 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnzyPGM: Pocket-conditioned Generative Model for Substrate-specific Enzyme Design
Jan 27, 2026Designing enzymes with substrate-binding pockets is a critical challenge in protein engineering, as catalytic activity depends on the precise interaction between pockets and substrates. Currently, generative models dominate functional protein design but cannot model pocket-substrate interactions, which limits the generation of enzymes with precise catalytic environments. To address this issue, we propose EnzyPGM, a unified framework that jointly generates enzymes and substrate-binding pockets conditioned on functional priors and substrates, with a particular focus on learning accurate pocket-substrate interactions. At its core, EnzyPGM includes two main modules: a Residue-atom Bi-scale Attention (RBA) that jointly models intra-residue dependencies and fine-grained interactions between pocket residues and substrate atoms, and a Residue Function Fusion (RFF) that incorporates enzyme function priors into residue representations. Also, we curate EnzyPock, an enzyme-pocket dataset comprising 83,062 enzyme-substrate pairs across 1,036 four-level enzyme families. Extensive experiments demonstrate that EnzyPGM achieves state-of-the-art performance on EnzyPock. Notably, EnzyPGM reduces the average binding energy of 0.47 kcal/mol over EnzyGen, showing its superior performance on substrate-specific enzyme design. The code and dataset will be released later.
R$^2$: A LLM Based Novel-to-Screenplay Generation Framework with Causal Plot Graphs
Mar 19, 2025



Automatically adapting novels into screenplays is important for the TV, film, or opera industries to promote products with low costs. The strong performances of large language models (LLMs) in long-text generation call us to propose a LLM based framework Reader-Rewriter (R$^2$) for this task. However, there are two fundamental challenges here. First, the LLM hallucinations may cause inconsistent plot extraction and screenplay generation. Second, the causality-embedded plot lines should be effectively extracted for coherent rewriting. Therefore, two corresponding tactics are proposed: 1) A hallucination-aware refinement method (HAR) to iteratively discover and eliminate the affections of hallucinations; and 2) a causal plot-graph construction method (CPC) based on a greedy cycle-breaking algorithm to efficiently construct plot lines with event causalities. Recruiting those efficient techniques, R$^2$ utilizes two modules to mimic the human screenplay rewriting process: The Reader module adopts a sliding window and CPC to build the causal plot graphs, while the Rewriter module generates first the scene outlines based on the graphs and then the screenplays. HAR is integrated into both modules for accurate inferences of LLMs. Experimental results demonstrate the superiority of R$^2$, which substantially outperforms three existing approaches (51.3%, 22.6%, and 57.1% absolute increases) in pairwise comparison at the overall win rate for GPT-4o.
LFSamba: Marry SAM with Mamba for Light Field Salient Object Detection
Nov 11, 2024



A light field camera can reconstruct 3D scenes using captured multi-focus images that contain rich spatial geometric information, enhancing applications in stereoscopic photography, virtual reality, and robotic vision. In this work, a state-of-the-art salient object detection model for multi-focus light field images, called LFSamba, is introduced to emphasize four main insights: (a) Efficient feature extraction, where SAM is used to extract modality-aware discriminative features; (b) Inter-slice relation modeling, leveraging Mamba to capture long-range dependencies across multiple focal slices, thus extracting implicit depth cues; (c) Inter-modal relation modeling, utilizing Mamba to integrate all-focus and multi-focus images, enabling mutual enhancement; (d) Weakly supervised learning capability, developing a scribble annotation dataset from an existing pixel-level mask dataset, establishing the first scribble-supervised baseline for light field salient object detection.https://github.com/liuzywen/LFScribble
SSFam: Scribble Supervised Salient Object Detection Family
Sep 07, 2024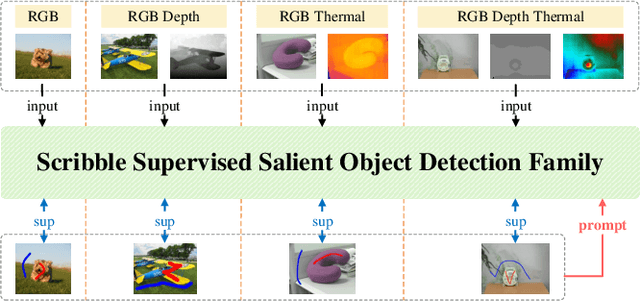
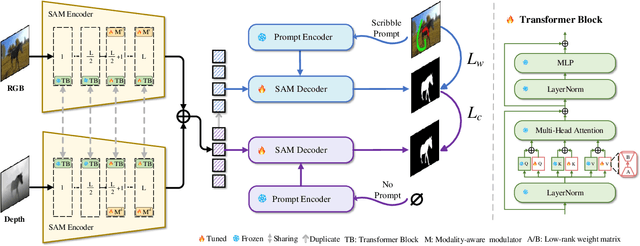
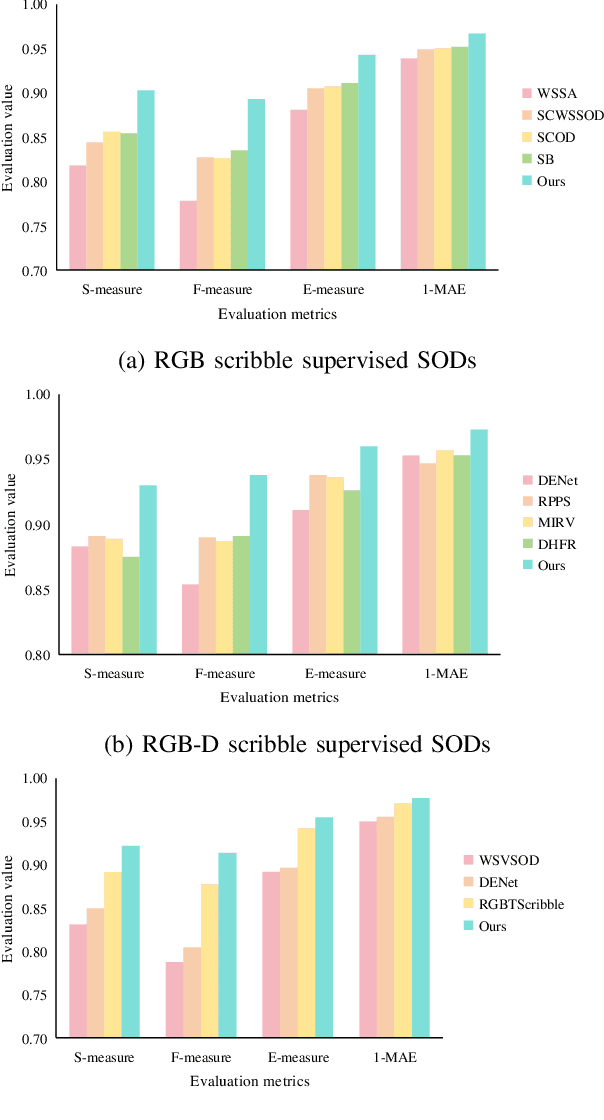

