 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaltingVT: Adaptive Token Halting Transformer for Efficient Video Recognition
Jan 10, 2024
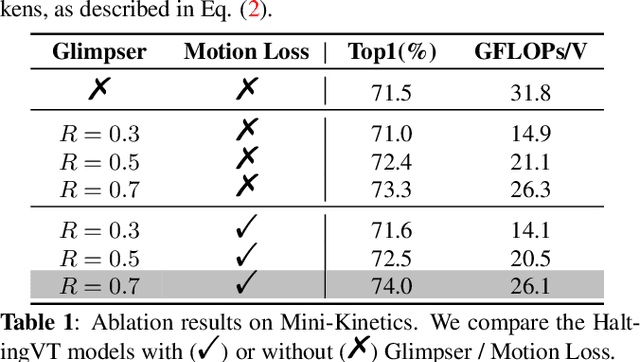
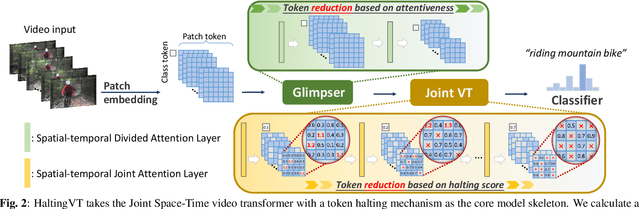
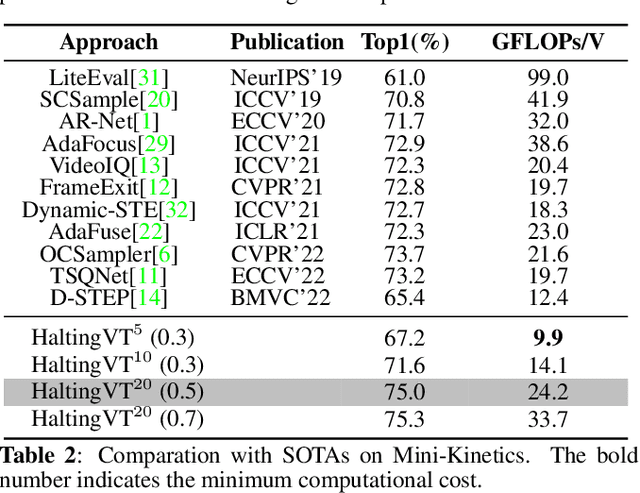
Action recognition in videos poses a challenge due to its high computational cost, especially for Joint Space-Time video transformers (Joint VT). Despite their effectiveness, the excessive number of tokens in such architectures significantly limits their efficiency. In this paper, we propose HaltingVT, an efficient video transformer adaptively removing redundant video patch tokens, which is primarily composed of a Joint VT and a Glimpser module. Specifically, HaltingVT applies data-adaptive token reduction at each layer, resulting in a significant reduction in the overall computational cost. Besides, the Glimpser module quickly removes redundant tokens in shallow transformer layers, which may even be misleading for video recognition tasks based on our observations. To further encourage HaltingVT to focus on the key motion-related information in videos, we design an effective Motion Loss during training. HaltingVT acquires video analysis capabilities and token halting compression strategies simultaneously in a unified training process, without requiring additional training procedures or sub-networks. On the Mini-Kinetics dataset, we achieved 75.0% top-1 ACC with 24.2 GFLOPs, as well as 67.2% top-1 ACC with an extremely low 9.9 GFLOPs. The code is available at https://github.com/dun-research/HaltingVT.
Acoustic Pornography Recognition Using Convolutional Neural Networks and Bag of Refinements
Nov 11, 2022A large number of pornographic audios publicly available on the Internet seriously threaten the mental and physical health of children, but these audios are rarely detected and filtered. In this paper, we firstly propose a convolutional neural networks (CNN) based model for acoustic pornography recognition. Then, we research a collection of refinements and verify their effectiveness through ablation studies. Finally, we stack all refinements together to verify whether they can further improve the accuracy of the model. Experimental results on our newly-collected large dataset consisting of 224127 pornographic audios and 274206 normal samples demonstrate the effectiveness of our proposed model and these refinements. Specifically, the proposed model achieves an accuracy of 92.46% and the accuracy is further improved to 97.19% when all refinements are combined.
Creating Lightweight Object Detectors with Model Compression for Deployment on Edge Devices
May 06, 2019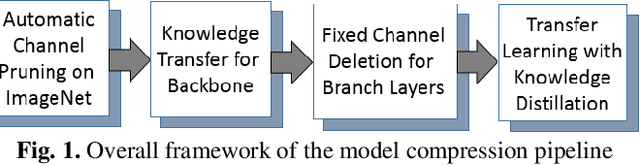
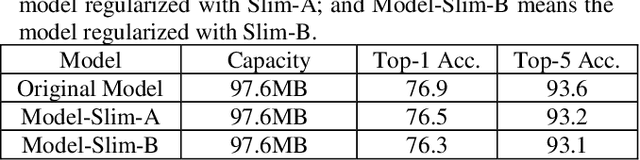
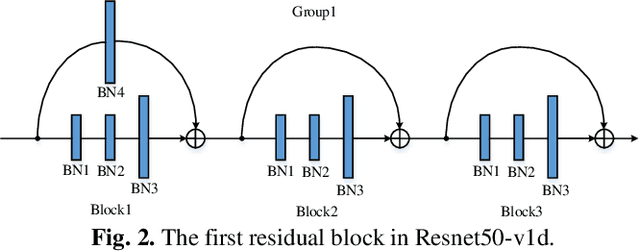
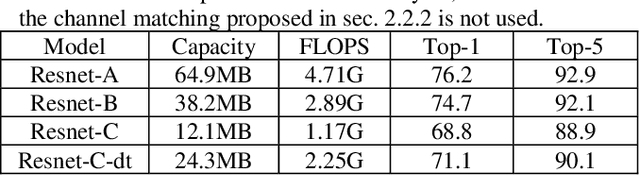
To achieve lightweight object detectors for deployment on the edge devices, an effective model compression pipeline is proposed in this paper. The compression pipeline consists of automatic channel pruning for the backbone, fixed channel deletion for the branch layers and knowledge distillation for the guidance learning. As results, the Resnet50-v1d is auto-pruned and fine-tuned on ImageNet to attain a compact base model as the backbone of object detector. Then, lightweight object detectors are implemented with proposed compression pipeline. For instance, the SSD-300 with model size=16.3MB, FLOPS=2.31G, and mAP=71.2 is created, revealing a better result than SSD-300-MobileNet.