 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaltingVT: Adaptive Token Halting Transformer for Efficient Video Recognition
Jan 10, 2024
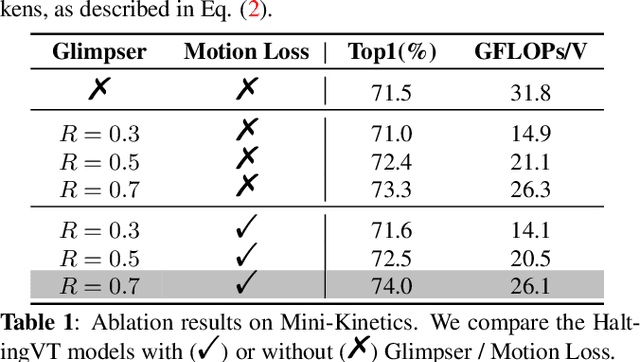
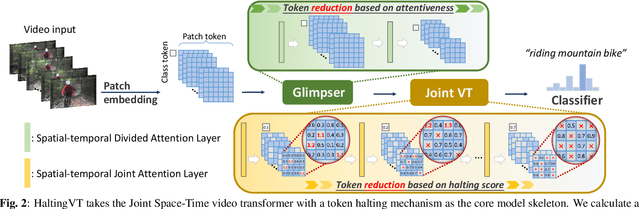
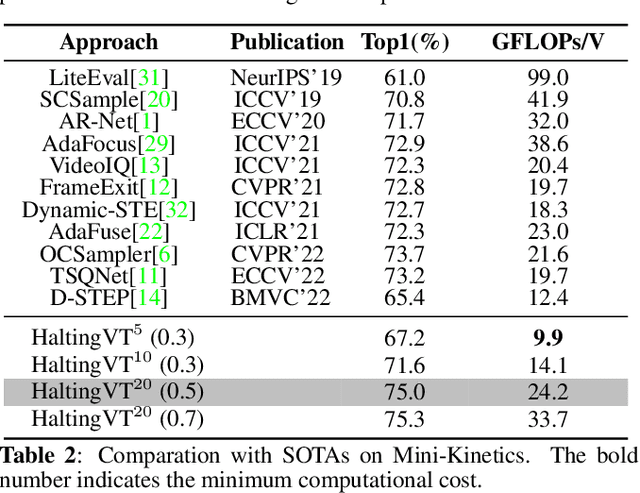
Action recognition in videos poses a challenge due to its high computational cost, especially for Joint Space-Time video transformers (Joint VT). Despite their effectiveness, the excessive number of tokens in such architectures significantly limits their efficiency. In this paper, we propose HaltingVT, an efficient video transformer adaptively removing redundant video patch tokens, which is primarily composed of a Joint VT and a Glimpser module. Specifically, HaltingVT applies data-adaptive token reduction at each layer, resulting in a significant reduction in the overall computational cost. Besides, the Glimpser module quickly removes redundant tokens in shallow transformer layers, which may even be misleading for video recognition tasks based on our observations. To further encourage HaltingVT to focus on the key motion-related information in videos, we design an effective Motion Loss during training. HaltingVT acquires video analysis capabilities and token halting compression strategies simultaneously in a unified training process, without requiring additional training procedures or sub-networks. On the Mini-Kinetics dataset, we achieved 75.0% top-1 ACC with 24.2 GFLOPs, as well as 67.2% top-1 ACC with an extremely low 9.9 GFLOPs. The code is available at https://github.com/dun-research/HaltingVT.