 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Agentic Self-Learning LLMs in Search Environment
Oct 16, 2025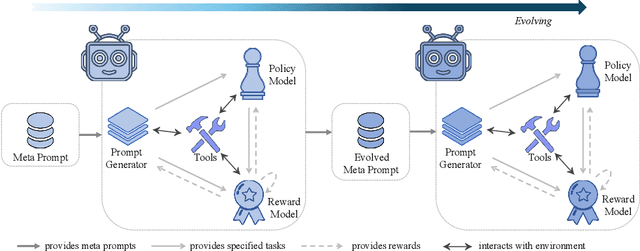
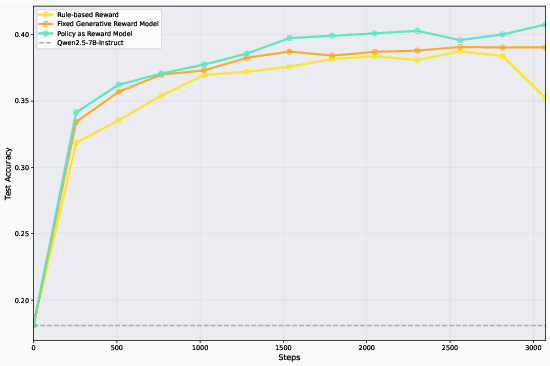
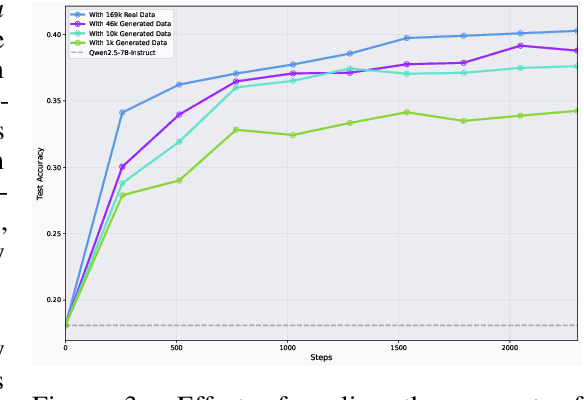
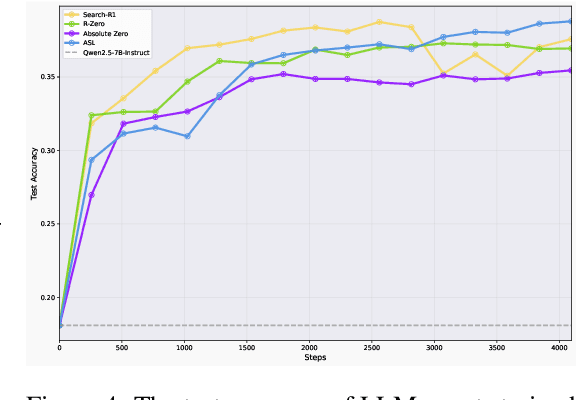
We study whether self-learning can scale LLM-based agents without relying on human-curated datasets or predefined rule-based rewards. Through controlled experiments in a search-agent setting, we identify two key determinants of scalable agent training: the source of reward signals and the scale of agent task data. We find that rewards from a Generative Reward Model (GRM) outperform rigid rule-based signals for open-domain learning, and that co-evolving the GRM with the policy further boosts performance. Increasing the volume of agent task data-even when synthetically generated-substantially enhances agentic capabilities. Building on these insights, we propose \textbf{Agentic Self-Learning} (ASL), a fully closed-loop, multi-role reinforcement learning framework that unifies task generation, policy execution, and evaluation within a shared tool environment and LLM backbone. ASL coordinates a Prompt Generator, a Policy Model, and a Generative Reward Model to form a virtuous cycle of harder task setting, sharper verification, and stronger solving. Empirically, ASL delivers steady, round-over-round gains, surpasses strong RLVR baselines (e.g., Search-R1) that plateau or degrade, and continues improving under zero-labeled-data conditions, indicating superior sample efficiency and robustness. We further show that GRM verification capacity is the main bottleneck: if frozen, it induces reward hacking and stalls progress; continual GRM training on the evolving data distribution mitigates this, and a small late-stage injection of real verification data raises the performance ceiling. This work establishes reward source and data scale as critical levers for open-domain agent learning and demonstrates the efficacy of multi-role co-evolution for scalable, self-improving agents. The data and code of this paper are released at https://github.com/forangel2014/Towards-Agentic-Self-Learning
Amplify Adjacent Token Differences: Enhancing Long Chain-of-Thought Reasoning with Shift-FFN
May 22, 2025Recently, models such as OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable performance on complex reasoning tasks through Long Chain-of-Thought (Long-CoT) reasoning. Although distilling this capability into student models significantly enhances their performance, this paper finds that fine-tuning LLMs with full parameters or LoRA with a low rank on long CoT data often leads to Cyclical Reasoning, where models repeatedly reiterate previous inference steps until the maximum length limit. Further analysis reveals that smaller differences in representations between adjacent tokens correlates with a higher tendency toward Cyclical Reasoning. To mitigate this issue, this paper proposes Shift Feedforward Networks (Shift-FFN), a novel approach that edits the current token's representation with the previous one before inputting it to FFN. This architecture dynamically amplifies the representation differences between adjacent tokens. Extensive experiments on multiple mathematical reasoning tasks demonstrate that LoRA combined with Shift-FFN achieves higher accuracy and a lower rate of Cyclical Reasoning across various data sizes compared to full fine-tuning and standard LoRA. Our data and code are available at https://anonymous.4open.science/r/Shift-FFN
Improve Rule Retrieval and Reasoning with Self-Induction and Relevance ReEstimate
May 16, 2025This paper systematically addresses the challenges of rule retrieval, a crucial yet underexplored area. Vanilla retrieval methods using sparse or dense retrievers to directly search for relevant rules to support downstream reasoning, often suffer from low accuracy. This is primarily due to a significant semantic gap between the instantiated facts in the queries and the abstract representations of the rules. Such misalignment results in suboptimal retrieval quality, which in turn negatively impacts reasoning performance. To overcome these challenges, we propose Self-Induction Augmented Retrieval (SIAR), a novel approach that utilizes Large Language Models (LLMs) to induce potential inferential rules that might offer benefits for reasoning by abstracting the underlying knowledge and logical structure in queries. These induced rules are then used for query augmentation to improve retrieval effectiveness. Additionally, we introduce Rule Relevance ReEstimate (R$^3$), a method that re-estimates the relevance of retrieved rules by assessing whether the abstract knowledge they contain can be instantiated to align with the facts in the queries and the helpfulness for reasoning. Extensive experiments across various settings demonstrate the effectiveness and versatility of our proposed methods.
Probabilistic Uncertain Reward Model: A Natural Generalization of Bradley-Terry Reward Model
Mar 28, 2025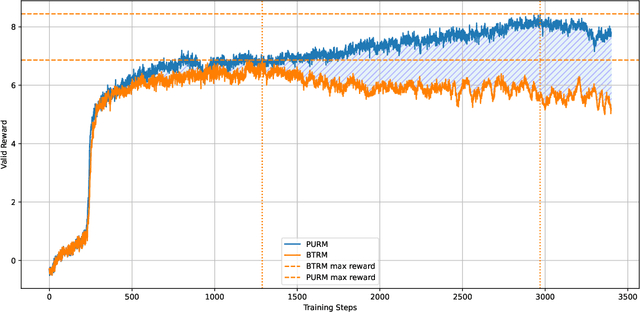
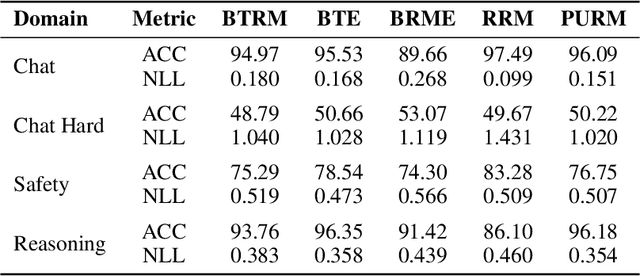
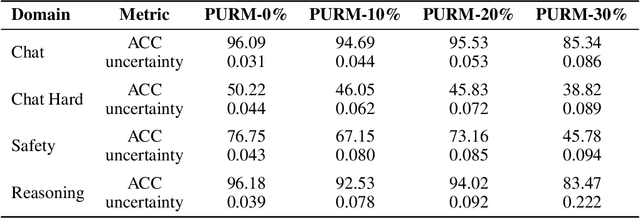
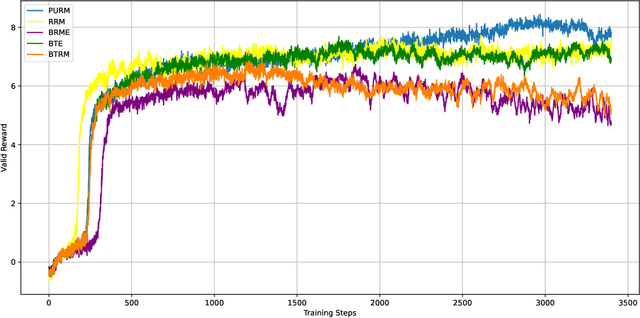
Reinforcement Learning from Human Feedback (RLHF) has emerged as a critical technique for training large language models. However, reward hacking-a phenomenon where models exploit flaws in the reward model-remains a significant barrier to achieving robust and scalable intelligence through long-term training. Existing studies have proposed uncertain reward model to address reward hacking, however, they often lack systematic or theoretical foundations, failing to model the uncertainty intrinsically emerging from preference data. In this paper, we propose the Probabilistic Uncertain Reward Model (PURM), a natural generalization of the classical Bradley-Terry reward model. PURM learns reward distributions directly from preference data and quantifies per-sample uncertainty via the average overlap area