 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainFusion2.0: Temporal-Spatial Awareness and Hardware-Efficient Block-wise Sparse Attention
Dec 30, 2025In video and image generation tasks, Diffusion Transformer (DiT) models incur extremely high computational costs due to attention mechanisms, which limits their practical applications. Furthermore, with hardware advancements, a wide range of devices besides graphics processing unit (GPU), such as application-specific integrated circuit (ASIC), have been increasingly adopted for model inference. Sparse attention, which leverages the inherent sparsity of attention by skipping computations for insignificant tokens, is an effective approach to mitigate computational costs. However, existing sparse attention methods have two critical limitations: the overhead of sparse pattern prediction and the lack of hardware generality, as most of these methods are designed for GPU. To address these challenges, this study proposes RainFusion2.0, which aims to develop an online adaptive, hardware-efficient, and low-overhead sparse attention mechanism to accelerate both video and image generative models, with robust performance across diverse hardware platforms. Key technical insights include: (1) leveraging block-wise mean values as representative tokens for sparse mask prediction; (2) implementing spatiotemporal-aware token permutation; and (3) introducing a first-frame sink mechanism specifically designed for video generation scenarios. Experimental results demonstrate that RainFusion2.0 can achieve 80% sparsity while achieving an end-to-end speedup of 1.5~1.8x without compromising video quality. Moreover, RainFusion2.0 demonstrates effectiveness across various generative models and validates its generalization across diverse hardware platforms.
TIMERIPPLE: Accelerating vDiTs by Understanding the Spatio-Temporal Correlations in Latent Space
Nov 15, 2025



The recent surge in video generation has shown the growing demand for high-quality video synthesis using large vision models. Existing video generation models are predominantly based on the video diffusion transformer (vDiT), however, they suffer from substantial inference delay due to self-attention. While prior studies have focused on reducing redundant computations in self-attention, they often overlook the inherent spatio-temporal correlations in video streams and directly leverage sparsity patterns from large language models to reduce attention computations. In this work, we take a principled approach to accelerate self-attention in vDiTs by leveraging the spatio-temporal correlations in the latent space. We show that the attention patterns within vDiT are primarily due to the dominant spatial and temporal correlations at the token channel level. Based on this insight, we propose a lightweight and adaptive reuse strategy that approximates attention computations by reusing partial attention scores of spatially or temporally correlated tokens along individual channels. We demonstrate that our method achieves significantly higher computational savings (85\%) compared to state-of-the-art techniques over 4 vDiTs, while preserving almost identical video quality ($<$0.06\% loss on VBench).
DartQuant: Efficient Rotational Distribution Calibration for LLM Quantization
Nov 06, 2025Quantization plays a crucial role in accelerating the inference of large-scale models, and rotational matrices have been shown to effectively improve quantization performance by smoothing outliers. However, end-to-end fine-tuning of rotational optimization algorithms incurs high computational costs and is prone to overfitting. To address this challenge, we propose an efficient distribution-aware rotational calibration method, DartQuant, which reduces the complexity of rotational optimization by constraining the distribution of the activations after rotation. This approach also effectively reduces reliance on task-specific losses, thereby mitigating the risk of overfitting. Additionally, we introduce the QR-Orth optimization scheme, which replaces expensive alternating optimization with a more efficient solution. In a variety of model quantization experiments, DartQuant demonstrates superior performance. Compared to existing methods, it achieves 47$\times$ acceleration and 10$\times$ memory savings for rotational optimization on a 70B model. Furthermore, it is the first to successfully complete rotational calibration for a 70B model on a single 3090 GPU, making quantization of large language models feasible in resource-constrained environments. Code is available at https://github.com/CAS-CLab/DartQuant.git.
