 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScribble-Supervised RGB-T Salient Object Detection
Mar 17, 2023
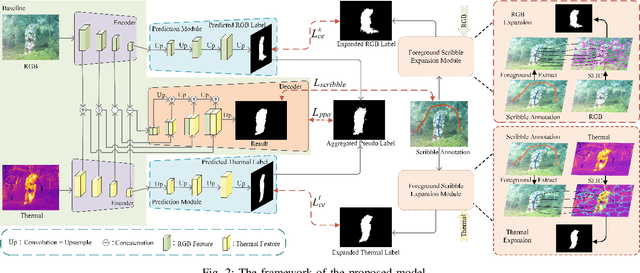


Salient object detection segments attractive objects in scenes. RGB and thermal modalities provide complementary information and scribble annotations alleviate large amounts of human labor. Based on the above facts, we propose a scribble-supervised RGB-T salient object detection model. By a four-step solution (expansion, prediction, aggregation, and supervision), label-sparse challenge of scribble-supervised method is solved. To expand scribble annotations, we collect the superpixels that foreground scribbles pass through in RGB and thermal images, respectively. The expanded multi-modal labels provide the coarse object boundary. To further polish the expanded labels, we propose a prediction module to alleviate the sharpness of boundary. To play the complementary roles of two modalities, we combine the two into aggregated pseudo labels. Supervised by scribble annotations and pseudo labels, our model achieves the state-of-the-art performance on the relabeled RGBT-S dataset. Furthermore, the model is applied to RGB-D and video scribble-supervised applications, achieving consistently excellent performance.