 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamKL: Fast and Memory-Efficient KL Divergence for Boosting Attention Distillation
Jun 18, 2026Attention distillation, which trains one attention distribution to match another by minimizing their Kullback-Leibler (KL) divergence, is widely used in knowledge distillation, model compression, continual learning, and sparse-attention LLM training. However, existing approaches materialize both attention distributions before computing the KL reduction, incurring $O(N_QN_K)$ memory and IO costs that become prohibitive at long context lengths. We present StreamKL, the first fused GPU primitive for attention KL divergence that eliminates this quadratic materialization. StreamKL derives a novel online formulation for the coupled two-distribution KL reduction, enabling a single one-pass forward kernel that streams query-key tiles through on-chip SRAM. For the backward pass, StreamKL recomputes attention probabilities tile-by-tile, avoiding storage of quadratic intermediates. We further design and implement efficient GPU kernels with dedicated optimizations. Experiments show StreamKL delivers up to $43\times$ and $14\times$ speedups over baseline methods in the forward and backward passes, respectively. Most importantly, StreamKL reduces the extra HBM footprint of attention distillation from $O(N_QN_K)$ to $O(1)$, enabling long-context distillation on a single GPU.
DINO-GFSA: Geo-Localization via Semantic Gated Fusion and Mamba-based Sequential Aggregation
May 30, 2026Cross-view geo-localization (CVGL) is critical for Unmanned Aerial Vehicle (UAV) self-positioning and target localization in GNSS-denied environments. However, acquiring robust semantics while preserving finegrained spatial details remains challenging. To address this, we propose DINO-GFSA, a framework leveraging a LoRA (Low-Rank Adaptation) adapted DINOv3 (ViTL) backbone for parameter-efficient, high-capacity representation. Crucially, we introduce a Semantic Gated Residual Fusion module, which utilizes high-level semantics to selectively calibrate and integrate low-level spatial cues, effectively bridging the semantic gap. Furthermore, a Mamba-based Sequential Aggregation Head is designed to capture long-range spatial dependencies with linear complexity. Experiments demonstrate state-of-the-art performance on University-1652 and DenseUAV benchmarks, notably surpassing the previous best on DenseUAV by 3.48% on Recall@1. These results validate DINO-GFSA as a generalized, robust solution for UAV CVGL.
Evolutionary Enhanced Multi-Agent Reinforcement Learning for Cooperative Air Combat
May 24, 2026As modern air combat evolves toward beyond-visual-range (BVR) multi-aircraft cooperative engagements, autonomous decision-making for unmanned combat aerial vehicles (UCAVs) faces significant challenges due to high-dimensional state spaces, discrete action commands, and strongly adversarial dynamic environments. To overcome the limitations of existing multi-agent reinforcement learning (MARL) methods in such settings, namely insufficient exploration efficiency, low sample utilization, and poor policy generalization, we propose Adversarial Curriculum and Evolutionary-enhanced Multi-agent Proximal Policy Optimization (ACE-MAPPO), a hybrid learning framework that integrates evolutionary algorithms with MAPPO. Specifically, a genetic soft update mechanism is introduced to enhance population diversity and mitigate convergence to local optima. An evolutionary-augmented prioritized trajectory replay strategy is further employed to improve the utilization of sparse high-value samples. In addition, an adversarial evolutionary curriculum learning mechanism is designed to enable adaptive training with progressively increasing difficulty. Extensive experimental results demonstrate that the proposed method outperforms MAPPO and other baseline algorithms in terms of training stability, convergence speed, and win rate, validating its effectiveness in multi-aircraft cooperative air combat scenarios.
