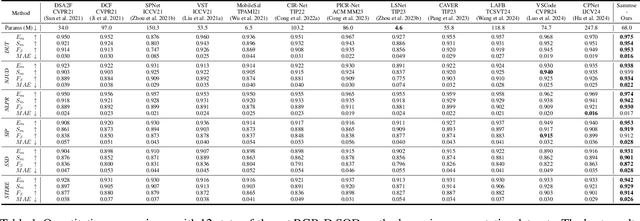
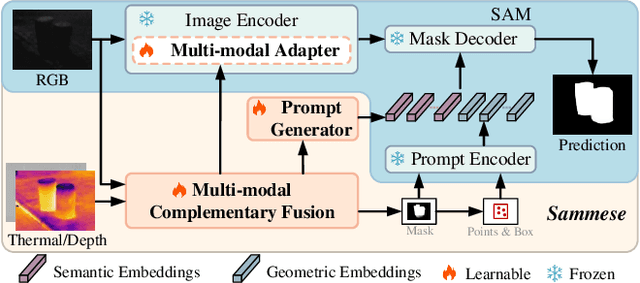

Although most existing multi-modal salient object detection (SOD) methods demonstrate effectiveness through training models from scratch, the limited multi-modal data hinders these methods from reaching optimality. In this paper, we propose a novel framework to explore and exploit the powerful feature representation and zero-shot generalization ability of the pre-trained Segment Anything Model (SAM) for multi-modal SOD. Despite serving as a recent vision fundamental model, driving the class-agnostic SAM to comprehend and detect salient objects accurately is non-trivial, especially in challenging scenes. To this end, we develop \underline{SAM} with se\underline{m}antic f\underline{e}ature fu\underline{s}ion guidanc\underline{e} (Sammese), which incorporates multi-modal saliency-specific knowledge into SAM to adapt SAM to multi-modal SOD tasks. However, it is difficult for SAM trained on single-modal data to directly mine the complementary benefits of multi-modal inputs and comprehensively utilize them to achieve accurate saliency prediction.To address these issues, we first design a multi-modal complementary fusion module to extract robust multi-modal semantic features by integrating information from visible and thermal or depth image pairs. Then, we feed the extracted multi-modal semantic features into both the SAM image encoder and mask decoder for fine-tuning and prompting, respectively. Specifically, in the image encoder, a multi-modal adapter is proposed to adapt the single-modal SAM to multi-modal information. In the mask decoder, a semantic-geometric prompt generation strategy is proposed to produce corresponding embeddings with various saliency cues. Extensive experiments on both RGB-D and RGB-T SOD benchmarks show the effectiveness of the proposed framework.
Learning Adaptive Fusion Bank for Multi-modal Salient Object Detection
Jun 03, 2024Multi-modal salient object detection (MSOD) aims to boost saliency detection performance by integrating visible sources with depth or thermal infrared ones. Existing methods generally design different fusion schemes to handle certain issues or challenges. Although these fusion schemes are effective at addressing specific issues or challenges, they may struggle to handle multiple complex challenges simultaneously. To solve this problem, we propose a novel adaptive fusion bank that makes full use of the complementary benefits from a set of basic fusion schemes to handle different challenges simultaneously for robust MSOD. We focus on handling five major challenges in MSOD, namely center bias, scale variation, image clutter, low illumination, and thermal crossover or depth ambiguity. The fusion bank proposed consists of five representative fusion schemes, which are specifically designed based on the characteristics of each challenge, respectively. The bank is scalable, and more fusion schemes could be incorporated into the bank for more challenges. To adaptively select the appropriate fusion scheme for multi-modal input, we introduce an adaptive ensemble module that forms the adaptive fusion bank, which is embedded into hierarchical layers for sufficient fusion of different source data. Moreover, we design an indirect interactive guidance module to accurately detect salient hollow objects via the skip integration of high-level semantic information and low-level spatial details. Extensive experiments on three RGBT datasets and seven RGBD datasets demonstrate that the proposed method achieves the outstanding performance compared to the state-of-the-art methods. The code and results are available at https://github.com/Angknpng/LAFB.
Alignment-Free RGBT Salient Object Detection: Semantics-guided Asymmetric Correlation Network and A Unified Benchmark
Jun 03, 2024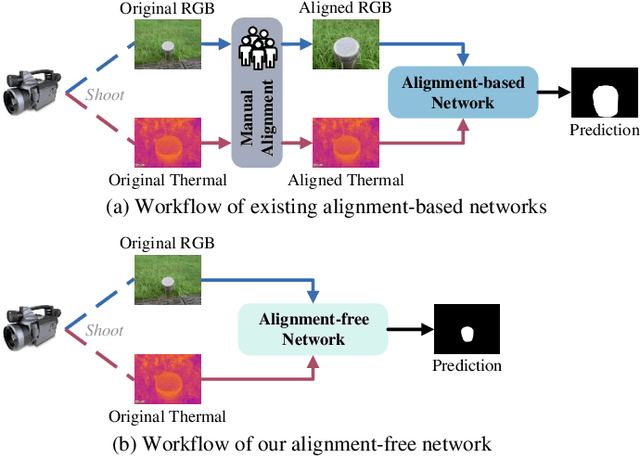

