 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATE OpenING: A Comprehensive Benchmark for Judging Open-ended Interleaved Image-Text Generation
Dec 01, 2024Multimodal Large Language Models (MLLMs) have made significant strides in visual understanding and generation tasks. However, generating interleaved image-text content remains a challenge, which requires integrated multimodal understanding and generation abilities. While the progress in unified models offers new solutions, existing benchmarks are insufficient for evaluating these methods due to data size and diversity limitations. To bridge this gap, we introduce GATE OpenING (OpenING), a comprehensive benchmark comprising 5,400 high-quality human-annotated instances across 56 real-world tasks. OpenING covers diverse daily scenarios such as travel guide, design, and brainstorming, offering a robust platform for challenging interleaved generation methods. In addition, we present IntJudge, a judge model for evaluating open-ended multimodal generation methods. Trained with a novel data pipeline, our IntJudge achieves an agreement rate of 82. 42% with human judgments, outperforming GPT-based evaluators by 11.34%. Extensive experiments on OpenING reveal that current interleaved generation methods still have substantial room for improvement. Key findings on interleaved image-text generation are further presented to guide the development of next-generation models. The OpenING is open-sourced at https://opening-benchmark.github.io.
Diffree: Text-Guided Shape Free Object Inpainting with Diffusion Model
Jul 24, 2024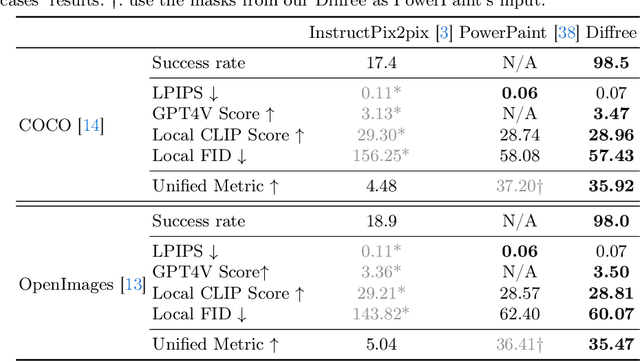



This paper addresses an important problem of object addition for images with only text guidance. It is challenging because the new object must be integrated seamlessly into the image with consistent visual context, such as lighting, texture, and spatial location. While existing text-guided image inpainting methods can add objects, they either fail to preserve the background consistency or involve cumbersome human intervention in specifying bounding boxes or user-scribbled masks. To tackle this challenge, we introduce Diffree, a Text-to-Image (T2I) model that facilitates text-guided object addition with only text control. To this end, we curate OABench, an exquisite synthetic dataset by removing objects with advanced image inpainting techniques. OABench comprises 74K real-world tuples of an original image, an inpainted image with the object removed, an object mask, and object descriptions. Trained on OABench using the Stable Diffusion model with an additional mask prediction module, Diffree uniquely predicts the position of the new object and achieves object addition with guidance from only text. Extensive experiments demonstrate that Diffree excels in adding new objects with a high success rate while maintaining background consistency, spatial appropriateness, and object relevance and quality.
DiffAgent: Fast and Accurate Text-to-Image API Selection with Large Language Model
Mar 31, 2024



Text-to-image (T2I) generative models have attracted significant attention and found extensive applications within and beyond academic research. For example, the Civitai community, a platform for T2I innovation, currently hosts an impressive array of 74,492 distinct models. However, this diversity presents a formidable challenge in selecting the most appropriate model and parameters, a process that typically requires numerous trials. Drawing inspiration from the tool usage research of large language models (LLMs), we introduce DiffAgent, an LLM agent designed to screen the accurate selection in seconds via API calls. DiffAgent leverages a novel two-stage training framework, SFTA, enabling it to accurately align T2I API responses with user input in accordance with human preferences. To train and evaluate DiffAgent's capabilities, we present DABench, a comprehensive dataset encompassing an extensive range of T2I APIs from the community. Our evaluations reveal that DiffAgent not only excels in identifying the appropriate T2I API but also underscores the effectiveness of the SFTA training framework. Codes are available at https://github.com/OpenGVLab/DiffAgent.
Boosting the Cross-Architecture Generalization of Dataset Distillation through an Empirical Study
Dec 09, 2023



The poor cross-architecture generalization of dataset distillation greatly weakens its practical significance. This paper attempts to mitigate this issue through an empirical study, which suggests that the synthetic datasets undergo an inductive bias towards the distillation model. Therefore, the evaluation model is strictly confined to having similar architectures of the distillation model. We propose a novel method of EvaLuation with distillation Feature (ELF), which utilizes features from intermediate layers of the distillation model for the cross-architecture evaluation. In this manner, the evaluation model learns from bias-free knowledge therefore its architecture becomes unfettered while retaining performance. By performing extensive experiments, we successfully prove that ELF can well enhance the cross-architecture generalization of current DD methods. Code of this project is at \url{https://github.com/Lirui-Zhao/ELF}.
Dynamic Sparse No Training: Training-Free Fine-tuning for Sparse LLMs
Oct 17, 2023



