 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deploying VLA without Fine-Tuning: Plug-and-Play Inference-Time VLA Policy Steering via Embodied Evolutionary Diffusion
Nov 18, 2025Vision-Language-Action (VLA) models have demonstrated significant potential in real-world robotic manipulation. However, pre-trained VLA policies still suffer from substantial performance degradation during downstream deployment. Although fine-tuning can mitigate this issue, its reliance on costly demonstration collection and intensive computation makes it impractical in real-world settings. In this work, we introduce VLA-Pilot, a plug-and-play inference-time policy steering method for zero-shot deployment of pre-trained VLA without any additional fine-tuning or data collection. We evaluate VLA-Pilot on six real-world downstream manipulation tasks across two distinct robotic embodiments, encompassing both in-distribution and out-of-distribution scenarios. Experimental results demonstrate that VLA-Pilot substantially boosts the success rates of off-the-shelf pre-trained VLA policies, enabling robust zero-shot generalization to diverse tasks and embodiments. Experimental videos and code are available at: https://rip4kobe.github.io/vla-pilot/.
ManiDP: Manipulability-Aware Diffusion Policy for Posture-Dependent Bimanual Manipulation
Oct 27, 2025Recent work has demonstrated the potential of diffusion models in robot bimanual skill learning. However, existing methods ignore the learning of posture-dependent task features, which are crucial for adapting dual-arm configurations to meet specific force and velocity requirements in dexterous bimanual manipulation. To address this limitation, we propose Manipulability-Aware Diffusion Policy (ManiDP), a novel imitation learning method that not only generates plausible bimanual trajectories, but also optimizes dual-arm configurations to better satisfy posture-dependent task requirements. ManiDP achieves this by extracting bimanual manipulability from expert demonstrations and encoding the encapsulated posture features using Riemannian-based probabilistic models. These encoded posture features are then incorporated into a conditional diffusion process to guide the generation of task-compatible bimanual motion sequences. We evaluate ManiDP on six real-world bimanual tasks, where the experimental results demonstrate a 39.33$\%$ increase in average manipulation success rate and a 0.45 improvement in task compatibility compared to baseline methods. This work highlights the importance of integrating posture-relevant robotic priors into bimanual skill diffusion to enable human-like adaptability and dexterity.
Human-Like Robot Impedance Regulation Skill Learning from Human-Human Demonstrations
Feb 19, 2025Humans are experts in collaborating with others physically by regulating compliance behaviors based on the perception of their partner states and the task requirements. Enabling robots to develop proficiency in human collaboration skills can facilitate more efficient human-robot collaboration (HRC). This paper introduces an innovative impedance regulation skill learning framework for achieving HRC in multiple physical collaborative tasks. The framework is designed to adjust the robot compliance to the human partner states while adhering to reference trajectories provided by human-human demonstrations. Specifically, electromyography (EMG) signals from human muscles are collected and analyzed to extract limb impedance, representing compliance behaviors during demonstrations. Human endpoint motions are captured and represented using a probabilistic learning method to create reference trajectories and corresponding impedance profiles. Meanwhile, an LSTMbased module is implemented to develop task-oriented impedance regulation policies by mapping the muscle synergistic contributions between two demonstrators. Finally, we propose a wholebody impedance controller for a human-like robot, coordinating joint outputs to achieve the desired impedance and reference trajectory during task execution. Experimental validation was conducted through a collaborative transportation task and two interactive Tai Chi pushing hands tasks, demonstrating superior performance from the perspective of interactive forces compared to a constant impedance control method.
Human-Humanoid Robots Cross-Embodiment Behavior-Skill Transfer Using Decomposed Adversarial Learning from Demonstration
Dec 19, 2024Humanoid robots are envisioned as embodied intelligent agents capable of performing a wide range of human-level loco-manipulation tasks, particularly in scenarios requiring strenuous and repetitive labor. However, learning these skills is challenging due to the high degrees of freedom of humanoid robots, and collecting sufficient training data for humanoid is a laborious process. Given the rapid introduction of new humanoid platforms, a cross-embodiment framework that allows generalizable skill transfer is becoming increasingly critical. To address this, we propose a transferable framework that reduces the data bottleneck by using a unified digital human model as a common prototype and bypassing the need for re-training on every new robot platform. The model learns behavior primitives from human demonstrations through adversarial imitation, and the complex robot structures are decomposed into functional components, each trained independently and dynamically coordinated. Task generalization is achieved through a human-object interaction graph, and skills are transferred to different robots via embodiment-specific kinematic motion retargeting and dynamic fine-tuning. Our framework is validated on five humanoid robots with diverse configurations, demonstrating stable loco-manipulation and highlighting its effectiveness in reducing data requirements and increasing the efficiency of skill transfer across platforms.