between reward distributions. To mitigate reward hacking, we further introduce an uncertainty-aware penalty into Proximal Policy Optimization (PPO), which leverages the learned uncertainty to dynamically balance reward optimization and exploration. We propose a lightweight and easy-to-use implementation of PURM. Experiments demonstrate that PURM significantly delays the onset of reward hacking while improving final reward performance, outperforming baseline methods in both stability and effectiveness.
VaiBot: Shuttle Between the Instructions and Parameters
Feb 04, 2025How to interact with LLMs through \emph{instructions} has been widely studied by researchers. However, previous studies have treated the emergence of instructions and the training of LLMs on task data as separate processes, overlooking the inherent unity between the two. This paper proposes a neural network framework, VaiBot, that integrates VAE and VIB, designed to uniformly model, learn, and infer both deduction and induction tasks under LLMs. Through experiments, we demonstrate that VaiBot performs on par with existing baseline methods in terms of deductive capabilities while significantly surpassing them in inductive capabilities. We also find that VaiBot can scale up using general instruction-following data and exhibits excellent one-shot induction abilities. We finally synergistically integrate the deductive and inductive processes of VaiBot. Through T-SNE dimensionality reduction, we observe that its inductive-deductive process significantly improves the distribution of training parameters, enabling it to outperform baseline methods in inductive reasoning tasks. The code and data for this paper can be found at https://anonymous.4open.science/r/VaiBot-021F.
ONSEP: A Novel Online Neural-Symbolic Framework for Event Prediction Based on Large Language Model
Aug 14, 2024In the realm of event prediction, temporal knowledge graph forecasting (TKGF) stands as a pivotal technique. Previous approaches face the challenges of not utilizing experience during testing and relying on a single short-term history, which limits adaptation to evolving data. In this paper, we introduce the Online Neural-Symbolic Event Prediction (ONSEP) framework, which innovates by integrating dynamic causal rule mining (DCRM) and dual history augmented generation (DHAG). DCRM dynamically constructs causal rules from real-time data, allowing for swift adaptation to new causal relationships. In parallel, DHAG merges short-term and long-term historical contexts, leveraging a bi-branch approach to enrich event prediction. Our framework demonstrates notable performance enhancements across diverse datasets, with significant Hit@k (k=1,3,10) improvements, showcasing its ability to augment large language models (LLMs) for event prediction without necessitating extensive retraining. The ONSEP framework not only advances the field of TKGF but also underscores the potential of neural-symbolic approaches in adapting to dynamic data environments.