FreeKV: Boosting KV Cache Retrieval for Efficient LLM Inference
May 19, 2025Large language models (LLMs) have been widely deployed with rapidly expanding context windows to support increasingly demanding applications. However, long contexts pose significant deployment challenges, primarily due to the KV cache whose size grows proportionally with context length. While KV cache compression methods are proposed to address this issue, KV dropping methods incur considerable accuracy loss, and KV retrieval methods suffer from significant efficiency bottlenecks. We propose FreeKV, an algorithm-system co-optimization framework to enhance KV retrieval efficiency while preserving accuracy. On the algorithm side, FreeKV introduces speculative retrieval to shift the KV selection and recall processes out of the critical path, combined with fine-grained correction to ensure accuracy. On the system side, FreeKV employs hybrid KV layouts across CPU and GPU memory to eliminate fragmented data transfers, and leverages double-buffered streamed recall to further improve efficiency. Experiments demonstrate that FreeKV achieves near-lossless accuracy across various scenarios and models, delivering up to 13$\times$ speedup compared to SOTA KV retrieval methods.
ClusterKV: Manipulating LLM KV Cache in Semantic Space for Recallable Compression
Dec 04, 2024



Large Language Models (LLMs) have been widely deployed in a variety of applications, and the context length is rapidly increasing to handle tasks such as long-document QA and complex logical reasoning. However, long context poses significant challenges for inference efficiency, including high memory costs of key-value (KV) cache and increased latency due to extensive memory accesses. Recent works have proposed compressing KV cache to approximate computation, but these methods either evict tokens permanently, never recalling them for later inference, or recall previous tokens at the granularity of pages divided by textual positions. Both approaches degrade the model accuracy and output quality. To achieve efficient and accurate recallable KV cache compression, we introduce ClusterKV, which recalls tokens at the granularity of semantic clusters. We design and implement efficient algorithms and systems for clustering, selection, indexing and caching. Experiment results show that ClusterKV attains negligible accuracy loss across various tasks with 32k context lengths, using only a 1k to 2k KV cache budget, and achieves up to a 2$\times$ speedup in latency and a 2.5$\times$ improvement in decoding throughput. Compared to SoTA recallable KV compression methods, ClusterKV demonstrates higher model accuracy and output quality, while maintaining or exceeding inference efficiency.
A Multi-Modal States based Vehicle Descriptor and Dilated Convolutional Social Pooling for Vehicle Trajectory Prediction
Mar 07, 2020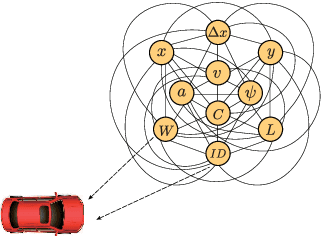
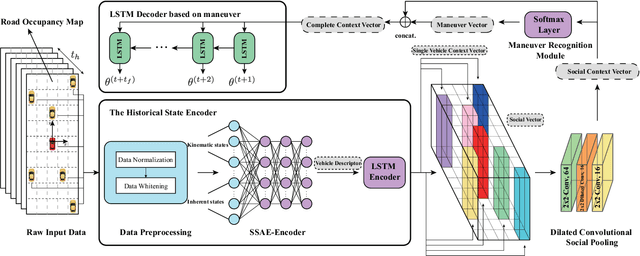
Precise trajectory prediction of surrounding vehicles is critical for decision-making of autonomous vehicles and learning-based approaches are well recognized for the robustness. However, state-of-the-art learning-based methods ignore 1) the feasibility of the vehicle's multi-modal state information for prediction and 2) the mutual exclusive relationship between the global traffic scene receptive fields and the local position resolution when modeling vehicles' interactions, which may influence prediction accuracy. Therefore, we propose a vehicle-descriptor based LSTM model with the dilated convolutional social pooling (VD+DCS-LSTM) to cope with the above issues. First, each vehicle's multi-modal state information is employed as our model's input and a new vehicle descriptor encoded by stacked sparse auto-encoders is proposed to reflect the deep interactive relationships between various states, achieving the optimal feature extraction and effective use of multi-modal inputs. Secondly, the LSTM encoder is used to encode the historical sequences composed of the vehicle descriptor and a novel dilated convolutional social pooling is proposed to improve modeling vehicles' spatial interactions. Thirdly, the LSTM decoder is used to predict the probability distribution of future trajectories based on maneuvers. The validity of the overall model was verified over the NGSIM US-101 and I-80 datasets and our method outperforms the latest benchmark.