 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Knowledge Distillation for Alleviating the Inherent Inter-Class Discrepancy in Federated Learning
Nov 23, 2024



Substantial efforts have been devoted to alleviating the impact of the long-tailed class distribution in federated learning. In this work, we observe an interesting phenomenon that weak classes consistently exist even for class-balanced learning. These weak classes, different from the minority classes in the previous works, are inherent to data and remain fairly consistent for various network structures and learning paradigms. The inherent inter-class accuracy discrepancy can reach over 36.9% for federated learning on the FashionMNIST and CIFAR-10 datasets, even when the class distribution is balanced both globally and locally. In this study, we empirically analyze the potential reason for this phenomenon. Furthermore, a class-specific partial knowledge distillation method is proposed to improve the model's classification accuracy for weak classes. In this approach, knowledge transfer is initiated upon the occurrence of specific misclassifications within certain weak classes. Experimental results show that the accuracy of weak classes can be improved by 10.7%, reducing the inherent interclass discrepancy effectively.
Tight Compression: Compressing CNN Through Fine-Grained Pruning and Weight Permutation for Efficient Implementation
Apr 03, 2021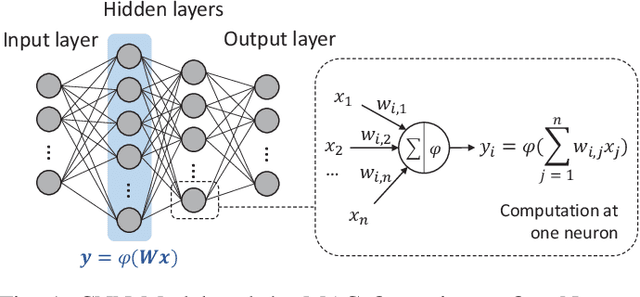
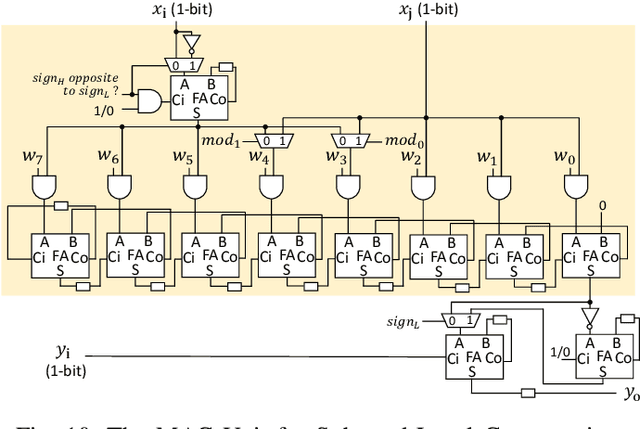

