 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulate, Reason, Decide: Scientific Reasoning with LLMs for Simulation-Driven Decision Making
Jun 03, 2026Scientific simulators are increasingly being integrated into LLM-driven systems for high-stakes simulation-driven decision-making. However, existing frameworks primarily use LLMs to generate, calibrate, or execute simulators, treating them as black-box interfaces rather than as structured mechanistic systems that can be reasoned about. As a result, current approaches lack the ability to identify, represent, and reason about the assumptions and mechanisms underlying simulator behavior, limiting transparency, auditability, and decision justification. We introduce MechSim, a mechanism-grounded neuro-symbolic reasoning framework for executable scientific simulators. Unlike prior neuro-symbolic approaches that primarily reason over static symbolic structures, MechSim enables LLM agents to reason about the mechanisms, assumptions, and execution behavior of scientific simulators. Our framework represents simulators through a shared structured schema capturing assumptions, variables, mechanism dependencies, and execution traces. On top of this representation, LLM agents operate as constrained reasoning engines that generate structured, evidence-grounded explanations linking simulator outcomes to their underlying mechanisms. We evaluate our approach across multiple high-stakes domains and show that it improves mechanism-level explanation quality, simulator analysis, and downstream decision-making reliability.
Unleashing the Potential of Neighbors: Diffusion-based Latent Neighbor Generation for Session-based Recommendation
Jan 07, 2026Session-based recommendation aims to predict the next item that anonymous users may be interested in, based on their current session interactions. Recent studies have demonstrated that retrieving neighbor sessions to augment the current session can effectively alleviate the data sparsity issue and improve recommendation performance. However, existing methods typically rely on explicitly observed session data, neglecting latent neighbors - not directly observed but potentially relevant within the interest space - thereby failing to fully exploit the potential of neighbor sessions in recommendation. To address the above limitation, we propose a novel model of diffusion-based latent neighbor generation for session-based recommendation, named DiffSBR. Specifically, DiffSBR leverages two diffusion modules, including retrieval-augmented diffusion and self-augmented diffusion, to generate high-quality latent neighbors. In the retrieval-augmented diffusion module, we leverage retrieved neighbors as guiding signals to constrain and reconstruct the distribution of latent neighbors. Meanwhile, we adopt a training strategy that enables the retriever to learn from the feedback provided by the generator. In the self-augmented diffusion module, we explicitly guide the generation of latent neighbors by injecting the current session's multi-modal signals through contrastive learning. After obtaining the generated latent neighbors, we utilize them to enhance session representations for improving session-based recommendation. Extensive experiments on four public datasets show that DiffSBR generates effective latent neighbors and improves recommendation performance against state-of-the-art baselines.
