 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVertical Federated Learning over Cloud-RAN: Convergence Analysis and System Optimization
May 04, 2023Vertical federated learning (FL) is a collaborative machine learning framework that enables devices to learn a global model from the feature-partition datasets without sharing local raw data. However, as the number of the local intermediate outputs is proportional to the training samples, it is critical to develop communication-efficient techniques for wireless vertical FL to support high-dimensional model aggregation with full device participation. In this paper, we propose a novel cloud radio access network (Cloud-RAN) based vertical FL system to enable fast and accurate model aggregation by leveraging over-the-air computation (AirComp) and alleviating communication straggler issue with cooperative model aggregation among geographically distributed edge servers. However, the model aggregation error caused by AirComp and quantization errors caused by the limited fronthaul capacity degrade the learning performance for vertical FL. To address these issues, we characterize the convergence behavior of the vertical FL algorithm considering both uplink and downlink transmissions. To improve the learning performance, we establish a system optimization framework by joint transceiver and fronthaul quantization design, for which successive convex approximation and alternate convex search based system optimization algorithms are developed. We conduct extensive simulations to demonstrate the effectiveness of the proposed system architecture and optimization framework for vertical FL.
Reconfigurable Intelligent Surface for Massive Connectivity
Jan 13, 2021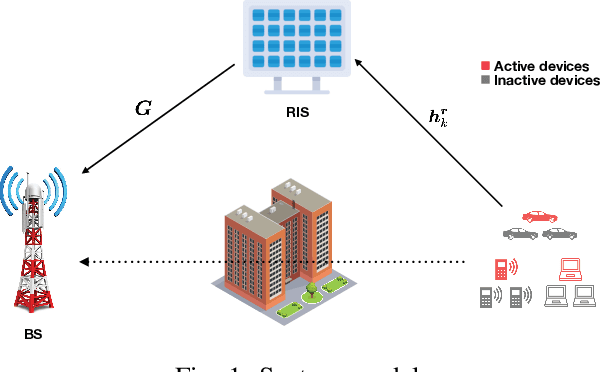



With the rapid development of Internet of Things (IoT), massive machine-type communication has become a promising application scenario, where a large number of devices transmit sporadically to a base station (BS). Reconfigurable intelligent surface (RIS) has been recently proposed as an innovative new technology to achieve energy efficiency and coverage enhancement by establishing favorable signal propagation environments, thereby improving data transmission in massive connectivity. Nevertheless, the BS needs to detect active devices and estimate channels to support data transmission in RIS-assisted massive access systems, which yields unique challenges. This paper shall consider an RIS-assisted uplink IoT network and aims to solve the RIS-related activity detection and channel estimation problem, where the BS detects the active devices and estimates the separated channels of the RIS-to-device link and the RIS-to-BS link. Due to limited scattering between the RIS and the BS, we model the RIS-to-BS channel as a sparse channel. As a result, by simultaneously exploiting both the sparsity of sporadic transmission in massive connectivity and the RIS-to-BS channels, we formulate the RIS-related activity detection and channel estimation problem as a sparse matrix factorization problem. Furthermore, we develop an approximate message passing (AMP) based algorithm to solve the problem based on Bayesian inference framework and reduce the computational complexity by approximating the algorithm with the central limit theorem and Taylor series arguments. Finally, extensive numerical experiments are conducted to verify the effectiveness and improvements of the proposed algorithm.
