 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Instruction Following: Evaluating Rule Following of Large Language Models
Jul 11, 2024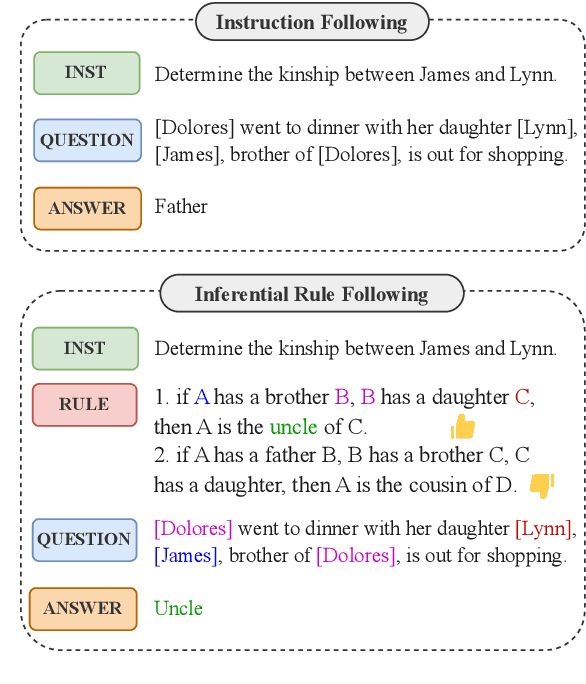



Although Large Language Models (LLMs) have demonstrated strong instruction-following ability to be helpful, they are further supposed to be controlled and guided by rules in real-world scenarios to be safe, and accurate in responses. This demands the possession of rule-following capability of LLMs. However, few works have made a clear evaluation of the rule-following capability of LLMs. Previous studies that try to evaluate the rule-following capability of LLMs fail to distinguish the rule-following scenarios from the instruction-following scenarios. Therefore, this paper first makes a clarification of the concept of rule-following, and curates a comprehensive benchmark, RuleBench, to evaluate a diversified range of rule-following abilities. Our experimental results on a variety of LLMs show that they are still limited in following rules. Our further analysis provides insights into the improvements for LLMs toward a better rule-following intelligent agent. The data and code can be found at: https://anonymous.4open.science/r/llm-rule-following-B3E3/