3-D Magnetotelluric Deep Learning Inversion Guided by Pseudo-Physical Information
Oct 12, 2024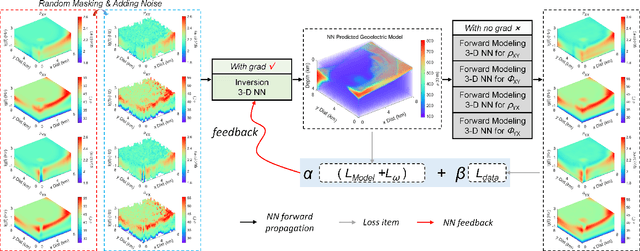
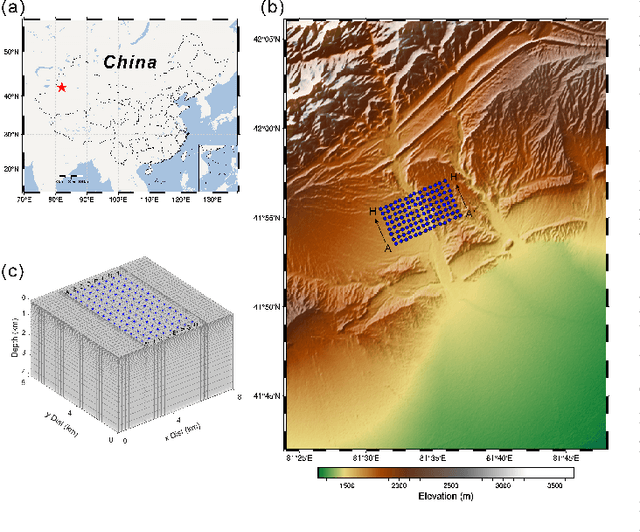
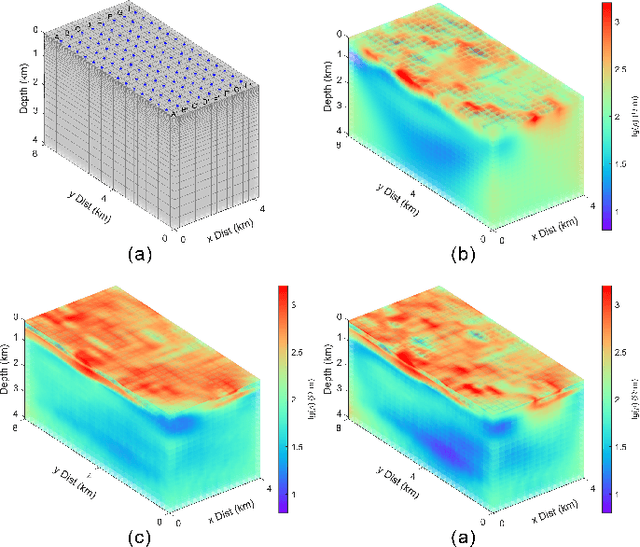
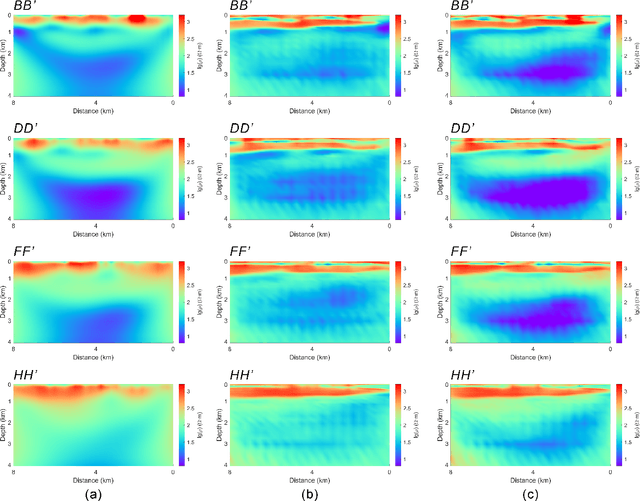
Magnetotelluric deep learning (DL) inversion methods based on joint data-driven and physics-driven have become a hot topic in recent years. When mapping observation data (or forward modeling data) to the resistivity model using neural networks (NNs), incorporating the error (loss) term of the inversion resistivity's forward modeling response--which introduces physical information about electromagnetic field propagation--can significantly enhance the inversion accuracy. To efficiently achieve data-physical dual-driven MT deep learning inversion for large-scale 3-D MT data, we propose using DL forward modeling networks to compute this portion of the loss. This approach introduces pseudo-physical information through the forward modeling of NN simulation, further guiding the inversion network fitting. Specifically, we first pre-train the forward modeling networks as fixed forward modeling operators, then transfer and integrate them into the inversion network training, and finally optimize the inversion network by minimizing the multinomial loss. Theoretical experimental results indicate that despite some simulation errors in DL forward modeling, the introduced pseudo-physical information still enhances inversion accuracy and significantly mitigates the overfitting problem during training. Additionally, we propose a new input mode that involves masking and adding noise to the data, simulating the field data environment of 3-D MT inversion, thereby making the method more flexible and effective for practical applications.
One-Bit Byzantine-Tolerant Distributed Learning via Over-the-Air Computation
Oct 19, 2023Distributed learning has become a promising computational parallelism paradigm that enables a wide scope of intelligent applications from the Internet of Things (IoT) to autonomous driving and the healthcare industry. This paper studies distributed learning in wireless data center networks, which contain a central edge server and multiple edge workers to collaboratively train a shared global model and benefit from parallel computing. However, the distributed nature causes the vulnerability of the learning process to faults and adversarial attacks from Byzantine edge workers, as well as the severe communication and computation overhead induced by the periodical information exchange process. To achieve fast and reliable model aggregation in the presence of Byzantine attacks, we develop a signed stochastic gradient descent (SignSGD)-based Hierarchical Vote framework via over-the-air computation (AirComp), where one voting process is performed locally at the wireless edge by taking advantage of Bernoulli coding while the other is operated over-the-air at the central edge server by utilizing the waveform superposition property of the multiple-access channels. We comprehensively analyze the proposed framework on the impacts including Byzantine attacks and the wireless environment (channel fading and receiver noise), followed by characterizing the convergence behavior under non-convex settings. Simulation results validate our theoretical achievements and demonstrate the robustness of our proposed framework in the presence of Byzantine attacks and receiver noise.
