 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLFSamba: Marry SAM with Mamba for Light Field Salient Object Detection
Nov 11, 2024



A light field camera can reconstruct 3D scenes using captured multi-focus images that contain rich spatial geometric information, enhancing applications in stereoscopic photography, virtual reality, and robotic vision. In this work, a state-of-the-art salient object detection model for multi-focus light field images, called LFSamba, is introduced to emphasize four main insights: (a) Efficient feature extraction, where SAM is used to extract modality-aware discriminative features; (b) Inter-slice relation modeling, leveraging Mamba to capture long-range dependencies across multiple focal slices, thus extracting implicit depth cues; (c) Inter-modal relation modeling, utilizing Mamba to integrate all-focus and multi-focus images, enabling mutual enhancement; (d) Weakly supervised learning capability, developing a scribble annotation dataset from an existing pixel-level mask dataset, establishing the first scribble-supervised baseline for light field salient object detection.https://github.com/liuzywen/LFScribble
SSFam: Scribble Supervised Salient Object Detection Family
Sep 07, 2024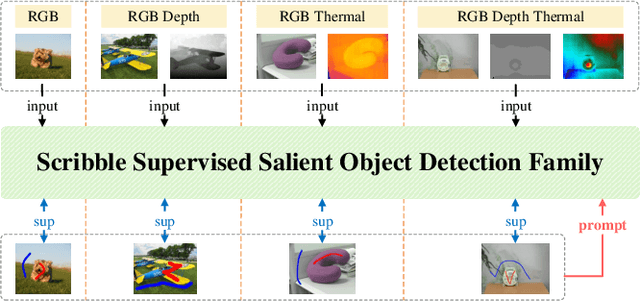
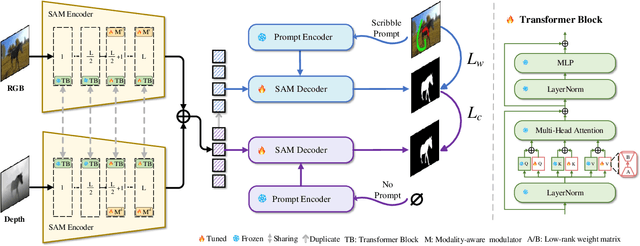
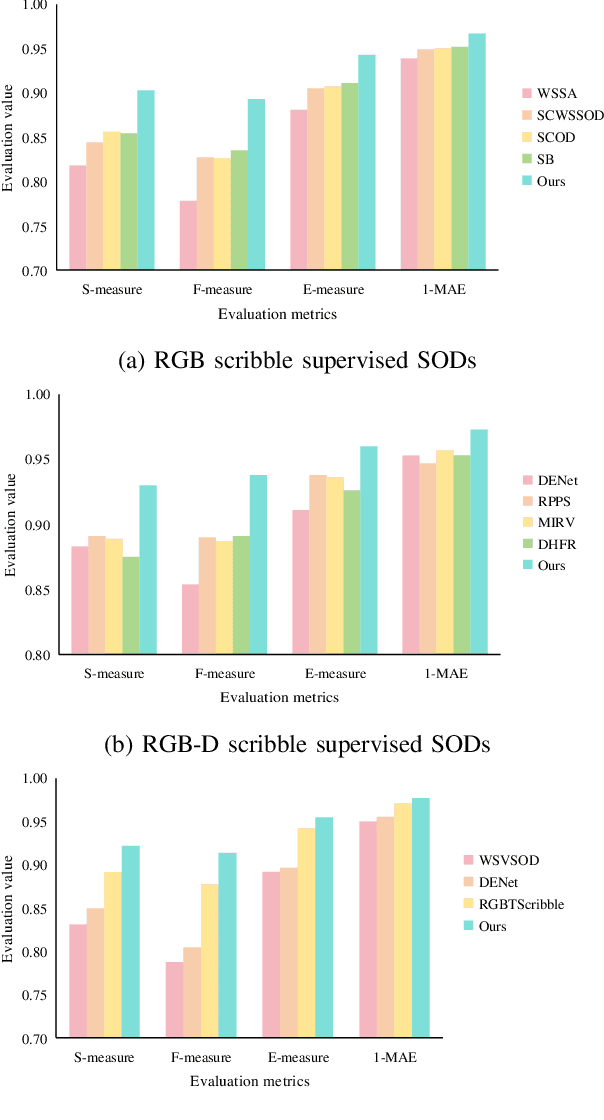

Scribble supervised salient object detection (SSSOD) constructs segmentation ability of attractive objects from surroundings under the supervision of sparse scribble labels. For the better segmentation, depth and thermal infrared modalities serve as the supplement to RGB images in the complex scenes. Existing methods specifically design various feature extraction and multi-modal fusion strategies for RGB, RGB-Depth, RGB-Thermal, and Visual-Depth-Thermal image input respectively, leading to similar model flood. As the recently proposed Segment Anything Model (SAM) possesses extraordinary segmentation and prompt interactive capability, we propose an SSSOD family based on SAM, named SSFam, for the combination input with different modalities. Firstly, different modal-aware modulators are designed to attain modal-specific knowledge which cooperates with modal-agnostic information extracted from the frozen SAM encoder for the better feature ensemble. Secondly, a siamese decoder is tailored to bridge the gap between the training with scribble prompt and the testing with no prompt for the stronger decoding ability. Our model demonstrates the remarkable performance among combinations of different modalities and refreshes the highest level of scribble supervised methods and comes close to the ones of fully supervised methods. https://github.com/liuzywen/SSFam