Beyond Instruction Following: Evaluating Rule Following of Large Language Models
Jul 11, 2024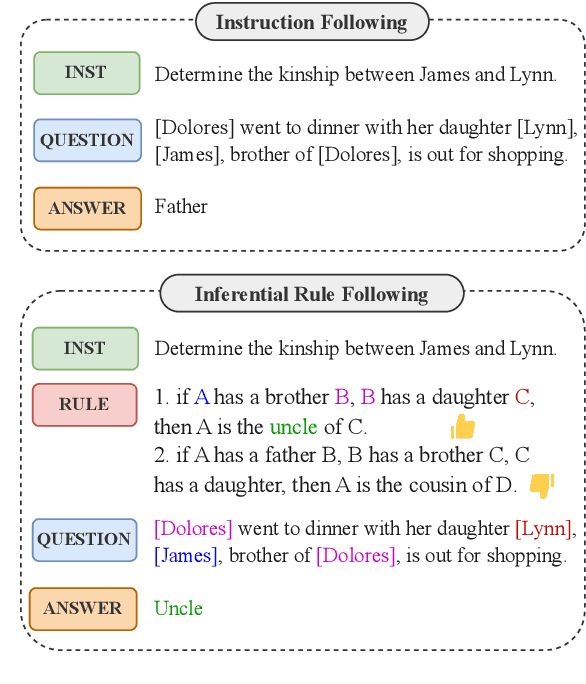



Although Large Language Models (LLMs) have demonstrated strong instruction-following ability to be helpful, they are further supposed to be controlled and guided by rules in real-world scenarios to be safe, and accurate in responses. This demands the possession of rule-following capability of LLMs. However, few works have made a clear evaluation of the rule-following capability of LLMs. Previous studies that try to evaluate the rule-following capability of LLMs fail to distinguish the rule-following scenarios from the instruction-following scenarios. Therefore, this paper first makes a clarification of the concept of rule-following, and curates a comprehensive benchmark, RuleBench, to evaluate a diversified range of rule-following abilities. Our experimental results on a variety of LLMs show that they are still limited in following rules. Our further analysis provides insights into the improvements for LLMs toward a better rule-following intelligent agent. The data and code can be found at: https://anonymous.4open.science/r/llm-rule-following-B3E3/
ItD: Large Language Models Can Teach Themselves Induction through Deduction
Mar 09, 2024



Although Large Language Models (LLMs) are showing impressive performance on a wide range of Natural Language Processing tasks, researchers have found that they still have limited ability to conduct induction. Recent works mainly adopt ``post processes'' paradigms to improve the performance of LLMs on induction (e.g., the hypothesis search & refinement methods), but their performance is still constrained by the inherent inductive capability of the LLMs. In this paper, we propose a novel framework, Induction through Deduction (ItD), to enable the LLMs to teach themselves induction through deduction. The ItD framework is composed of two main components: a Deductive Data Generation module to generate induction data and a Naive Bayesian Induction module to optimize the fine-tuning and decoding of LLMs. Our empirical results showcase the effectiveness of ItD on two induction benchmarks, achieving relative performance improvement of 36% and 10% compared with previous state-of-the-art, respectively. Our ablation study verifies the effectiveness of two key modules of ItD. We also verify the effectiveness of ItD across different LLMs and deductors. The data and code of this paper can be found at https://anonymous.4open.science/r/ItD-E844.
From Chain to Tree: Refining Chain-like Rules into Tree-like Rules on Knowledge Graphs
Mar 08, 2024With good explanatory power and controllability, rule-based methods play an important role in many tasks such as knowledge reasoning and decision support. However, existing studies primarily focused on learning chain-like rules, which limit their semantic expressions and accurate prediction abilities. As a result, chain-like rules usually fire on the incorrect grounding values, producing inaccurate or even erroneous reasoning results. In this paper, we propose the concept of tree-like rules on knowledge graphs to expand the application scope and improve the reasoning ability of rule-based methods. Meanwhile, we propose an effective framework for refining chain-like rules into tree-like rules. Experimental comparisons on four public datasets show that the proposed framework can easily adapt to other chain-like rule induction methods and the refined tree-like rules consistently achieve better performances than chain-like rules on link prediction. The data and code of this paper can be available at https://anonymous.4open.science/r/tree-rule-E3CD/.
ExpNote: Black-box Large Language Models are Better Task Solvers with Experience Notebook
Nov 13, 2023Black-box Large Language Models (LLMs) have shown great power in solving various tasks and are considered general problem solvers. However, LLMs still fail in many specific tasks although understand the task instruction. In this paper, we focus on the problem of boosting the ability of black-box LLMs to solve downstream tasks. We propose ExpNote, an automated framework to help LLMs better adapt to unfamiliar tasks through reflecting and noting experiences from training data and retrieving them from external memory during testing. We evaluate ExpNote on multiple tasks and the experimental results demonstrate that the proposed method significantly improves the performance of black-box LLMs. The data and code are available at https://github.com/forangel2014/ExpNote