Differentially Private Federated Learning via Reconfigurable Intelligent Surface
Mar 31, 2022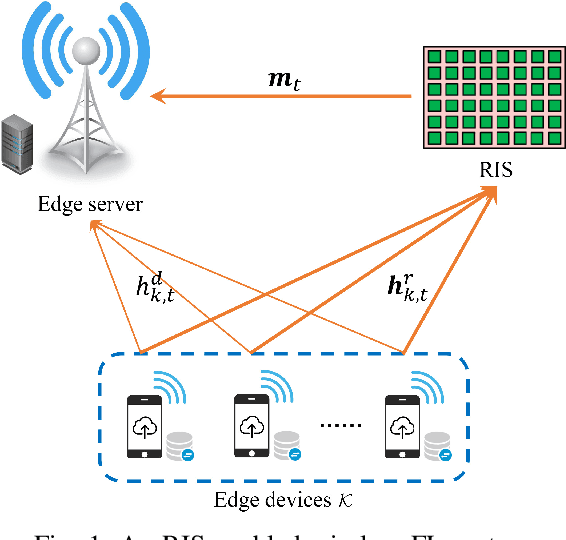
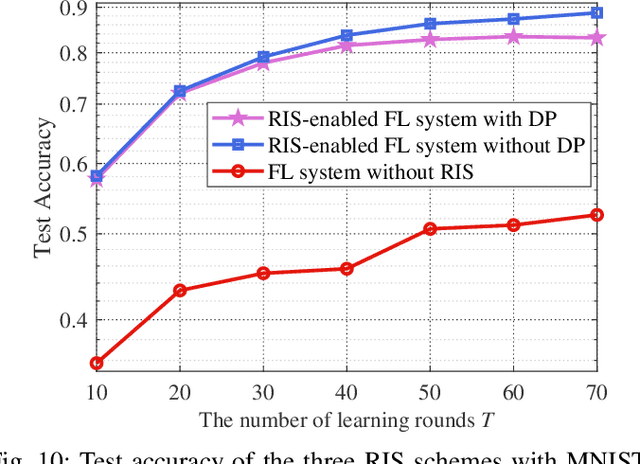
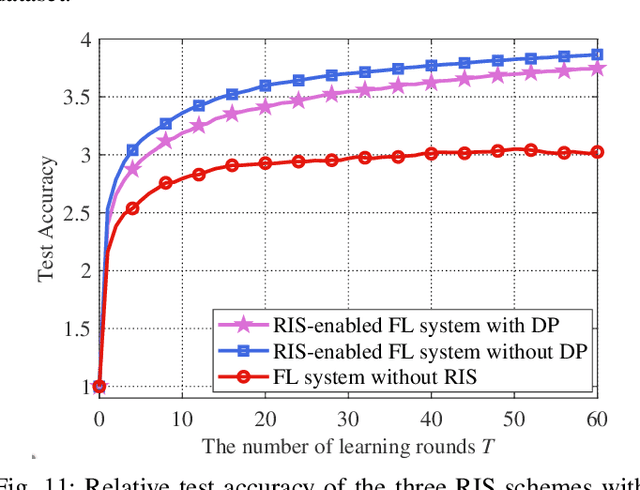
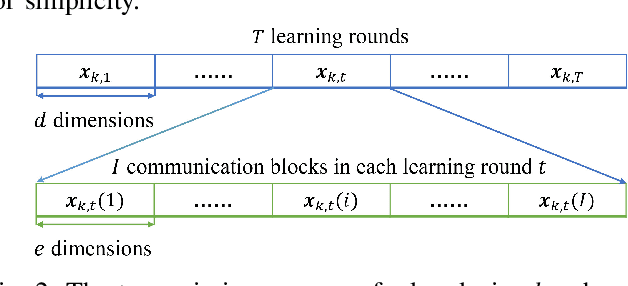
Federated learning (FL), as a disruptive machine learning paradigm, enables the collaborative training of a global model over decentralized local datasets without sharing them. It spans a wide scope of applications from Internet-of-Things (IoT) to biomedical engineering and drug discovery. To support low-latency and high-privacy FL over wireless networks, in this paper, we propose a reconfigurable intelligent surface (RIS) empowered over-the-air FL system to alleviate the dilemma between learning accuracy and privacy. This is achieved by simultaneously exploiting the channel propagation reconfigurability with RIS for boosting the receive signal power, as well as waveform superposition property with over-the-air computation (AirComp) for fast model aggregation. By considering a practical scenario where high-dimensional local model updates are transmitted across multiple communication blocks, we characterize the convergence behaviors of the differentially private federated optimization algorithm. We further formulate a system optimization problem to optimize the learning accuracy while satisfying privacy and power constraints via the joint design of transmit power, artificial noise, and phase shifts at RIS, for which a two-step alternating minimization framework is developed. Simulation results validate our systematic, theoretical, and algorithmic achievements and demonstrate that RIS can achieve a better trade-off between privacy and accuracy for over-the-air FL systems.