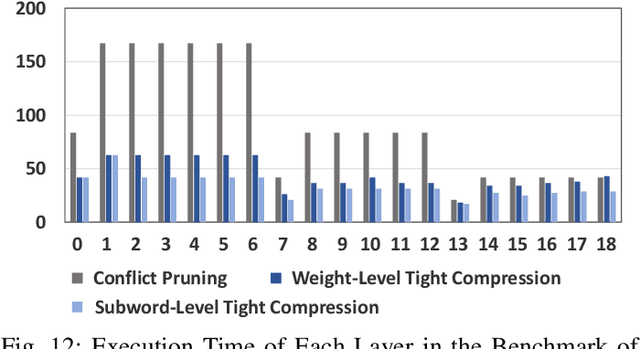
The unstructured sparsity after pruning poses a challenge to the efficient implementation of deep learning models in existing regular architectures like systolic arrays. On the other hand, coarse-grained structured pruning is suitable for implementation in regular architectures but tends to have higher accuracy loss than unstructured pruning when the pruned models are of the same size. In this work, we propose a model compression method based on a novel weight permutation scheme to fully exploit the fine-grained weight sparsity in the hardware design. Through permutation, the optimal arrangement of the weight matrix is obtained, and the sparse weight matrix is further compressed to a small and dense format to make full use of the hardware resources. Two pruning granularities are explored. In addition to the unstructured weight pruning, we also propose a more fine-grained subword-level pruning to further improve the compression performance. Compared to the state-of-the-art works, the matrix compression rate is significantly improved from 5.88x to 14.13x. As a result, the throughput and energy efficiency are improved by 2.75 and 1.86 times, respectively.
A Reconfigurable Winograd CNN Accelerator with Nesting Decomposition Algorithm for Computing Convolution with Large Filters
Feb 26, 2021
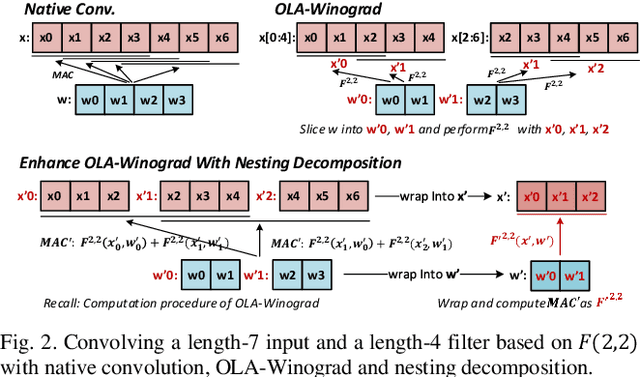
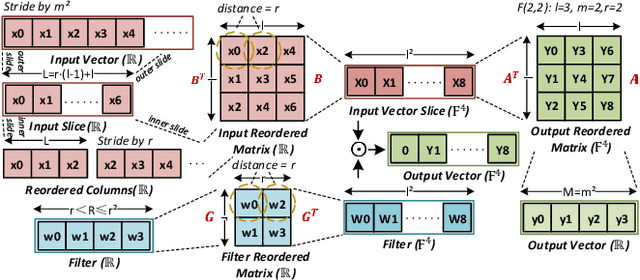
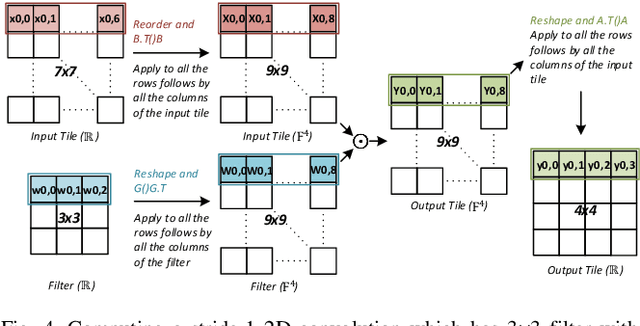
Recent literature found that convolutional neural networks (CNN) with large filters perform well in some applications such as image semantic segmentation. Winograd transformation helps to reduce the number of multiplications in a convolution but suffers from numerical instability when the convolution filter size gets large. This work proposes a nested Winograd algorithm to iteratively decompose a large filter into a sequence of 3x3 tiles which can then be accelerated with a 3x3 Winograd algorithm. Compared with the state-of-art OLA-Winograd algorithm, the proposed algorithm reduces the multiplications by 1.41 to 3.29 times for computing 5x5 to 9x9 convolutions.
A Comparison of the Taguchi Method and Evolutionary Optimization in Multivariate Testing
Aug 25, 2018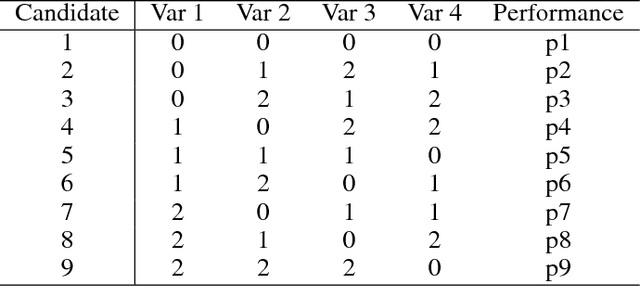
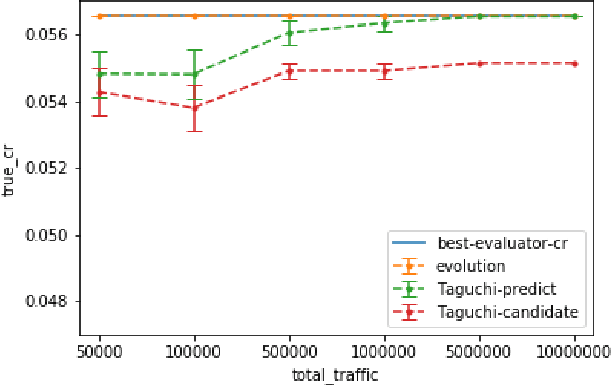


Multivariate testing has recently emerged as a promising technique in web interface design. In contrast to the standard A/B testing, multivariate approach aims at evaluating a large number of values in a few key variables systematically. The Taguchi method is a practical implementation of this idea, focusing on orthogonal combinations of values. This paper evaluates an alternative method: population-based search, i.e. evolutionary optimization. Its performance is compared to that of the Taguchi method in several simulated conditions, including an orthogonal one designed to favor the Taguchi method, and two realistic conditions with dependences between variables. Evolutionary optimization is found to perform significantly better especially in the realistic conditions, suggesting that it forms a good approach for web interface design in the future.
SparseNN: An Energy-Efficient Neural Network Accelerator Exploiting Input and Output Sparsity
Nov 03, 2017
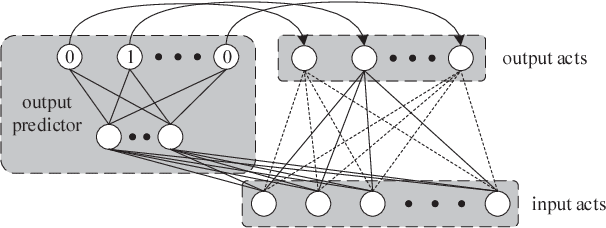

Contemporary Deep Neural Network (DNN) contains millions of synaptic connections with tens to hundreds of layers. The large computation and memory requirements pose a challenge to the hardware design. In this work, we leverage the intrinsic activation sparsity of DNN to substantially reduce the execution cycles and the energy consumption. An end-to-end training algorithm is proposed to develop a lightweight run-time predictor for the output activation sparsity on the fly. From our experimental results, the computation overhead of the prediction phase can be reduced to less than 5% of the original feedforward phase with negligible accuracy loss. Furthermore, an energy-efficient hardware architecture, SparseNN, is proposed to exploit both the input and output sparsity. SparseNN is a scalable architecture with distributed memories and processing elements connected through a dedicated on-chip network. Compared with the state-of-the-art accelerators which only exploit the input sparsity, SparseNN can achieve a 10%-70% improvement in throughput and a power reduction of around 50%.