 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnseen Cost of Space Computing: Quantifying LEO Battery Aging via Physics-Driven Modeling
Mar 04, 2026Low Earth Orbit (LEO) satellite constellations in the 6G era are evolving into intelligent in-orbit computational platforms, forming Space Computing Power Networks (SCPNs) to deliver global-scale computing services. However, the intensive computation within SCPN incurs a significant ``unseen cost'': the frequent charge-discharge cycles accelerate the physical degradation of satellites' life-limiting and high-cost batteries, thereby threatening the long-term operational viability of such a system. Existing approaches, often relying on indirect metrics like Depth of Discharge (DoD) and neglecting the complex, nonlinear degradation process of battery aging, fail to accurately quantify this cost. To address this, we introduce a high-fidelity, physics-driven model that quantitatively links computational workload parameters to the nonlinear battery degradation. Building on this model, we formulate a degradation-aware scheduling problem and analyze heuristic policies across different energy regimes. Simulations reveal that the optimal strategy should be adaptive: in solar-rich conditions, a myopic policy maximizing instantaneous solar utilization is superior, whereas under energy scarcity, a reactive policy leveraging real-time battery state significantly extends lifetime.
Edge Large AI Models: Revolutionizing 6G Networks
May 01, 2025Large artificial intelligence models (LAMs) possess human-like abilities to solve a wide range of real-world problems, exemplifying the potential of experts in various domains and modalities. By leveraging the communication and computation capabilities of geographically dispersed edge devices, edge LAM emerges as an enabling technology to empower the delivery of various real-time intelligent services in 6G. Unlike traditional edge artificial intelligence (AI) that primarily supports a single task using small models, edge LAM is featured by the need of the decomposition and distributed deployment of large models, and the ability to support highly generalized and diverse tasks. However, due to limited communication, computation, and storage resources over wireless networks, the vast number of trainable neurons and the substantial communication overhead pose a formidable hurdle to the practical deployment of edge LAMs. In this paper, we investigate the opportunities and challenges of edge LAMs from the perspectives of model decomposition and resource management. Specifically, we propose collaborative fine-tuning and full-parameter training frameworks, alongside a microservice-assisted inference architecture, to enhance the deployment of edge LAM over wireless networks. Additionally, we investigate the application of edge LAM in air-interface designs, focusing on channel prediction and beamforming. These innovative frameworks and applications offer valuable insights and solutions for advancing 6G technology.
Satellite Edge Artificial Intelligence with Large Models: Architectures and Technologies
Apr 02, 2025Driven by the growing demand for intelligent remote sensing applications, large artificial intelligence (AI) models pre-trained on large-scale unlabeled datasets and fine-tuned for downstream tasks have significantly improved learning performance for various downstream tasks due to their generalization capabilities. However, many specific downstream tasks, such as extreme weather nowcasting (e.g., downburst and tornado), disaster monitoring, and battlefield surveillance, require real-time data processing. Traditional methods via transferring raw data to ground stations for processing often cause significant issues in terms of latency and trustworthiness. To address these challenges, satellite edge AI provides a paradigm shift from ground-based to on-board data processing by leveraging the integrated communication-and-computation capabilities in space computing power networks (Space-CPN), thereby enhancing the timeliness, effectiveness, and trustworthiness for remote sensing downstream tasks. Moreover, satellite edge large AI model (LAM) involves both the training (i.e., fine-tuning) and inference phases, where a key challenge lies in developing computation task decomposition principles to support scalable LAM deployment in resource-constrained space networks with time-varying topologies. In this article, we first propose a satellite federated fine-tuning architecture to split and deploy the modules of LAM over space and ground networks for efficient LAM fine-tuning. We then introduce a microservice-empowered satellite edge LAM inference architecture that virtualizes LAM components into lightweight microservices tailored for multi-task multimodal inference. Finally, we discuss the future directions for enhancing the efficiency and scalability of satellite edge LAM, including task-oriented communication, brain-inspired computing, and satellite edge AI network optimization.
Partial Knowledge Distillation for Alleviating the Inherent Inter-Class Discrepancy in Federated Learning
Nov 23, 2024



Substantial efforts have been devoted to alleviating the impact of the long-tailed class distribution in federated learning. In this work, we observe an interesting phenomenon that weak classes consistently exist even for class-balanced learning. These weak classes, different from the minority classes in the previous works, are inherent to data and remain fairly consistent for various network structures and learning paradigms. The inherent inter-class accuracy discrepancy can reach over 36.9% for federated learning on the FashionMNIST and CIFAR-10 datasets, even when the class distribution is balanced both globally and locally. In this study, we empirically analyze the potential reason for this phenomenon. Furthermore, a class-specific partial knowledge distillation method is proposed to improve the model's classification accuracy for weak classes. In this approach, knowledge transfer is initiated upon the occurrence of specific misclassifications within certain weak classes. Experimental results show that the accuracy of weak classes can be improved by 10.7%, reducing the inherent interclass discrepancy effectively.