Fast Convergence Algorithm for Analog Federated Learning
Oct 30, 2020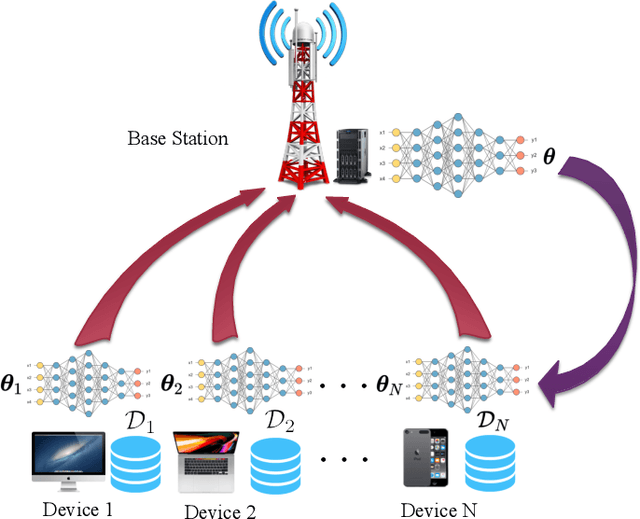
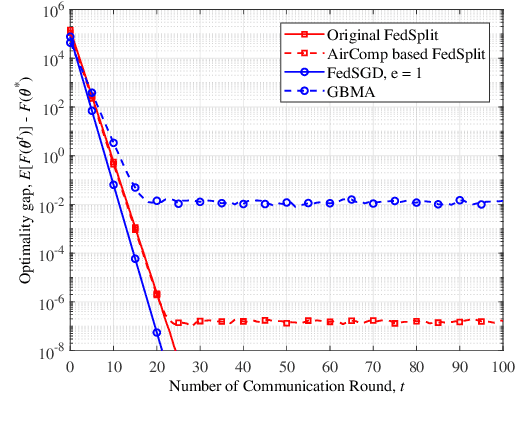
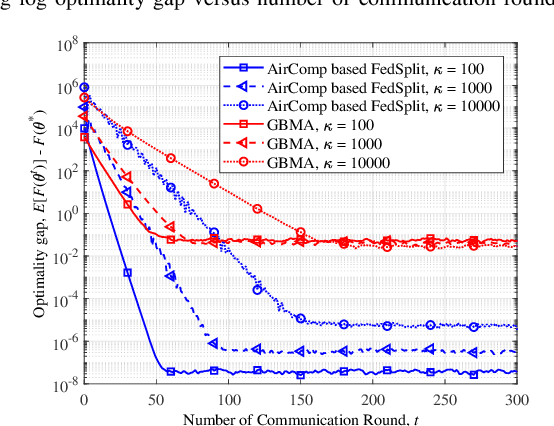
In this paper, we consider federated learning (FL) over a noisy fading multiple access channel (MAC), where an edge server aggregates the local models transmitted by multiple end devices through over-the-air computation (AirComp). To realize efficient analog federated learning over wireless channels, we propose an AirComp-based FedSplit algorithm, where a threshold-based device selection scheme is adopted to achieve reliable local model uploading. In particular, we analyze the performance of the proposed algorithm and prove that the proposed algorithm linearly converges to the optimal solutions under the assumption that the objective function is strongly convex and smooth. We also characterize the robustness of proposed algorithm to the ill-conditioned problems, thereby achieving fast convergence rates and reducing communication rounds. A finite error bound is further provided to reveal the relationship between the convergence behavior and the channel fading and noise. Our algorithm is theoretically and experimentally verified to be much more robust to the ill-conditioned problems with faster convergence compared with other benchmark FL algorithms.