The ever-increasing large language models (LLMs), though opening a potential path for the upcoming artificial general intelligence, sadly drops a daunting obstacle on the way towards their on-device deployment. As one of the most well-established pre-LLMs approaches in reducing model complexity, network pruning appears to lag behind in the era of LLMs, due mostly to its costly fine-tuning (or re-training) necessity under the massive volumes of model parameter and training data. To close this industry-academia gap, we introduce Dynamic Sparse No Training (DSnoT), a training-free fine-tuning approach that slightly updates sparse LLMs without the expensive backpropagation and any weight updates. Inspired by the Dynamic Sparse Training, DSnoT minimizes the reconstruction error between the dense and sparse LLMs, in the fashion of performing iterative weight pruning-and-growing on top of sparse LLMs. To accomplish this purpose, DSnoT particularly takes into account the anticipated reduction in reconstruction error for pruning and growing, as well as the variance w.r.t. different input data for growing each weight. This practice can be executed efficiently in linear time since its obviates the need of backpropagation for fine-tuning LLMs. Extensive experiments on LLaMA-V1/V2, Vicuna, and OPT across various benchmarks demonstrate the effectiveness of DSnoT in enhancing the performance of sparse LLMs, especially at high sparsity levels. For instance, DSnoT is able to outperform the state-of-the-art Wanda by 26.79 perplexity at 70% sparsity with LLaMA-7B. Our paper offers fresh insights into how to fine-tune sparse LLMs in an efficient training-free manner and open new venues to scale the great potential of sparsity to LLMs. Codes are available at https://github.com/zyxxmu/DSnoT.
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models
Aug 25, 2023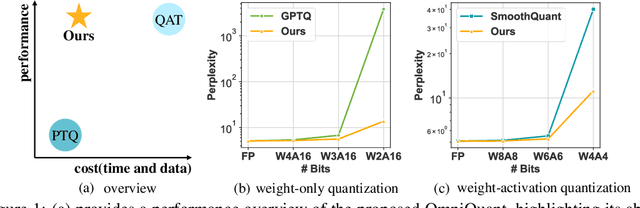

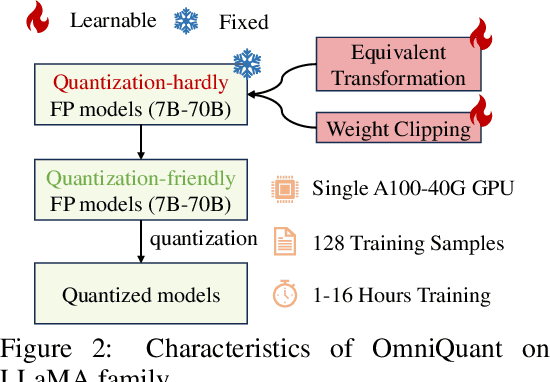
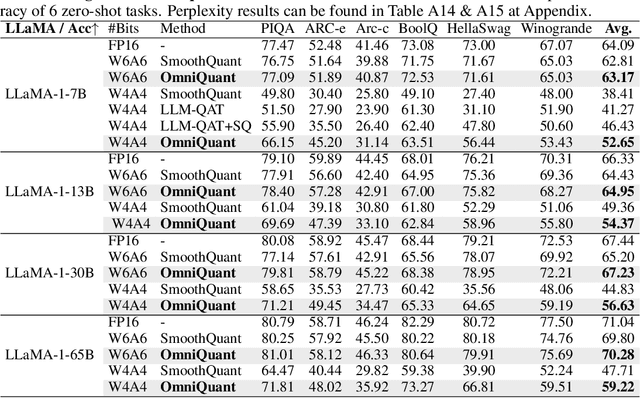
Large language models (LLMs) have revolutionized natural language processing tasks. However, their practical deployment is hindered by their immense memory and computation requirements. Although recent post-training quantization (PTQ) methods are effective in reducing memory footprint and improving the computational efficiency of LLM, they hand-craft quantization parameters, which leads to low performance and fails to deal with extremely low-bit quantization. To tackle this issue, we introduce an Omnidirectionally calibrated Quantization (OmniQuant) technique for LLMs, which achieves good performance in diverse quantization settings while maintaining the computational efficiency of PTQ by efficiently optimizing various quantization parameters. OmniQuant comprises two innovative components including Learnable Weight Clipping (LWC) and Learnable Equivalent Transformation (LET). LWC modulates the extreme values of weights by optimizing the clipping threshold. Meanwhile, LET tackles activation outliers by shifting the challenge of quantization from activations to weights through a learnable equivalent transformation. Operating within a differentiable framework using block-wise error minimization, OmniQuant can optimize the quantization process efficiently for both weight-only and weight-activation quantization. For instance, the LLaMA-2 model family with the size of 7-70B can be processed with OmniQuant on a single A100-40G GPU within 1-16 hours using 128 samples. Extensive experiments validate OmniQuant's superior performance across diverse quantization configurations such as W4A4, W6A6, W4A16, W3A16, and W2A16. Additionally, OmniQuant demonstrates effectiveness in instruction-tuned models and delivers notable improvements in inference speed and memory reduction on real devices. Codes and models are available at \url{https://github.com/OpenGVLab/OmniQuant}.