Astraea: A GPU-Oriented Token-wise Acceleration Framework for Video Diffusion Transformers
Jun 06, 2025
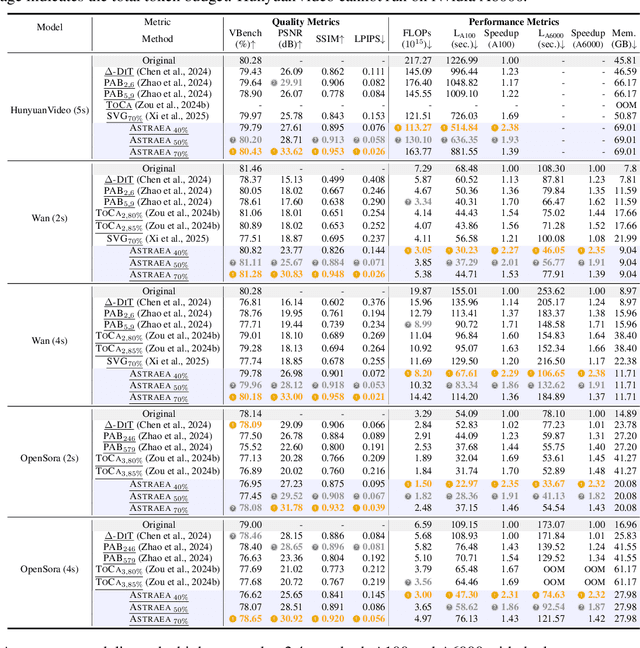
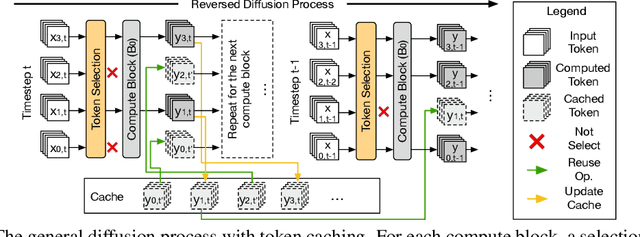
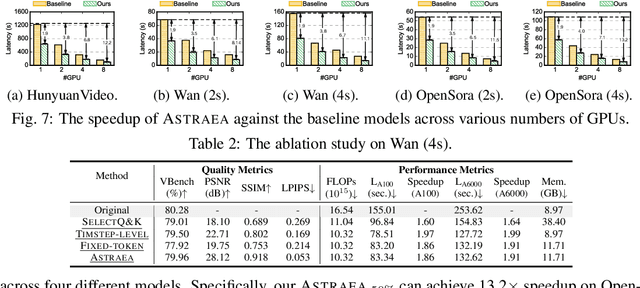
Video diffusion transformers (vDiTs) have made impressive progress in text-to-video generation, but their high computational demands present major challenges for practical deployment. While existing acceleration methods reduce workload at various granularities, they often rely on heuristics, limiting their applicability. We introduce ASTRAEA, an automatic framework that searches for near-optimal configurations for vDiT-based video generation. At its core, ASTRAEA proposes a lightweight token selection mechanism and a memory-efficient, GPU-parallel sparse attention strategy, enabling linear reductions in execution time with minimal impact on generation quality. To determine optimal token reduction for different timesteps, we further design a search framework that leverages a classic evolutionary algorithm to automatically determine the distribution of the token budget effectively. Together, ASTRAEA achieves up to 2.4x inference speedup on a single GPU with great scalability (up to 13.2x speedup on 8 GPUs) while retaining better video quality compared to the state-of-the-art methods (<0.5% loss on the VBench score compared to the baseline vDiT models).
RainFusion: Adaptive Video Generation Acceleration via Multi-Dimensional Visual Redundancy
May 27, 2025Video generation using diffusion models is highly computationally intensive, with 3D attention in Diffusion Transformer (DiT) models accounting for over 80\% of the total computational resources. In this work, we introduce {\bf RainFusion}, a novel training-free sparse attention method that exploits inherent sparsity nature in visual data to accelerate attention computation while preserving video quality. Specifically, we identify three unique sparse patterns in video generation attention calculations--Spatial Pattern, Temporal Pattern and Textural Pattern. The sparse pattern for each attention head is determined online with negligible overhead (\textasciitilde\,0.2\%) with our proposed {\bf ARM} (Adaptive Recognition Module) during inference. Our proposed {\bf RainFusion} is a plug-and-play method, that can be seamlessly integrated into state-of-the-art 3D-attention video generation models without additional training or calibration. We evaluate our method on leading open-sourced models including HunyuanVideo, OpenSoraPlan-1.2 and CogVideoX-5B, demonstrating its broad applicability and effectiveness. Experimental results show that RainFusion achieves over {\bf 2\(\times\)} speedup in attention computation while maintaining video quality, with only a minimal impact on VBench scores (-0.2\%).
FreeKV: Boosting KV Cache Retrieval for Efficient LLM Inference
May 19, 2025Large language models (LLMs) have been widely deployed with rapidly expanding context windows to support increasingly demanding applications. However, long contexts pose significant deployment challenges, primarily due to the KV cache whose size grows proportionally with context length. While KV cache compression methods are proposed to address this issue, KV dropping methods incur considerable accuracy loss, and KV retrieval methods suffer from significant efficiency bottlenecks. We propose FreeKV, an algorithm-system co-optimization framework to enhance KV retrieval efficiency while preserving accuracy. On the algorithm side, FreeKV introduces speculative retrieval to shift the KV selection and recall processes out of the critical path, combined with fine-grained correction to ensure accuracy. On the system side, FreeKV employs hybrid KV layouts across CPU and GPU memory to eliminate fragmented data transfers, and leverages double-buffered streamed recall to further improve efficiency. Experiments demonstrate that FreeKV achieves near-lossless accuracy across various scenarios and models, delivering up to 13$\times$ speedup compared to SOTA KV retrieval methods.