Fast Convergence Algorithm for Analog Federated Learning
Oct 30, 2020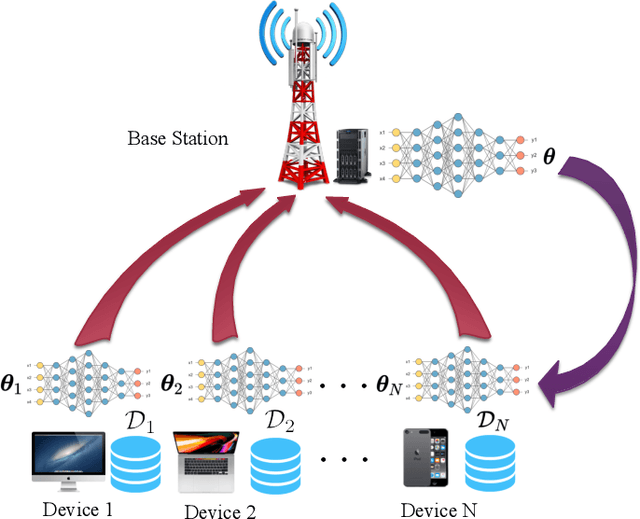
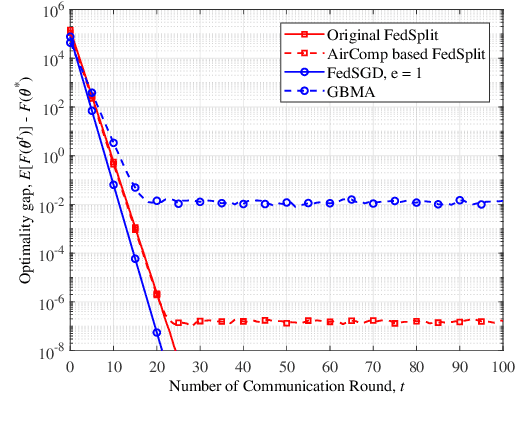
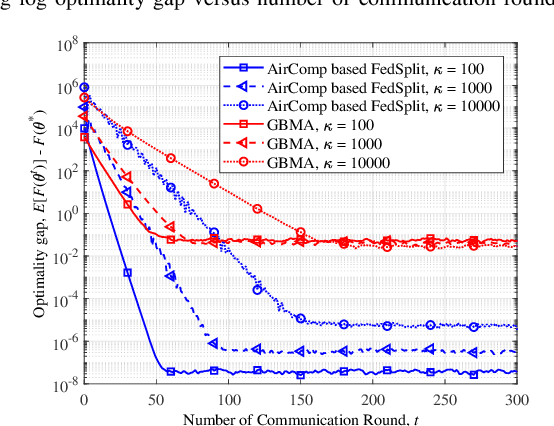
In this paper, we consider federated learning (FL) over a noisy fading multiple access channel (MAC), where an edge server aggregates the local models transmitted by multiple end devices through over-the-air computation (AirComp). To realize efficient analog federated learning over wireless channels, we propose an AirComp-based FedSplit algorithm, where a threshold-based device selection scheme is adopted to achieve reliable local model uploading. In particular, we analyze the performance of the proposed algorithm and prove that the proposed algorithm linearly converges to the optimal solutions under the assumption that the objective function is strongly convex and smooth. We also characterize the robustness of proposed algorithm to the ill-conditioned problems, thereby achieving fast convergence rates and reducing communication rounds. A finite error bound is further provided to reveal the relationship between the convergence behavior and the channel fading and noise. Our algorithm is theoretically and experimentally verified to be much more robust to the ill-conditioned problems with faster convergence compared with other benchmark FL algorithms.
Learning One-hidden-layer neural networks via Provable Gradient Descent with Random Initialization
Jul 16, 2019
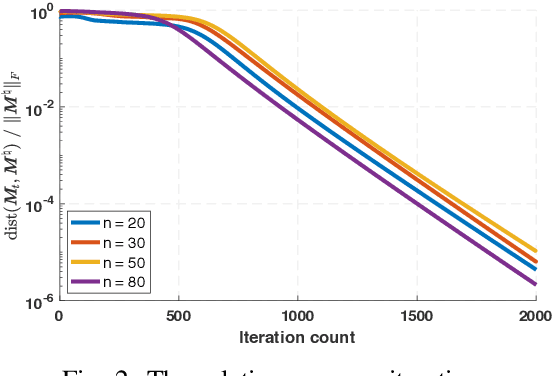


Although deep learning has shown its powerful performance in many applications, the mathematical principles behind neural networks are still mysterious. In this paper, we consider the problem of learning a one-hidden-layer neural network with quadratic activations. We focus on the under-parameterized regime where the number of hidden units is smaller than the dimension of the inputs. We shall propose to solve the problem via a provable gradient-based method with random initialization. For the non-convex neural networks training problem we reveal that the gradient descent iterates are able to enter a local region that enjoys strong convexity and smoothness within a few iterations, and then provably converges to a globally optimal model at a linear rate with near-optimal sample complexity. We further corroborate our theoretical findings via various experiments.