BiRP: Learning Robot Generalized Bimanual Coordination using Relative Parameterization Method on Human Demonstration
Jul 12, 2023Human bimanual manipulation can perform more complex tasks than a simple combination of two single arms, which is credited to the spatio-temporal coordination between the arms. However, the description of bimanual coordination is still an open topic in robotics. This makes it difficult to give an explainable coordination paradigm, let alone applied to robotics. In this work, we divide the main bimanual tasks in human daily activities into two types: leader-follower and synergistic coordination. Then we propose a relative parameterization method to learn these types of coordination from human demonstration. It represents coordination as Gaussian mixture models from bimanual demonstration to describe the change in the importance of coordination throughout the motions by probability. The learned coordinated representation can be generalized to new task parameters while ensuring spatio-temporal coordination. We demonstrate the method using synthetic motions and human demonstration data and deploy it to a humanoid robot to perform a generalized bimanual coordination motion. We believe that this easy-to-use bimanual learning from demonstration (LfD) method has the potential to be used as a data augmentation plugin for robot large manipulation model training. The corresponding codes are open-sourced in https://github.com/Skylark0924/Rofunc.
SoftGPT: Learn Goal-oriented Soft Object Manipulation Skills by Generative Pre-trained Heterogeneous Graph Transformer
Jun 22, 2023



Soft object manipulation tasks in domestic scenes pose a significant challenge for existing robotic skill learning techniques due to their complex dynamics and variable shape characteristics. Since learning new manipulation skills from human demonstration is an effective way for robot applications, developing prior knowledge of the representation and dynamics of soft objects is necessary. In this regard, we propose a pre-trained soft object manipulation skill learning model, namely SoftGPT, that is trained using large amounts of exploration data, consisting of a three-dimensional heterogeneous graph representation and a GPT-based dynamics model. For each downstream task, a goal-oriented policy agent is trained to predict the subsequent actions, and SoftGPT generates the consequences of these actions. Integrating these two approaches establishes a thinking process in the robot's mind that provides rollout for facilitating policy learning. Our results demonstrate that leveraging prior knowledge through this thinking process can efficiently learn various soft object manipulation skills, with the potential for direct learning from human demonstrations.
ReVoLT: Relational Reasoning and Voronoi Local Graph Planning for Target-driven Navigation
Jan 10, 2023Embodied AI is an inevitable trend that emphasizes the interaction between intelligent entities and the real world, with broad applications in Robotics, especially target-driven navigation. This task requires the robot to find an object of a certain category efficiently in an unknown domestic environment. Recent works focus on exploiting layout relationships by graph neural networks (GNNs). However, most of them obtain robot actions directly from observations in an end-to-end manner via an incomplete relation graph, which is not interpretable and reliable. We decouple this task and propose ReVoLT, a hierarchical framework: (a) an object detection visual front-end, (b) a high-level reasoner (infers semantic sub-goals), (c) an intermediate-level planner (computes geometrical positions), and (d) a low-level controller (executes actions). ReVoLT operates with a multi-layer semantic-spatial topological graph. The reasoner uses multiform structured relations as priors, which are obtained from combinatorial relation extraction networks composed of unsupervised GraphSAGE, GCN, and GraphRNN-based Region Rollout. The reasoner performs with Upper Confidence Bound for Tree (UCT) to infer semantic sub-goals, accounting for trade-offs between exploitation (depth-first searching) and exploration (regretting). The lightweight intermediate-level planner generates instantaneous spatial sub-goal locations via an online constructed Voronoi local graph. The simulation experiments demonstrate that our framework achieves better performance in the target-driven navigation tasks and generalizes well, which has an 80% improvement compared to the existing state-of-the-art method. The code and result video will be released at https://ventusff.github.io/ReVoLT-website/.
Mixline: A Hybrid Reinforcement Learning Framework for Long-horizon Bimanual Coffee Stirring Task
Nov 04, 2022Bimanual activities like coffee stirring, which require coordination of dual arms, are common in daily life and intractable to learn by robots. Adopting reinforcement learning to learn these tasks is a promising topic since it enables the robot to explore how dual arms coordinate together to accomplish the same task. However, this field has two main challenges: coordination mechanism and long-horizon task decomposition. Therefore, we propose the Mixline method to learn sub-tasks separately via the online algorithm and then compose them together based on the generated data through the offline algorithm. We constructed a learning environment based on the GPU-accelerated Isaac Gym. In our work, the bimanual robot successfully learned to grasp, hold and lift the spoon and cup, insert them together and stir the coffee. The proposed method has the potential to be extended to other long-horizon bimanual tasks.
