 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Deep Learning Paradigm for Airborne Transient Electromagnetic Inversion
Mar 28, 2025



The extraction of geoelectric structural information from airborne transient electromagnetic(ATEM)data primarily involves data processing and inversion. Conventional methods rely on empirical parameter selection, making it difficult to process complex field data with high noise levels. Additionally, inversion computations are time consuming and often suffer from multiple local minima. Existing deep learning-based approaches separate the data processing steps, where independently trained denoising networks struggle to ensure the reliability of subsequent inversions. Moreover, end to end networks lack interpretability. To address these issues, we propose a unified and interpretable deep learning inversion paradigm based on disentangled representation learning. The network explicitly decomposes noisy data into noise and signal factors, completing the entire data processing workflow based on the signal factors while incorporating physical information for guidance. This approach enhances the network's reliability and interpretability. The inversion results on field data demonstrate that our method can directly use noisy data to accurately reconstruct the subsurface electrical structure. Furthermore, it effectively processes data severely affected by environmental noise, which traditional methods struggle with, yielding improved lateral structural resolution.
3-D Magnetotelluric Deep Learning Inversion Guided by Pseudo-Physical Information
Oct 12, 2024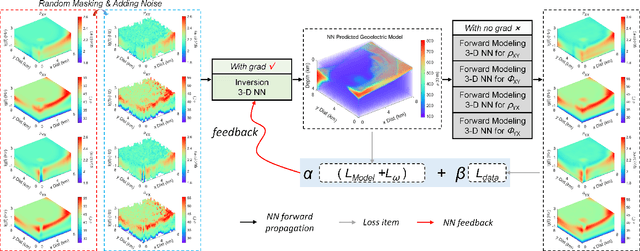
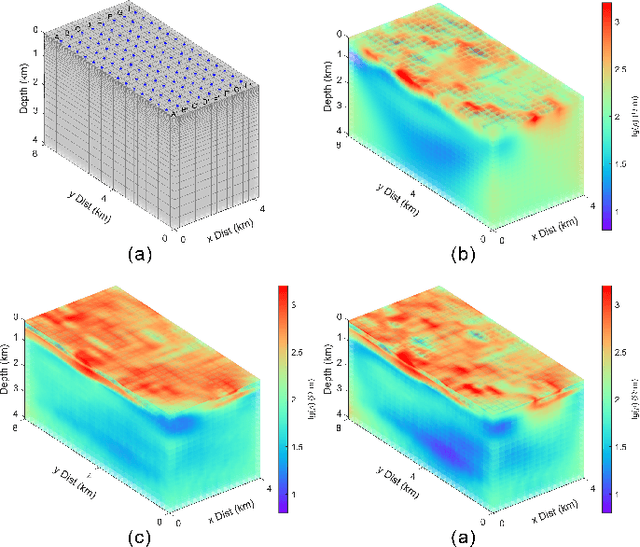
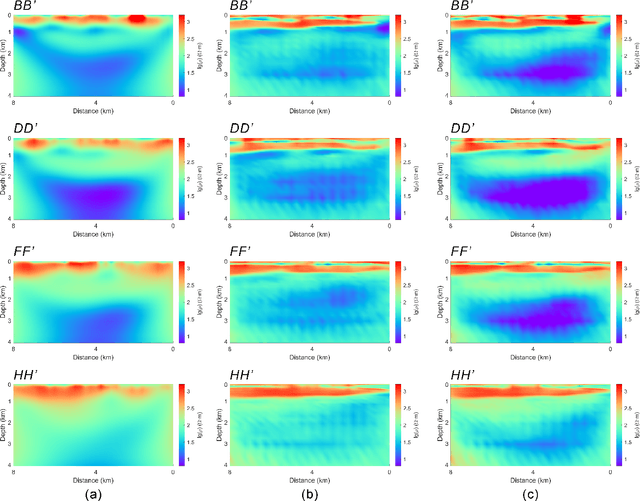
Magnetotelluric deep learning (DL) inversion methods based on joint data-driven and physics-driven have become a hot topic in recent years. When mapping observation data (or forward modeling data) to the resistivity model using neural networks (NNs), incorporating the error (loss) term of the inversion resistivity's forward modeling response--which introduces physical information about electromagnetic field propagation--can significantly enhance the inversion accuracy. To efficiently achieve data-physical dual-driven MT deep learning inversion for large-scale 3-D MT data, we propose using DL forward modeling networks to compute this portion of the loss. This approach introduces pseudo-physical information through the forward modeling of NN simulation, further guiding the inversion network fitting. Specifically, we first pre-train the forward modeling networks as fixed forward modeling operators, then transfer and integrate them into the inversion network training, and finally optimize the inversion network by minimizing the multinomial loss. Theoretical experimental results indicate that despite some simulation errors in DL forward modeling, the introduced pseudo-physical information still enhances inversion accuracy and significantly mitigates the overfitting problem during training. Additionally, we propose a new input mode that involves masking and adding noise to the data, simulating the field data environment of 3-D MT inversion, thereby making the method more flexible and effective for practical applications.