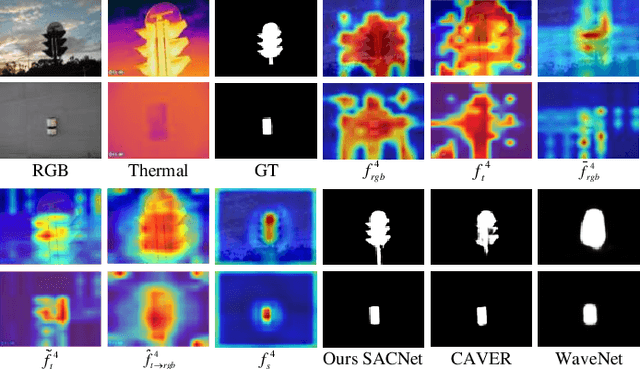

RGB and Thermal (RGBT) Salient Object Detection (SOD) aims to achieve high-quality saliency prediction by exploiting the complementary information of visible and thermal image pairs, which are initially captured in an unaligned manner. However, existing methods are tailored for manually aligned image pairs, which are labor-intensive, and directly applying these methods to original unaligned image pairs could significantly degrade their performance. In this paper, we make the first attempt to address RGBT SOD for initially captured RGB and thermal image pairs without manual alignment. Specifically, we propose a Semantics-guided Asymmetric Correlation Network (SACNet) that consists of two novel components: 1) an asymmetric correlation module utilizing semantics-guided attention to model cross-modal correlations specific to unaligned salient regions; 2) an associated feature sampling module to sample relevant thermal features according to the corresponding RGB features for multi-modal feature integration. In addition, we construct a unified benchmark dataset called UVT2000, containing 2000 RGB and thermal image pairs directly captured from various real-world scenes without any alignment, to facilitate research on alignment-free RGBT SOD. Extensive experiments on both aligned and unaligned datasets demonstrate the effectiveness and superior performance of our method. The dataset and code are available at https://github.com/Angknpng/SACNet.
Unified-modal Salient Object Detection via Adaptive Prompt Learning
Nov 29, 2023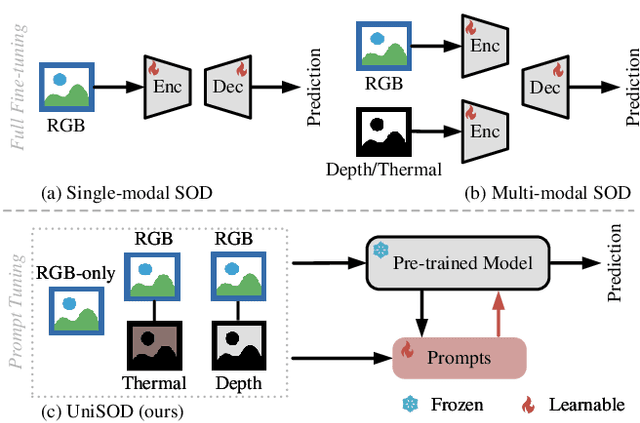
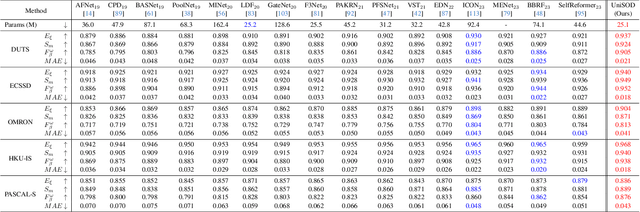
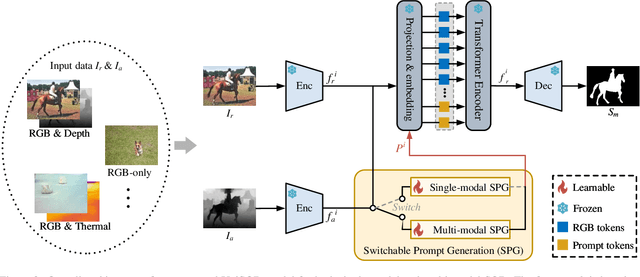
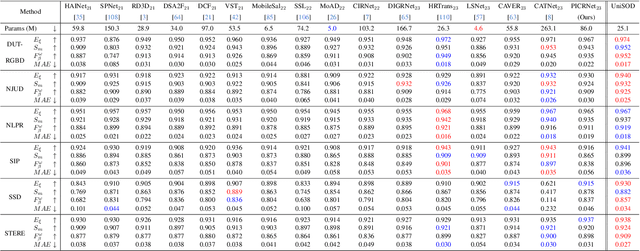
Existing single-modal and multi-modal salient object detection (SOD) methods focus on designing specific architectures tailored for their respective tasks. However, developing completely different models for different tasks leads to labor and time consumption, as well as high computational and practical deployment costs. In this paper, we make the first attempt to address both single-modal and multi-modal SOD in a unified framework called UniSOD. Nevertheless, assigning appropriate strategies to modality variable inputs is challenging. To this end, UniSOD learns modality-aware prompts with task-specific hints through adaptive prompt learning, which are plugged into the proposed pre-trained baseline SOD model to handle corresponding tasks, while only requiring few learnable parameters compared to training the entire model. Each modality-aware prompt is generated from a switchable prompt generation block, which performs structural switching solely relied on single-modal and multi-modal inputs. UniSOD achieves consistent performance improvement on 14 benchmark datasets for RGB, RGB-D, and RGB-T SOD, which demonstrates that our method effectively and efficiently unifies single-modal and multi-modal SOD tasks.
RecycleGPT: An Autoregressive Language Model with Recyclable Module
Aug 08, 2023Existing large language models have to run K times to generate a sequence of K tokens. In this paper, we present RecycleGPT, a generative language model with fast decoding speed by recycling pre-generated model states without running the whole model in multiple steps. Our approach relies on the observation that adjacent tokens in a sequence usually have strong correlations and the next token in a sequence can be reasonably guessed or inferred based on the preceding ones. Experiments and analysis demonstrate the effectiveness of our approach in lowering inference latency, achieving up to 1.4x speedup while preserving high performance.
Erasure-based Interaction Network for RGBT Video Object Detection and A Unified Benchmark
Aug 03, 2023