Local Consensus Enhanced Siamese Network with Reciprocal Loss for Two-view Correspondence Learning
Aug 06, 2023Recent studies of two-view correspondence learning usually establish an end-to-end network to jointly predict correspondence reliability and relative pose. We improve such a framework from two aspects. First, we propose a Local Feature Consensus (LFC) plugin block to augment the features of existing models. Given a correspondence feature, the block augments its neighboring features with mutual neighborhood consensus and aggregates them to produce an enhanced feature. As inliers obey a uniform cross-view transformation and share more consistent learned features than outliers, feature consensus strengthens inlier correlation and suppresses outlier distraction, which makes output features more discriminative for classifying inliers/outliers. Second, existing approaches supervise network training with the ground truth correspondences and essential matrix projecting one image to the other for an input image pair, without considering the information from the reverse mapping. We extend existing models to a Siamese network with a reciprocal loss that exploits the supervision of mutual projection, which considerably promotes the matching performance without introducing additional model parameters. Building upon MSA-Net, we implement the two proposals and experimentally achieve state-of-the-art performance on benchmark datasets.
Scribble-Supervised RGB-T Salient Object Detection
Mar 17, 2023
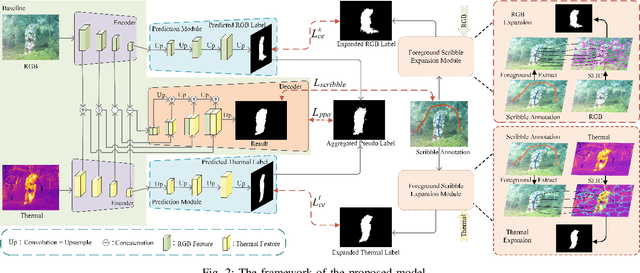


Salient object detection segments attractive objects in scenes. RGB and thermal modalities provide complementary information and scribble annotations alleviate large amounts of human labor. Based on the above facts, we propose a scribble-supervised RGB-T salient object detection model. By a four-step solution (expansion, prediction, aggregation, and supervision), label-sparse challenge of scribble-supervised method is solved. To expand scribble annotations, we collect the superpixels that foreground scribbles pass through in RGB and thermal images, respectively. The expanded multi-modal labels provide the coarse object boundary. To further polish the expanded labels, we propose a prediction module to alleviate the sharpness of boundary. To play the complementary roles of two modalities, we combine the two into aggregated pseudo labels. Supervised by scribble annotations and pseudo labels, our model achieves the state-of-the-art performance on the relabeled RGBT-S dataset. Furthermore, the model is applied to RGB-D and video scribble-supervised applications, achieving consistently excellent performance.
