 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal States based Vehicle Descriptor and Dilated Convolutional Social Pooling for Vehicle Trajectory Prediction
Mar 07, 2020
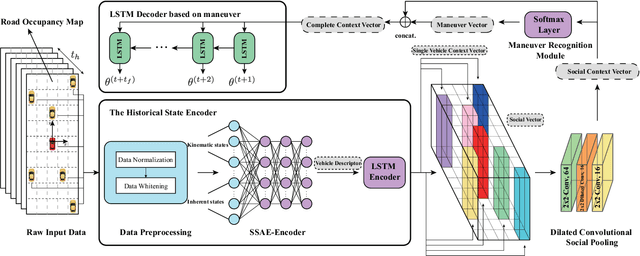
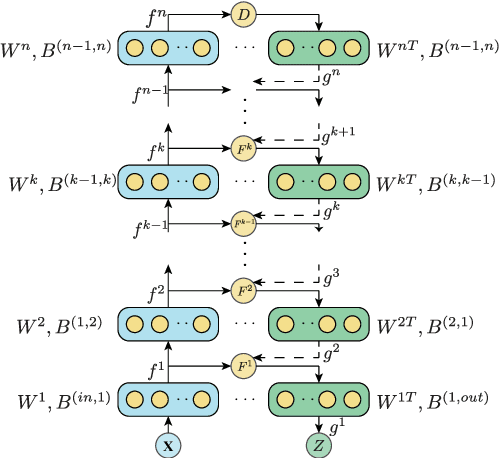
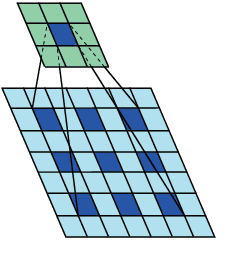
Precise trajectory prediction of surrounding vehicles is critical for decision-making of autonomous vehicles and learning-based approaches are well recognized for the robustness. However, state-of-the-art learning-based methods ignore 1) the feasibility of the vehicle's multi-modal state information for prediction and 2) the mutual exclusive relationship between the global traffic scene receptive fields and the local position resolution when modeling vehicles' interactions, which may influence prediction accuracy. Therefore, we propose a vehicle-descriptor based LSTM model with the dilated convolutional social pooling (VD+DCS-LSTM) to cope with the above issues. First, each vehicle's multi-modal state information is employed as our model's input and a new vehicle descriptor encoded by stacked sparse auto-encoders is proposed to reflect the deep interactive relationships between various states, achieving the optimal feature extraction and effective use of multi-modal inputs. Secondly, the LSTM encoder is used to encode the historical sequences composed of the vehicle descriptor and a novel dilated convolutional social pooling is proposed to improve modeling vehicles' spatial interactions. Thirdly, the LSTM decoder is used to predict the probability distribution of future trajectories based on maneuvers. The validity of the overall model was verified over the NGSIM US-101 and I-80 datasets and our method outperforms the latest benchmark.