Dynamic Low-Rank Sparse Adaptation for Large Language Models
Feb 20, 2025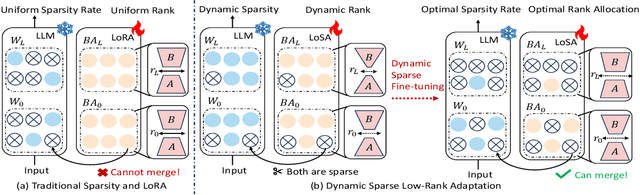
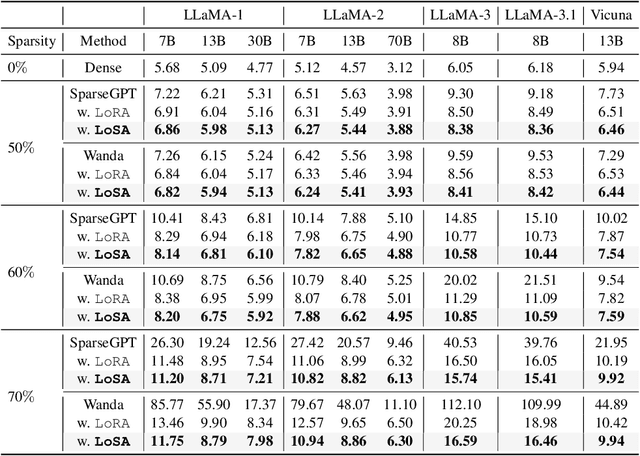
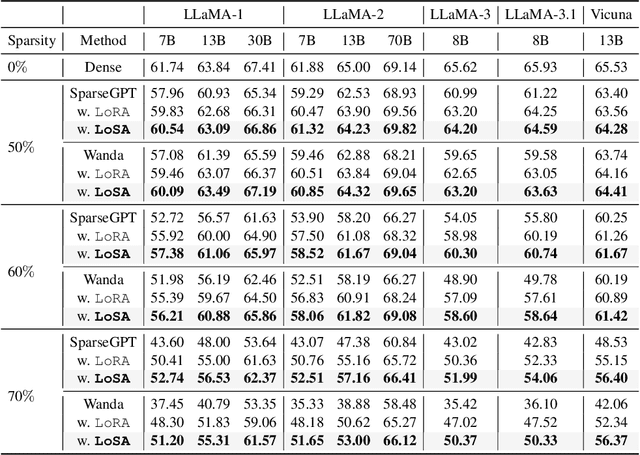
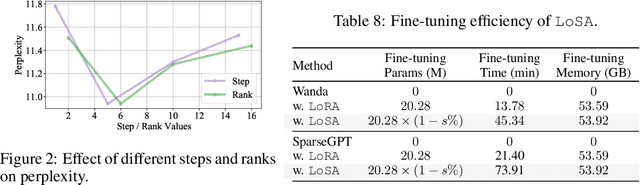
Despite the efficacy of network sparsity in alleviating the deployment strain of Large Language Models (LLMs), it endures significant performance degradation. Applying Low-Rank Adaptation (LoRA) to fine-tune the sparse LLMs offers an intuitive approach to counter this predicament, while it holds shortcomings include: 1) The inability to integrate LoRA weights into sparse LLMs post-training, and 2) Insufficient performance recovery at high sparsity ratios. In this paper, we introduce dynamic Low-rank Sparse Adaptation (LoSA), a novel method that seamlessly integrates low-rank adaptation into LLM sparsity within a unified framework, thereby enhancing the performance of sparse LLMs without increasing the inference latency. In particular, LoSA dynamically sparsifies the LoRA outcomes based on the corresponding sparse weights during fine-tuning, thus guaranteeing that the LoRA module can be integrated into the sparse LLMs post-training. Besides, LoSA leverages Representation Mutual Information (RMI) as an indicator to determine the importance of layers, thereby efficiently determining the layer-wise sparsity rates during fine-tuning. Predicated on this, LoSA adjusts the rank of the LoRA module based on the variability in layer-wise reconstruction errors, allocating an appropriate fine-tuning for each layer to reduce the output discrepancies between dense and sparse LLMs. Extensive experiments tell that LoSA can efficiently boost the efficacy of sparse LLMs within a few hours, without introducing any additional inferential burden. For example, LoSA reduced the perplexity of sparse LLaMA-2-7B by 68.73 and increased zero-shot accuracy by 16.32$\%$, achieving a 2.60$\times$ speedup on CPU and 2.23$\times$ speedup on GPU, requiring only 45 minutes of fine-tuning on a single NVIDIA A100 80GB GPU. Code is available at https://github.com/wzhuang-xmu/LoSA.
