 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Segment Anything Model to Multi-modal Salient Object Detection with Semantic Feature Fusion Guidance
Paper and Code
Aug 27, 2024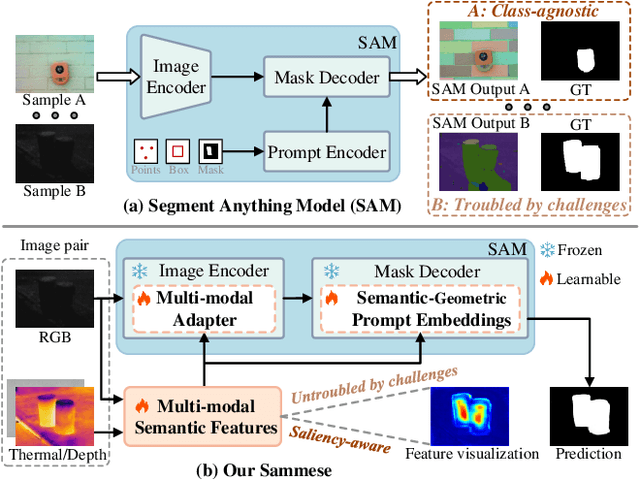
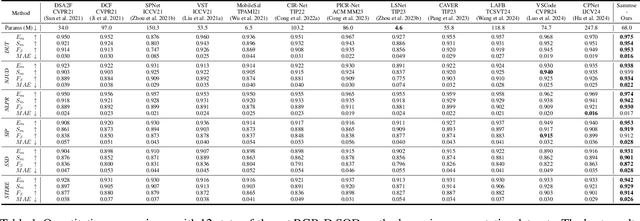
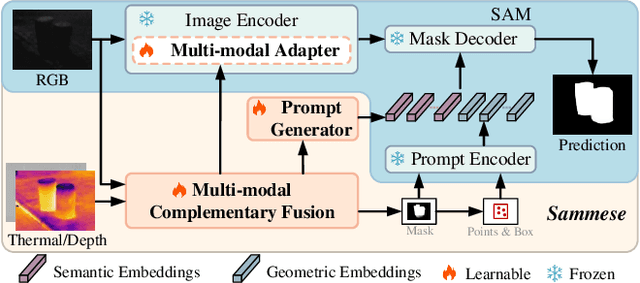

Although most existing multi-modal salient object detection (SOD) methods demonstrate effectiveness through training models from scratch, the limited multi-modal data hinders these methods from reaching optimality. In this paper, we propose a novel framework to explore and exploit the powerful feature representation and zero-shot generalization ability of the pre-trained Segment Anything Model (SAM) for multi-modal SOD. Despite serving as a recent vision fundamental model, driving the class-agnostic SAM to comprehend and detect salient objects accurately is non-trivial, especially in challenging scenes. To this end, we develop \underline{SAM} with se\underline{m}antic f\underline{e}ature fu\underline{s}ion guidanc\underline{e} (Sammese), which incorporates multi-modal saliency-specific knowledge into SAM to adapt SAM to multi-modal SOD tasks. However, it is difficult for SAM trained on single-modal data to directly mine the complementary benefits of multi-modal inputs and comprehensively utilize them to achieve accurate saliency prediction.To address these issues, we first design a multi-modal complementary fusion module to extract robust multi-modal semantic features by integrating information from visible and thermal or depth image pairs. Then, we feed the extracted multi-modal semantic features into both the SAM image encoder and mask decoder for fine-tuning and prompting, respectively. Specifically, in the image encoder, a multi-modal adapter is proposed to adapt the single-modal SAM to multi-modal information. In the mask decoder, a semantic-geometric prompt generation strategy is proposed to produce corresponding embeddings with various saliency cues. Extensive experiments on both RGB-D and RGB-T SOD benchmarks show the effectiveness of the proposed framework.