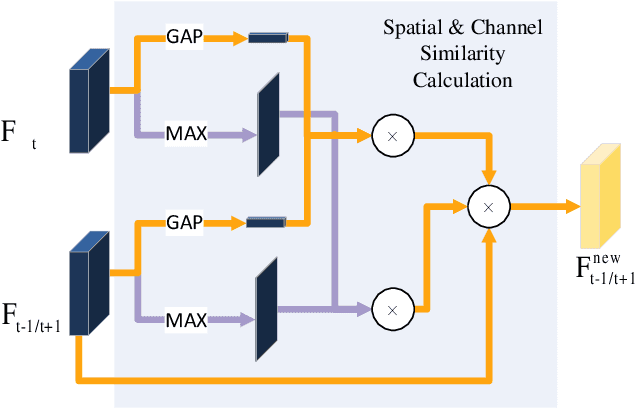
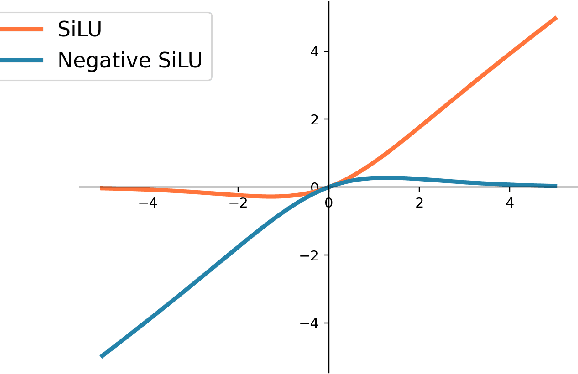
Recently, many breakthroughs are made in the field of Video Object Detection (VOD), but the performance is still limited due to the imaging limitations of RGB sensors in adverse illumination conditions. To alleviate this issue, this work introduces a new computer vision task called RGB-thermal (RGBT) VOD by introducing the thermal modality that is insensitive to adverse illumination conditions. To promote the research and development of RGBT VOD, we design a novel Erasure-based Interaction Network (EINet) and establish a comprehensive benchmark dataset (VT-VOD50) for this task. Traditional VOD methods often leverage temporal information by using many auxiliary frames, and thus have large computational burden. Considering that thermal images exhibit less noise than RGB ones, we develop a negative activation function that is used to erase the noise of RGB features with the help of thermal image features. Furthermore, with the benefits from thermal images, we rely only on a small temporal window to model the spatio-temporal information to greatly improve efficiency while maintaining detection accuracy. VT-VOD50 dataset consists of 50 pairs of challenging RGBT video sequences with complex backgrounds, various objects and different illuminations, which are collected in real traffic scenarios. Extensive experiments on VT-VOD50 dataset demonstrate the effectiveness and efficiency of our proposed method against existing mainstream VOD methods. The code of EINet and the dataset will be released to the public for free academic usage.
A CT-Based Airway Segmentation Using U$^2$-net Trained by the Dice Loss Function
Sep 22, 2022



Airway segmentation from chest computed tomography scans has played an essential role in the pulmonary disease diagnosis. The computer-assisted airway segmentation based on the U-net architecture is more efficient and accurate compared to the manual segmentation. In this paper we employ the U$^2$-net trained by the Dice loss function to model the airway tree from the multi-site CT scans based on 299 training CT scans provided by the ATM'22. The derived saliency probability map from the training is applied to the validation data to extract the corresponding airway trees. The observation shows that the majority of the segmented airway trees behave well from the perspective of accuracy and connectivity. Refinements such as non-airway regions labeling and removing are applied to certain obtained airway tree models to display the largest component of the binary results.