Hierarchical Learning and Computing over Space-Ground Integrated Networks
Aug 26, 2024



Space-ground integrated networks hold great promise for providing global connectivity, particularly in remote areas where large amounts of valuable data are generated by Internet of Things (IoT) devices, but lacking terrestrial communication infrastructure. The massive data is conventionally transferred to the cloud server for centralized artificial intelligence (AI) models training, raising huge communication overhead and privacy concerns. To address this, we propose a hierarchical learning and computing framework, which leverages the lowlatency characteristic of low-earth-orbit (LEO) satellites and the global coverage of geostationary-earth-orbit (GEO) satellites, to provide global aggregation services for locally trained models on ground IoT devices. Due to the time-varying nature of satellite network topology and the energy constraints of LEO satellites, efficiently aggregating the received local models from ground devices on LEO satellites is highly challenging. By leveraging the predictability of inter-satellite connectivity, modeling the space network as a directed graph, we formulate a network energy minimization problem for model aggregation, which turns out to be a Directed Steiner Tree (DST) problem. We propose a topologyaware energy-efficient routing (TAEER) algorithm to solve the DST problem by finding a minimum spanning arborescence on a substitute directed graph. Extensive simulations under realworld space-ground integrated network settings demonstrate that the proposed TAEER algorithm significantly reduces energy consumption and outperforms benchmarks.
Satellite Federated Edge Learning: Architecture Design and Convergence Analysis
Apr 02, 2024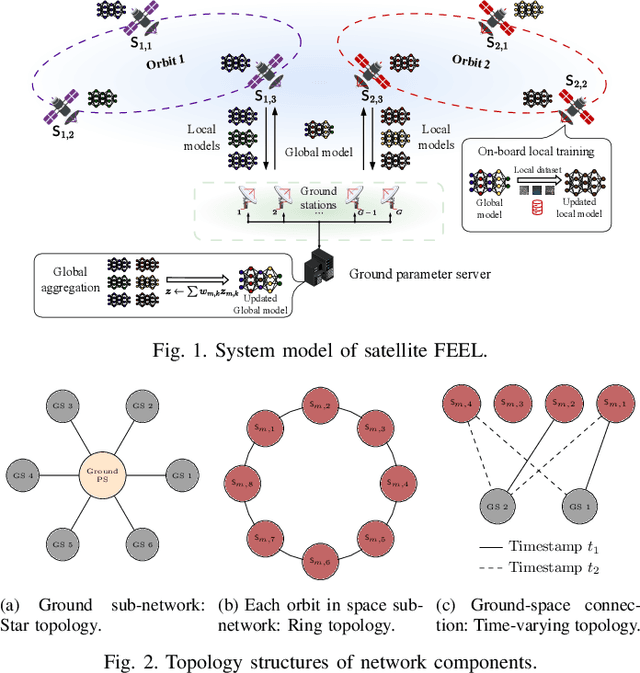
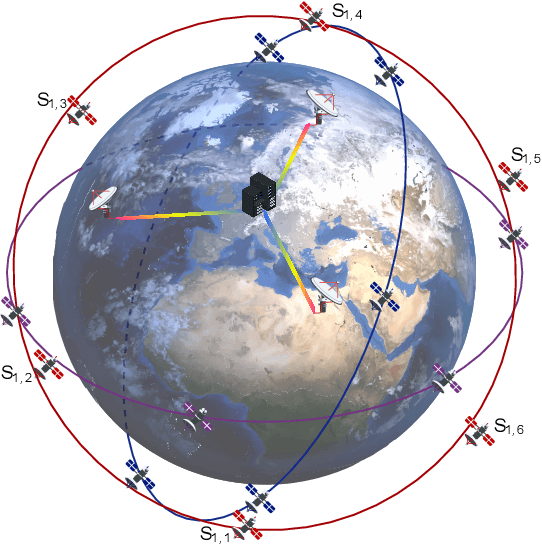
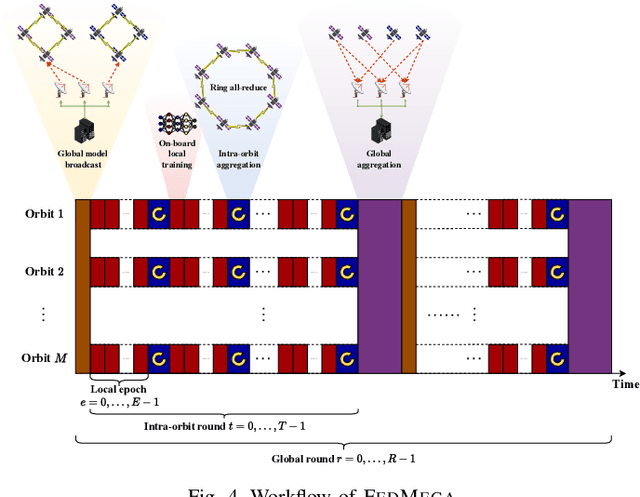
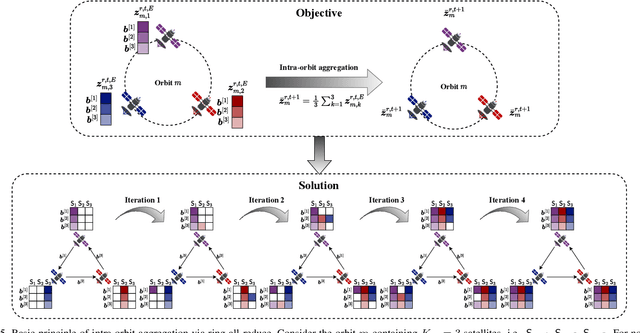
The proliferation of low-earth-orbit (LEO) satellite networks leads to the generation of vast volumes of remote sensing data which is traditionally transferred to the ground server for centralized processing, raising privacy and bandwidth concerns. Federated edge learning (FEEL), as a distributed machine learning approach, has the potential to address these challenges by sharing only model parameters instead of raw data. Although promising, the dynamics of LEO networks, characterized by the high mobility of satellites and short ground-to-satellite link (GSL) duration, pose unique challenges for FEEL. Notably, frequent