Recent progress in semantic image segmentation
Sep 20, 2018
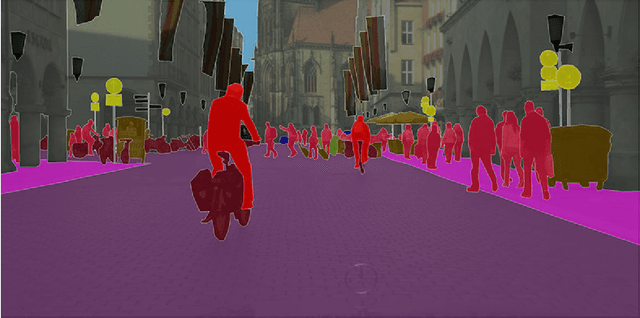
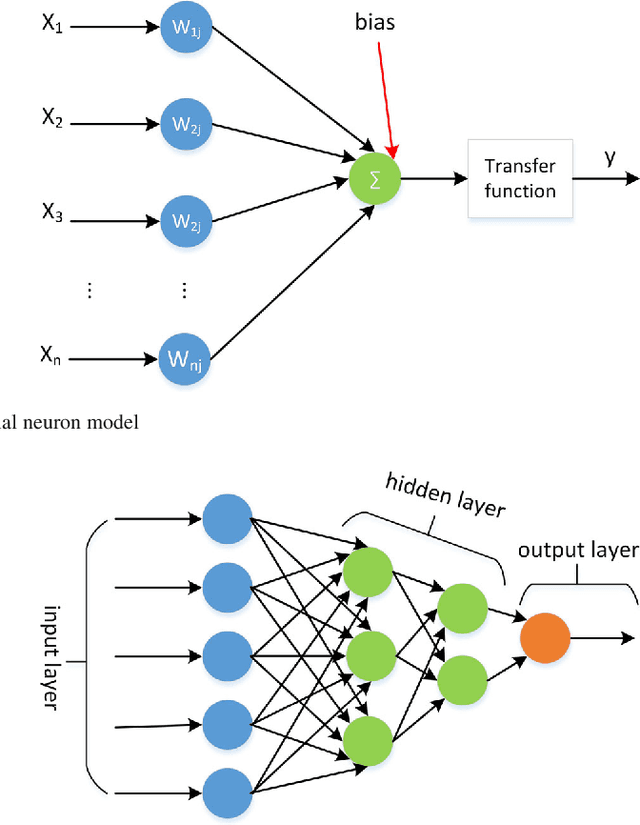
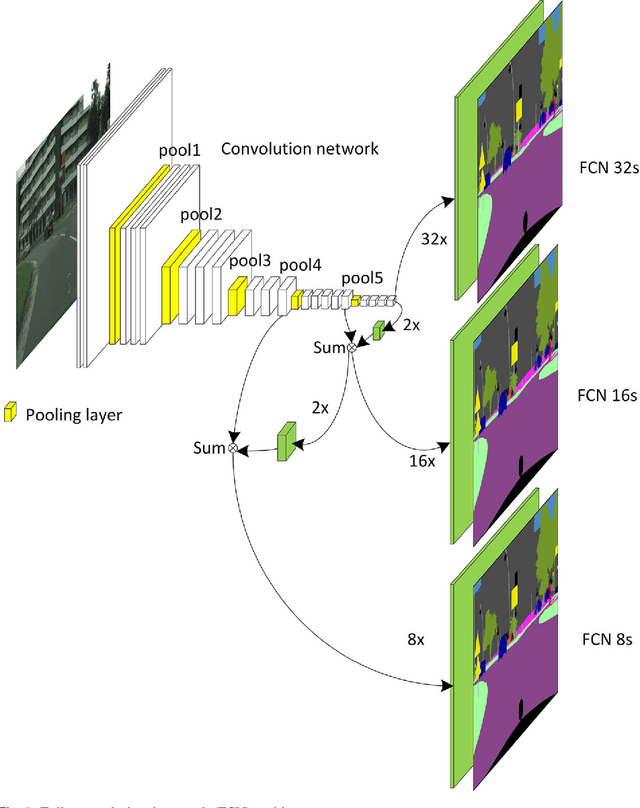
Semantic image segmentation, which becomes one of the key applications in image processing and computer vision domain, has been used in multiple domains such as medical area and intelligent transportation. Lots of benchmark datasets are released for researchers to verify their algorithms. Semantic segmentation has been studied for many years. Since the emergence of Deep Neural Network (DNN), segmentation has made a tremendous progress. In this paper, we divide semantic image segmentation methods into two categories: traditional and recent DNN method. Firstly, we briefly summarize the traditional method as well as datasets released for segmentation, then we comprehensively investigate recent methods based on DNN which are described in the eight aspects: fully convolutional network, upsample ways, FCN joint with CRF methods, dilated convolution approaches, progresses in backbone network, pyramid methods, Multi-level feature and multi-stage method, supervised, weakly-supervised and unsupervised methods. Finally, a conclusion in this area is drawn.
* Pubulished at Artificial Intelligence review