Adaptively Exploiting d-Separators with Causal Bandits
Feb 10, 2022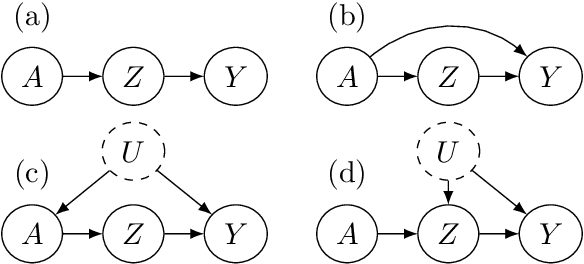
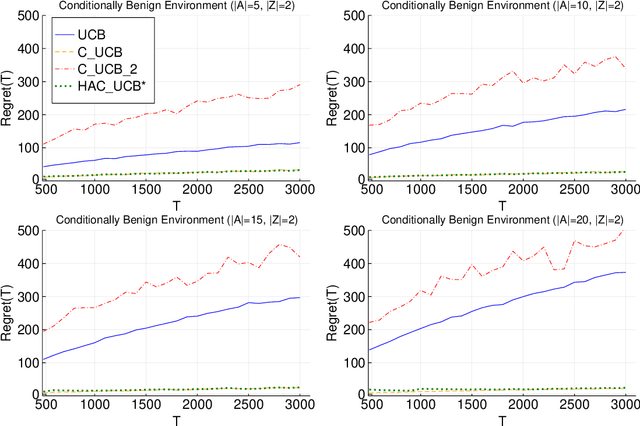
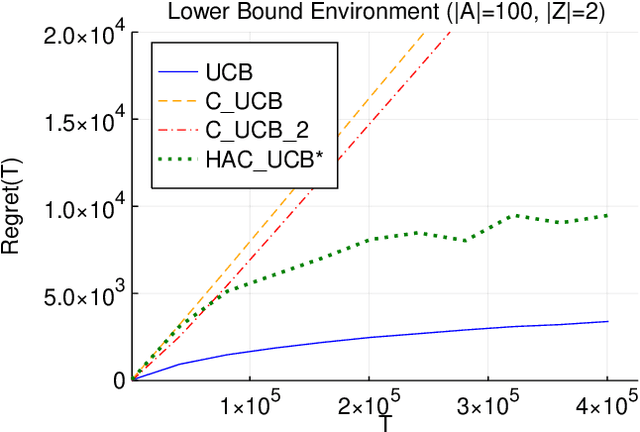
Multi-armed bandit problems provide a framework to identify the optimal intervention over a sequence of repeated experiments. Without additional assumptions, minimax optimal performance (measured by cumulative regret) is well-understood. With access to additional observed variables that d-separate the intervention from the outcome (i.e., they are a d-separator), recent causal bandit algorithms provably incur less regret. However, in practice it is desirable to be agnostic to whether observed variables are a d-separator. Ideally, an algorithm should be adaptive; that is, perform nearly as well as an algorithm with oracle knowledge of the presence or absence of a d-separator. In this work, we formalize and study this notion of adaptivity, and provide a novel algorithm that simultaneously achieves (a) optimal regret when a d-separator is observed, improving on classical minimax algorithms, and (b) significantly smaller regret than recent causal bandit algorithms when the observed variables are not a d-separator. Crucially, our algorithm does not require any oracle knowledge of whether a d-separator is observed. We also generalize this adaptivity to other conditions, such as the front-door criterion.
In Search of Robust Measures of Generalization
Oct 22, 2020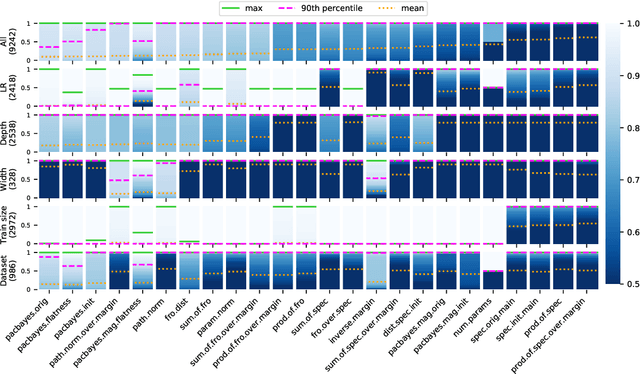
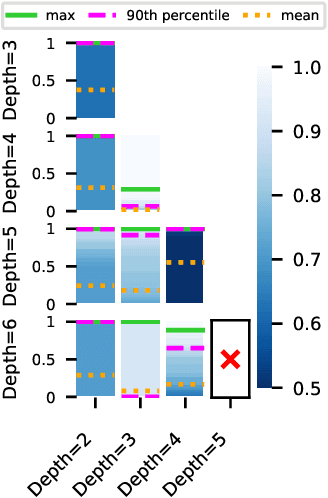
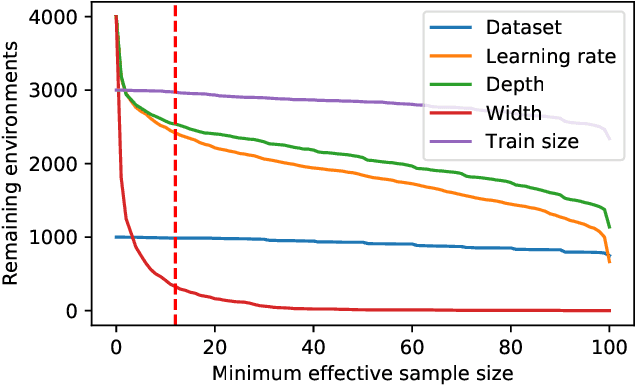
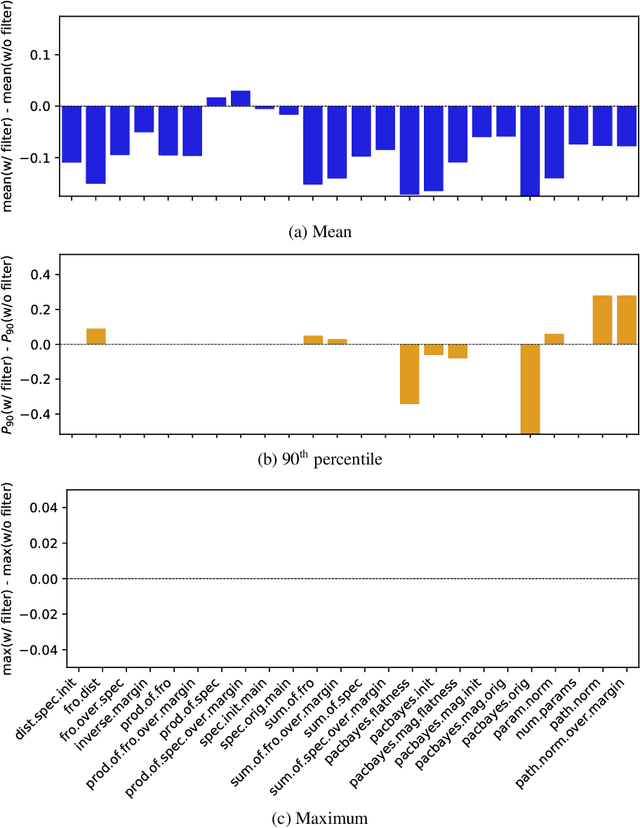
One of the principal scientific challenges in deep learning is explaining generalization, i.e., why the particular way the community now trains networks to achieve small training error also leads to small error on held-out data from the same population. It is widely appreciated that some worst-case theories -- such as those based on the VC dimension of the class of predictors induced by modern neural network architectures -- are unable to explain empirical performance. A large volume of work aims to close this gap, primarily by developing bounds on generalization error, optimization error, and excess risk. When evaluated empirically, however, most