model transmission between the satellites and ground incurs prolonged waiting time and large transmission latency. This paper introduces a novel FEEL algorithm, named FEDMEGA, tailored to LEO mega-constellation networks. By integrating inter-satellite links (ISL) for intra-orbit model aggregation, the proposed algorithm significantly reduces the usage of low data rate and intermittent GSL. Our proposed method includes a ring all-reduce based intra-orbit aggregation mechanism, coupled with a network flow-based transmission scheme for global model aggregation, which enhances transmission efficiency. Theoretical convergence analysis is provided to characterize the algorithm performance. Extensive simulations show that our FEDMEGA algorithm outperforms existing satellite FEEL algorithms, exhibiting an approximate 30% improvement in convergence rate.
Over-the-Air Federated Learning and Optimization
Oct 16, 2023Federated learning (FL), as an emerging distributed machine learning paradigm, allows a mass of edge devices to collaboratively train a global model while preserving privacy. In this tutorial, we focus on FL via over-the-air computation (AirComp), which is proposed to reduce the communication overhead for FL over wireless networks at the cost of compromising in the learning performance due to model aggregation error arising from channel fading and noise. We first provide a comprehensive study on the convergence of AirComp-based FedAvg (AirFedAvg) algorithms under both strongly convex and non-convex settings with constant and diminishing learning rates in the presence of data heterogeneity. Through convergence and asymptotic analysis, we characterize the impact of aggregation error on the convergence bound and provide insights for system design with convergence guarantees. Then we derive convergence rates for AirFedAvg algorithms for strongly convex and non-convex objectives. For different types of local updates that can be transmitted by edge devices (i.e., local model, gradient, and model difference), we reveal that transmitting local model in AirFedAvg may cause divergence in the training procedure. In addition, we consider more practical signal processing schemes to improve the communication efficiency and further extend the convergence analysis to different forms of model aggregation error caused by these signal processing schemes. Extensive simulation results under different settings of objective functions, transmitted local information, and communication schemes verify the theoretical conclusions.