* 10 pages, conference
Robot Cooking with Stir-fry: Bimanual Non-prehensile Manipulation of Semi-fluid Objects
May 12, 2022

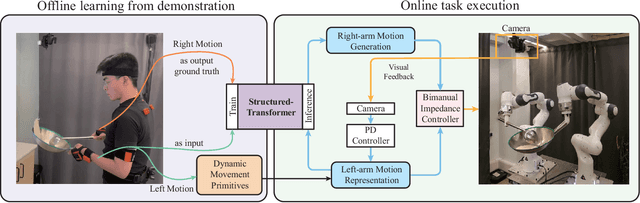
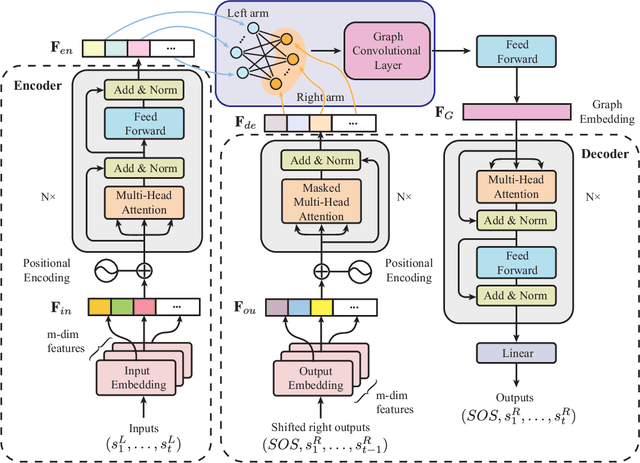
This letter describes an approach to achieve well-known Chinese cooking art stir-fry on a bimanual robot system. Stir-fry requires a sequence of highly dynamic coordinated movements, which is usually difficult to learn for a chef, let alone transfer to robots. In this letter, we define a canonical stir-fry movement, and then propose a decoupled framework for learning this deformable object manipulation from human demonstration. First, the dual arms of the robot are decoupled into different roles (a leader and follower) and learned with classical and neural network-based methods separately, then the bimanual task is transformed into a coordination problem. To obtain general bimanual coordination, we secondly propose a Graph and Transformer based model -- Structured-Transformer, to capture the spatio-temporal relationship between dual-arm movements. Finally, by adding visual feedback of content deformation, our framework can adjust the movements automatically to achieve the desired stir-fry effect. We verify the framework by a simulator and deploy it on a real bimanual Panda robot system. The experimental results validate our framework can realize the bimanual robot stir-fry motion and have the potential to extend to other deformable objects with bimanual coordination.
* 8 pages, 8 figures, published to RA-L
A Multi-Modal States based Vehicle Descriptor and Dilated Convolutional Social Pooling for Vehicle Trajectory Prediction
Mar 07, 2020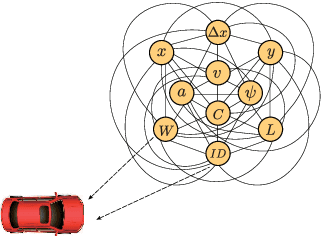
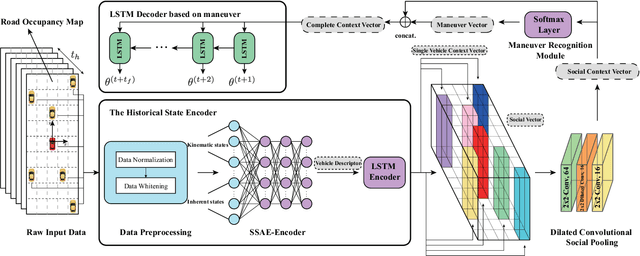
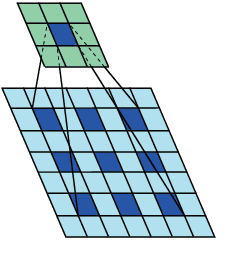
Precise trajectory prediction of surrounding vehicles is critical for decision-making of autonomous vehicles and learning-based approaches are well recognized for the robustness. However, state-of-the-art learning-based methods ignore 1) the feasibility of the vehicle's multi-modal state information for prediction and 2) the mutual exclusive relationship between the global traffic scene receptive fields and the local position resolution when modeling vehicles' interactions, which may influence prediction accuracy. Therefore, we propose a vehicle-descriptor based LSTM model with the dilated convolutional social pooling (VD+DCS-LSTM) to cope with the above issues. First, each vehicle's multi-modal state information is employed as our model's input and a new vehicle descriptor encoded by stacked sparse auto-encoders is proposed to reflect the deep interactive relationships between various states, achieving the optimal feature extraction and effective use of multi-modal inputs. Secondly, the LSTM encoder is used to encode the historical sequences composed of the vehicle descriptor and a novel dilated convolutional social pooling is proposed to improve modeling vehicles' spatial interactions. Thirdly, the LSTM decoder is used to predict the probability distribution of future trajectories based on maneuvers. The validity of the overall model was verified over the NGSIM US-101 and I-80 datasets and our method outperforms the latest benchmark.