WiTUnet: A U-Shaped Architecture Integrating CNN and Transformer for Improved Feature Alignment and Local Information Fusion
Apr 15, 2024Low-dose computed tomography (LDCT) has become the technology of choice for diagnostic medical imaging, given its lower radiation dose compared to standard CT, despite increasing image noise and potentially affecting diagnostic accuracy. To address this, advanced deep learning-based LDCT denoising algorithms have been developed, primarily using Convolutional Neural Networks (CNNs) or Transformer Networks with the Unet architecture. This architecture enhances image detail by integrating feature maps from the encoder and decoder via skip connections. However, current methods often overlook enhancements to the Unet architecture itself, focusing instead on optimizing encoder and decoder structures. This approach can be problematic due to the significant differences in feature map characteristics between the encoder and decoder, where simple fusion strategies may not effectively reconstruct images.In this paper, we introduce WiTUnet, a novel LDCT image denoising method that utilizes nested, dense skip pathways instead of traditional skip connections to improve feature integration. WiTUnet also incorporates a windowed Transformer structure to process images in smaller, non-overlapping segments, reducing computational load. Additionally, the integration of a Local Image Perception Enhancement (LiPe) module in both the encoder and decoder replaces the standard multi-layer perceptron (MLP) in Transformers, enhancing local feature capture and representation. Through extensive experimental comparisons, WiTUnet has demonstrated superior performance over existing methods in key metrics such as Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM), and Root Mean Square Error (RMSE), significantly improving noise removal and image quality.
SeisFusion: Constrained Diffusion Model with Input Guidance for 3D Seismic Data Interpolation and Reconstruction
Mar 18, 2024Geographical, physical, or economic constraints often result in missing traces within seismic data, making the reconstruction of complete seismic data a crucial step in seismic data processing. Traditional methods for seismic data reconstruction require the selection of multiple empirical parameters and struggle to handle large-scale continuous missing data. With the development of deep learning, various neural networks have demonstrated powerful reconstruction capabilities. However, these convolutional neural networks represent a point-to-point reconstruction approach that may not cover the entire distribution of the dataset. Consequently, when dealing with seismic data featuring complex missing patterns, such networks may experience varying degrees of performance degradation. In response to this challenge, we propose a novel diffusion model reconstruction framework tailored for 3D seismic data. To constrain the results generated by the diffusion model, we introduce conditional supervision constraints into the diffusion model, constraining the generated data of the diffusion model based on the input data to be reconstructed. We introduce a 3D neural network architecture into the diffusion model, successfully extending the 2D diffusion model to 3D space. Additionally, we refine the model's generation process by incorporating missing data into the generation process, resulting in reconstructions with higher consistency. Through ablation studies determining optimal parameter values, our method exhibits superior reconstruction accuracy when applied to both field datasets and synthetic datasets, effectively addressing a wide range of complex missing patterns. Our implementation is available at https://github.com/WAL-l/SeisFusion.