Tight Compression: Compressing CNN Through Fine-Grained Pruning and Weight Permutation for Efficient Implementation
Apr 03, 2021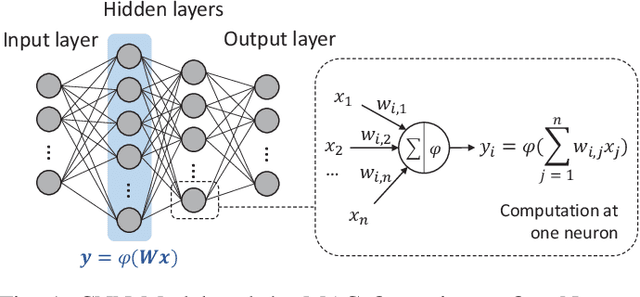
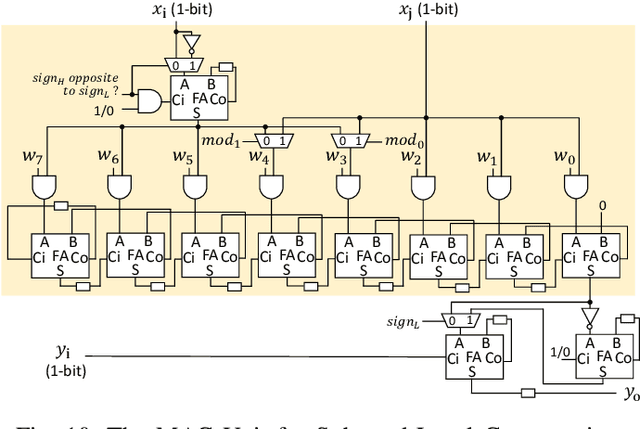

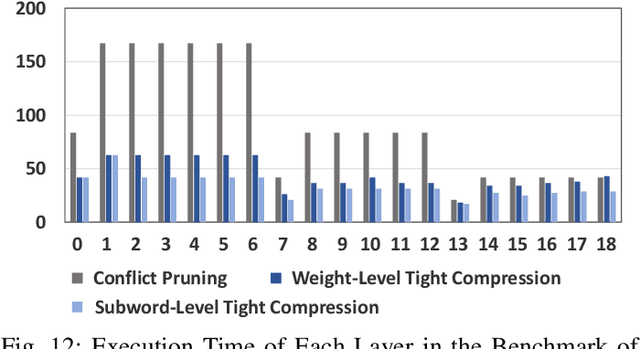
The unstructured sparsity after pruning poses a challenge to the efficient implementation of deep learning models in existing regular architectures like systolic arrays. On the other hand, coarse-grained structured pruning is suitable for implementation in regular architectures but tends to have higher accuracy loss than unstructured pruning when the pruned models are of the same size. In this work, we propose a model compression method based on a novel weight permutation scheme to fully exploit the fine-grained weight sparsity in the hardware design. Through permutation, the optimal arrangement of the weight matrix is obtained, and the sparse weight matrix is further compressed to a small and dense format to make full use of the hardware resources. Two pruning granularities are explored. In addition to the unstructured weight pruning, we also propose a more fine-grained subword-level pruning to further improve the compression performance. Compared to the state-of-the-art works, the matrix compression rate is significantly improved from 5.88x to 14.13x. As a result, the throughput and energy efficiency are improved by 2.75 and 1.86 times, respectively.
Fast Convergence Algorithm for Analog Federated Learning
Oct 30, 2020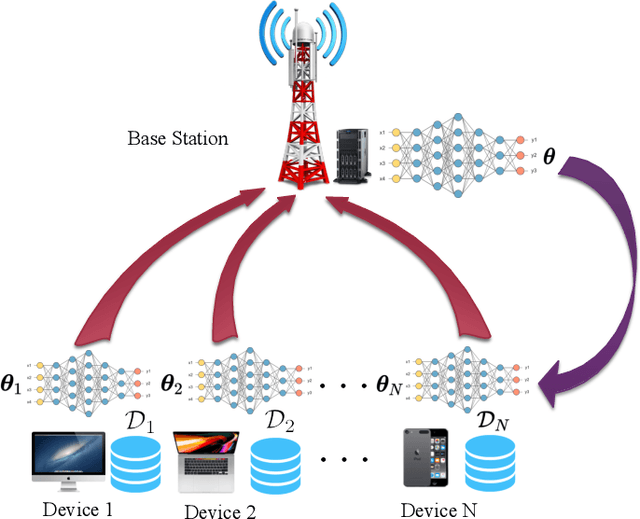
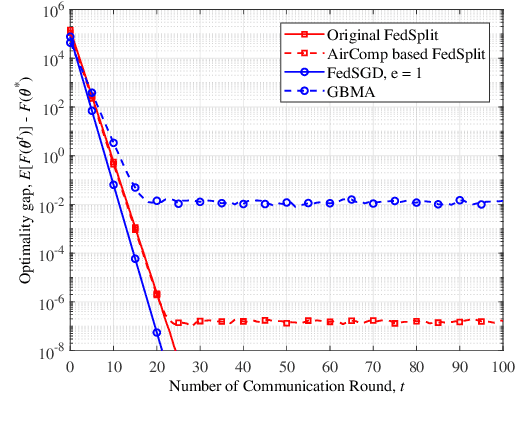
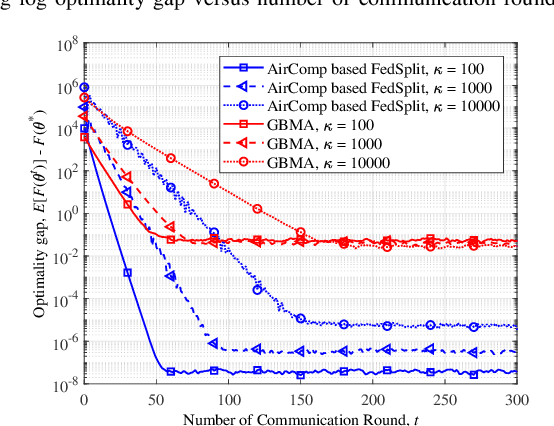
In this paper, we consider federated learning (FL) over a noisy fading multiple access channel (MAC), where an edge server aggregates the local models transmitted by multiple end devices through over-the-air computation (AirComp). To realize efficient analog federated learning over wireless channels, we propose an AirComp-based FedSplit algorithm, where a threshold-based device selection scheme is adopted to achieve reliable local