of these bounds are numerically vacuous. Focusing on generalization bounds, this work addresses the question of how to evaluate such bounds empirically. Jiang et al. (2020) recently described a large-scale empirical study aimed at uncovering potential causal relationships between bounds/measures and generalization. Building on their study, we highlight where their proposed methods can obscure failures and successes of generalization measures in explaining generalization. We argue that generalization measures should instead be evaluated within the framework of distributional robustness.
Viewpoint Selection for Photographing Architectures
Mar 06, 2017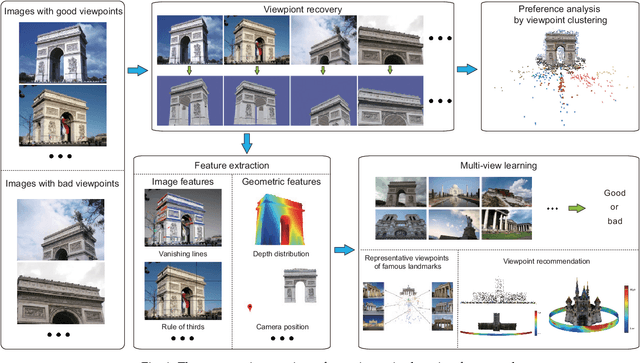



This paper studies the problem of how to choose good viewpoints for taking photographs of architectures. We achieve this by learning from professional photographs of world famous landmarks that are available on the Internet. Unlike previous efforts devoted to photo quality assessment which mainly rely on 2D image features, we show in this paper combining 2D image features extracted from images with 3D geometric features computed on the 3D models can result in more reliable evaluation of viewpoint quality. Specifically, we collect a set of photographs for each of 15 world famous architectures as well as their 3D models from the Internet. Viewpoint recovery for images is carried out through an image-model registration process, after which a newly proposed viewpoint clustering strategy is exploited to validate users' viewpoint preferences when photographing landmarks. Finally, we extract a number of 2D and 3D features for each image based on multiple visual and geometric cues and perform viewpoint recommendation by learning from both 2D and 3D features using a specifically designed SVM-2K multi-view learner, achieving superior performance over using solely 2D or 3D features. We show the effectiveness of the proposed approach through extensive experiments. The experiments also demonstrate that our system can be used to recommend viewpoints for rendering textured 3D models of buildings for the use of architectural design, in addition to viewpoint evaluation of photographs and recommendation of viewpoints for photographing architectures in practice.