Scribble supervised salient object detection (SSSOD) constructs segmentation ability of attractive objects from surroundings under the supervision of sparse scribble labels. For the better segmentation, depth and thermal infrared modalities serve as the supplement to RGB images in the complex scenes. Existing methods specifically design various feature extraction and multi-modal fusion strategies for RGB, RGB-Depth, RGB-Thermal, and Visual-Depth-Thermal image input respectively, leading to similar model flood. As the recently proposed Segment Anything Model (SAM) possesses extraordinary segmentation and prompt interactive capability, we propose an SSSOD family based on SAM, named SSFam, for the combination input with different modalities. Firstly, different modal-aware modulators are designed to attain modal-specific knowledge which cooperates with modal-agnostic information extracted from the frozen SAM encoder for the better feature ensemble. Secondly, a siamese decoder is tailored to bridge the gap between the training with scribble prompt and the testing with no prompt for the stronger decoding ability. Our model demonstrates the remarkable performance among combinations of different modalities and refreshes the highest level of scribble supervised methods and comes close to the ones of fully supervised methods. https://github.com/liuzywen/SSFam
Local Consensus Enhanced Siamese Network with Reciprocal Loss for Two-view Correspondence Learning
Aug 06, 2023



Recent studies of two-view correspondence learning usually establish an end-to-end network to jointly predict correspondence reliability and relative pose. We improve such a framework from two aspects. First, we propose a Local Feature Consensus (LFC) plugin block to augment the features of existing models. Given a correspondence feature, the block augments its neighboring features with mutual neighborhood consensus and aggregates them to produce an enhanced feature. As inliers obey a uniform cross-view transformation and share more consistent learned features than outliers, feature consensus strengthens inlier correlation and suppresses outlier distraction, which makes output features more discriminative for classifying inliers/outliers. Second, existing approaches supervise network training with the ground truth correspondences and essential matrix projecting one image to the other for an input image pair, without considering the information from the reverse mapping. We extend existing models to a Siamese network with a reciprocal loss that exploits the supervision of mutual projection, which considerably promotes the matching performance without introducing additional model parameters. Building upon MSA-Net, we implement the two proposals and experimentally achieve state-of-the-art performance on benchmark datasets.
Scribble-Supervised RGB-T Salient Object Detection
Mar 17, 2023
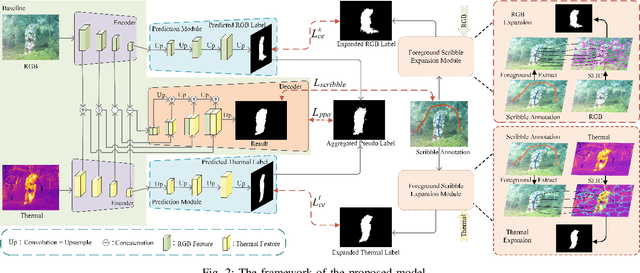