model uploading. In particular, we analyze the performance of the proposed algorithm and prove that the proposed algorithm linearly converges to the optimal solutions under the assumption that the objective function is strongly convex and smooth. We also characterize the robustness of proposed algorithm to the ill-conditioned problems, thereby achieving fast convergence rates and reducing communication rounds. A finite error bound is further provided to reveal the relationship between the convergence behavior and the channel fading and noise. Our algorithm is theoretically and experimentally verified to be much more robust to the ill-conditioned problems with faster convergence compared with other benchmark FL algorithms.
SparseNN: An Energy-Efficient Neural Network Accelerator Exploiting Input and Output Sparsity
Nov 03, 2017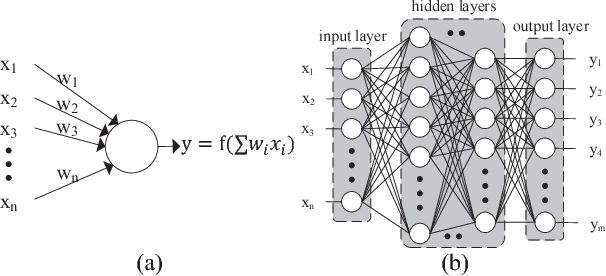
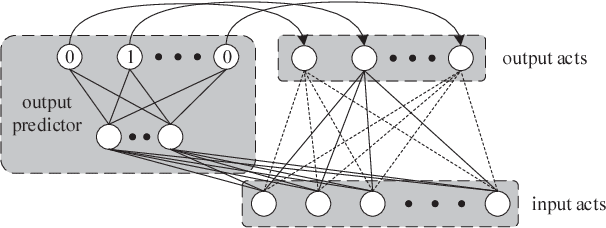

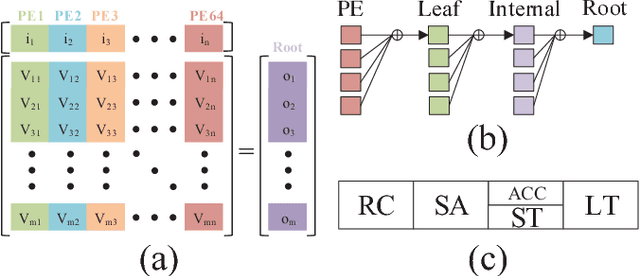
Contemporary Deep Neural Network (DNN) contains millions of synaptic connections with tens to hundreds of layers. The large computation and memory requirements pose a challenge to the hardware design. In this work, we leverage the intrinsic activation sparsity of DNN to substantially reduce the execution cycles and the energy consumption. An end-to-end training algorithm is proposed to develop a lightweight run-time predictor for the output activation sparsity on the fly. From our experimental results, the computation overhead of the prediction phase can be reduced to less than 5% of the original feedforward phase with negligible accuracy loss. Furthermore, an energy-efficient hardware architecture, SparseNN, is proposed to exploit both the input and output sparsity. SparseNN is a scalable architecture with distributed memories and processing elements connected through a dedicated on-chip network. Compared with the state-of-the-art accelerators which only exploit the input sparsity, SparseNN can achieve a 10%-70% improvement in throughput and a power reduction of around 50%.