 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSFam: Scribble Supervised Salient Object Detection Family
Sep 07, 2024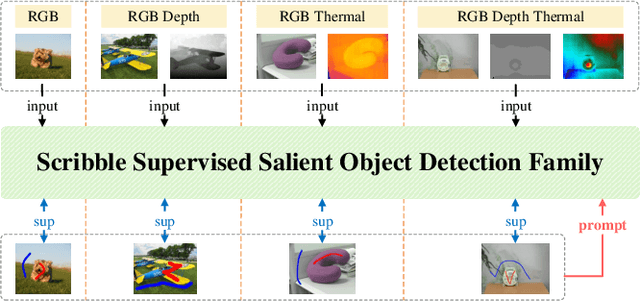
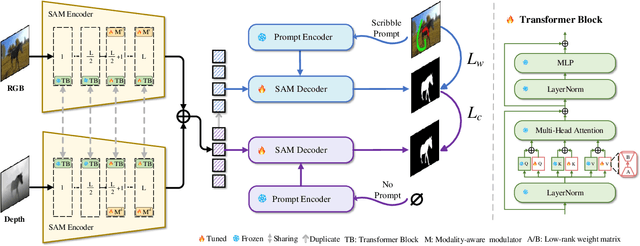
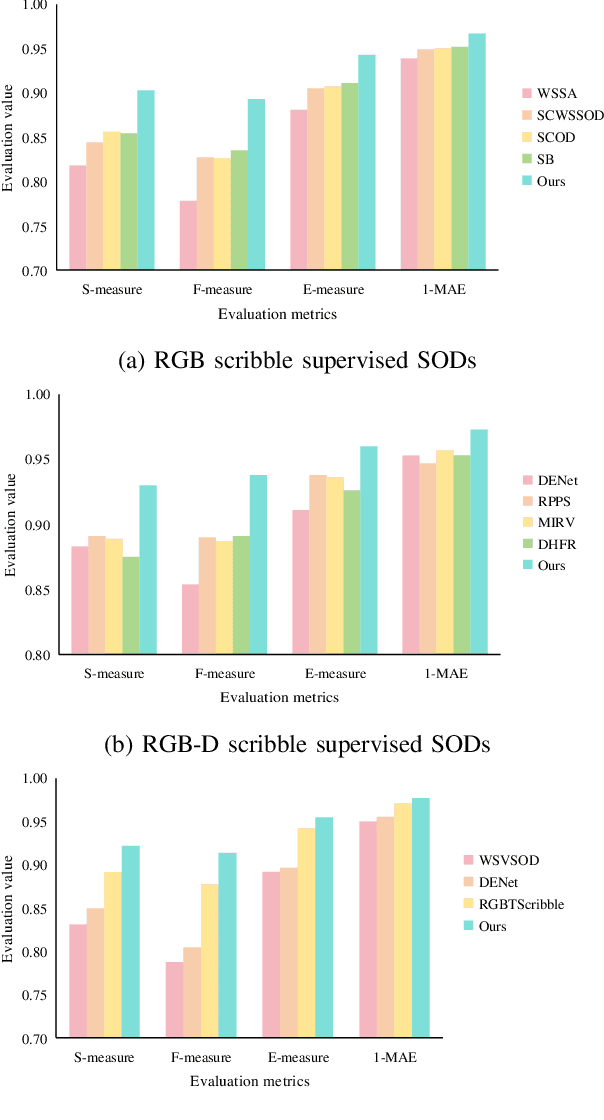

Scribble supervised salient object detection (SSSOD) constructs segmentation ability of attractive objects from surroundings under the supervision of sparse scribble labels. For the better segmentation, depth and thermal infrared modalities serve as the supplement to RGB images in the complex scenes. Existing methods specifically design various feature extraction and multi-modal fusion strategies for RGB, RGB-Depth, RGB-Thermal, and Visual-Depth-Thermal image input respectively, leading to similar model flood. As the recently proposed Segment Anything Model (SAM) possesses extraordinary segmentation and prompt interactive capability, we propose an SSSOD family based on SAM, named SSFam, for the combination input with different modalities. Firstly, different modal-aware modulators are designed to attain modal-specific knowledge which cooperates with modal-agnostic information extracted from the frozen SAM encoder for the better feature ensemble. Secondly, a siamese decoder is tailored to bridge the gap between the training with scribble prompt and the testing with no prompt for the stronger decoding ability. Our model demonstrates the remarkable performance among combinations of different modalities and refreshes the highest level of scribble supervised methods and comes close to the ones of fully supervised methods. https://github.com/liuzywen/SSFam