Salient object detection segments attractive objects in scenes. RGB and thermal modalities provide complementary information and scribble annotations alleviate large amounts of human labor. Based on the above facts, we propose a scribble-supervised RGB-T salient object detection model. By a four-step solution (expansion, prediction, aggregation, and supervision), label-sparse challenge of scribble-supervised method is solved. To expand scribble annotations, we collect the superpixels that foreground scribbles pass through in RGB and thermal images, respectively. The expanded multi-modal labels provide the coarse object boundary. To further polish the expanded labels, we propose a prediction module to alleviate the sharpness of boundary. To play the complementary roles of two modalities, we combine the two into aggregated pseudo labels. Supervised by scribble annotations and pseudo labels, our model achieves the state-of-the-art performance on the relabeled RGBT-S dataset. Furthermore, the model is applied to RGB-D and video scribble-supervised applications, achieving consistently excellent performance.
The Z-axis, X-axis, Weight and Disambiguation Methods for Constructing Local Reference Frame in 3D Registration: An Evaluation
Apr 17, 2022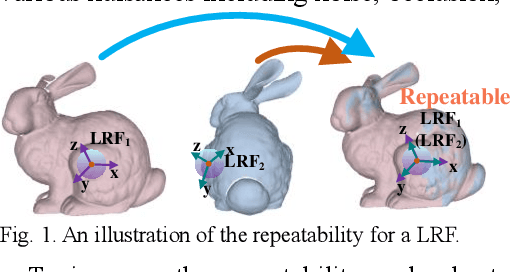
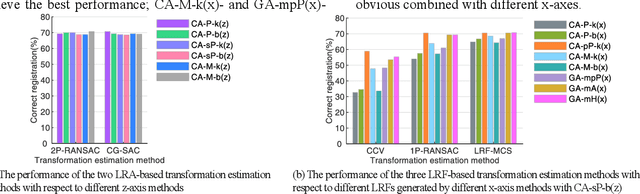
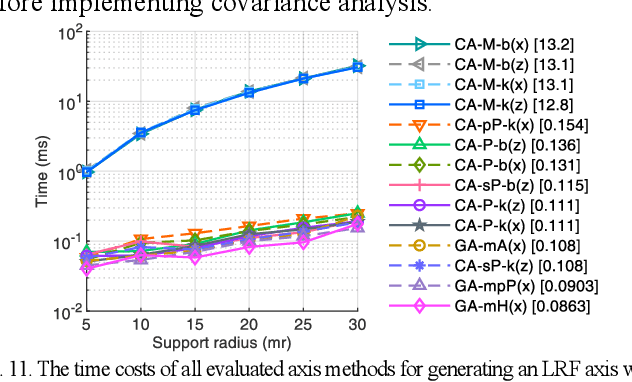
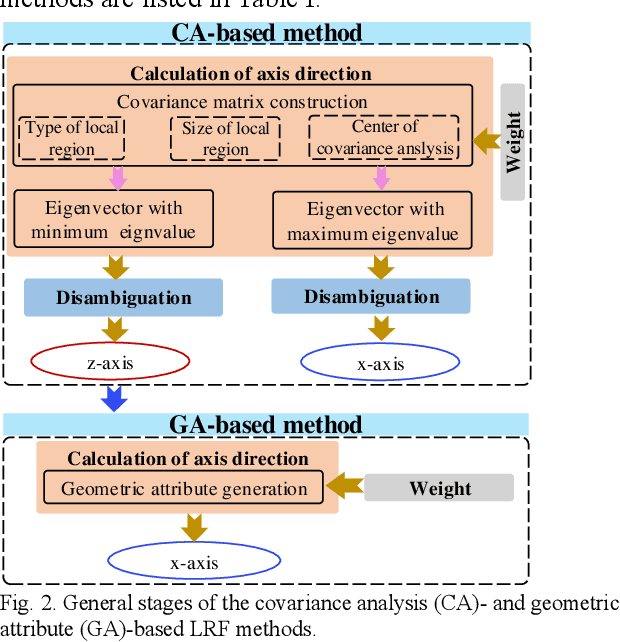
The local reference frame (LRF), as an independent coordinate system generated on a local 3D surface, is widely used in 3D local feature descriptor construction and 3D transformation estimation which are two key steps in the local method-based surface matching. There are numerous LRF methods have been proposed in literatures. In these methods, the x- and z-axis are commonly generated by different methods or strategies, and some x-axis methods are implemented on the basis of a z-axis being given. In addition, the weight and disambiguation methods are commonly used in these LRF methods. In existing evaluations of LRF, each LRF method is evaluated with a complete form. However, the merits and demerits of the z-axis, x-axis, weight and disambiguation methods in LRF construction are unclear. In this paper, we comprehensively analyze the z-axis, x-axis, weight and disambiguation methods in existing LRFs, and obtain six z-axis and eight x-axis, five weight and two disambiguation methods. The performance of these methods are comprehensively evaluated on six standard datasets with different application scenarios and nuisances. Considering the evaluation outcomes, the merits and demerits of different weight, disambiguation, z- and x-axis methods are analyzed and summarized. The experimental result also shows that some new designed LRF axes present superior performance compared with the state-of-the-art ones.