KVTuner: Sensitivity-Aware Layer-wise Mixed Precision KV Cache Quantization for Efficient and Nearly Lossless LLM Inference
Feb 06, 2025



KV cache quantization can improve Large Language Models (LLMs) inference throughput and latency in long contexts and large batch-size scenarios while preserving LLMs effectiveness. However, current methods have three unsolved issues: overlooking layer-wise sensitivity to KV cache quantization, high overhead of online fine-grained decision-making, and low flexibility to different LLMs and constraints. Therefore, we thoroughly analyze the inherent correlation of layer-wise transformer attention patterns to KV cache quantization errors and study why key cache is more important than value cache for quantization error reduction. We further propose a simple yet effective framework KVTuner to adaptively search for the optimal hardware-friendly layer-wise KV quantization precision pairs for coarse-grained KV cache with multi-objective optimization and directly utilize the offline searched configurations during online inference. To reduce the computational cost of offline calibration, we utilize the intra-layer KV precision pair pruning and inter-layer clustering to reduce the search space. Experimental results show that we can achieve nearly lossless 3.25-bit mixed precision KV cache quantization for LLMs like Llama-3.1-8B-Instruct and 4.0-bit for sensitive models like Qwen2.5-7B-Instruct on mathematical reasoning tasks. The maximum inference throughput can be improved by 38.3% compared with KV8 quantization over various context lengths.
RazorAttention: Efficient KV Cache Compression Through Retrieval Heads
Jul 22, 2024The memory and computational demands of Key-Value (KV) cache present significant challenges for deploying long-context language models. Previous approaches attempt to mitigate this issue by selectively dropping tokens, which irreversibly erases critical information that might be needed for future queries. In this paper, we propose a novel compression technique for KV cache that preserves all token information. Our investigation reveals that: i) Most attention heads primarily focus on the local context; ii) Only a few heads, denoted as retrieval heads, can essentially pay attention to all input tokens. These key observations motivate us to use separate caching strategy for attention heads. Therefore, we propose RazorAttention, a training-free KV cache compression algorithm, which maintains a full cache for these crucial retrieval heads and discards the remote tokens in non-retrieval heads. Furthermore, we introduce a novel mechanism involving a "compensation token" to further recover the information in the dropped tokens. Extensive evaluations across a diverse set of large language models (LLMs) demonstrate that RazorAttention achieves a reduction in KV cache size by over 70% without noticeable impacts on performance. Additionally, RazorAttention is compatible with FlashAttention, rendering it an efficient and plug-and-play solution that enhances LLM inference efficiency without overhead or retraining of the original model.
Dynamic Sparse No Training: Training-Free Fine-tuning for Sparse LLMs
Oct 17, 2023



The ever-increasing large language models (LLMs), though opening a potential path for the upcoming artificial general intelligence, sadly drops a daunting obstacle on the way towards their on-device deployment. As one of the most well-established pre-LLMs approaches in reducing model complexity, network pruning appears to lag behind in the era of LLMs, due mostly to its costly fine-tuning (or re-training) necessity under the massive volumes of model parameter and training data. To close this industry-academia gap, we introduce Dynamic Sparse No Training (DSnoT), a training-free fine-tuning approach that slightly updates sparse LLMs without the expensive backpropagation and any weight updates. Inspired by the Dynamic Sparse Training, DSnoT minimizes the reconstruction error between the dense and sparse LLMs, in the fashion of performing iterative weight pruning-and-growing on top of sparse LLMs. To accomplish this purpose, DSnoT particularly takes into account the anticipated reduction in reconstruction error for pruning and growing, as well as the variance w.r.t. different input data for growing each weight. This practice can be executed efficiently in linear time since its obviates the need of backpropagation for fine-tuning LLMs. Extensive experiments on LLaMA-V1/V2, Vicuna, and OPT across various benchmarks demonstrate the effectiveness of DSnoT in enhancing the performance of sparse LLMs, especially at high sparsity levels. For instance, DSnoT is able to outperform the state-of-the-art Wanda by 26.79 perplexity at 70% sparsity with LLaMA-7B. Our paper offers fresh insights into how to fine-tune sparse LLMs in an efficient training-free manner and open new venues to scale the great potential of sparsity to LLMs. Codes are available at https://github.com/zyxxmu/DSnoT.