 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Learning of Anomalous Diffusion with Wavelet Representations: Enabling Direct Learning from Experimental Trajectories
Dec 09, 2025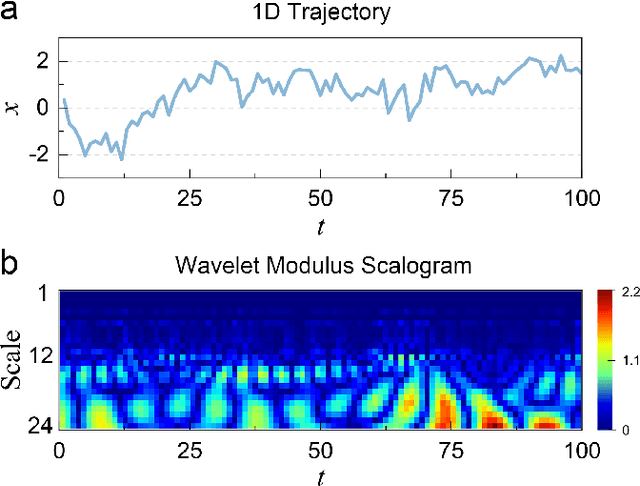
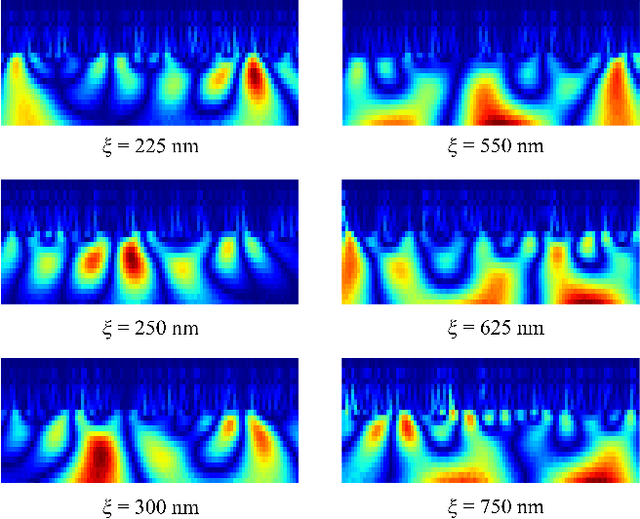
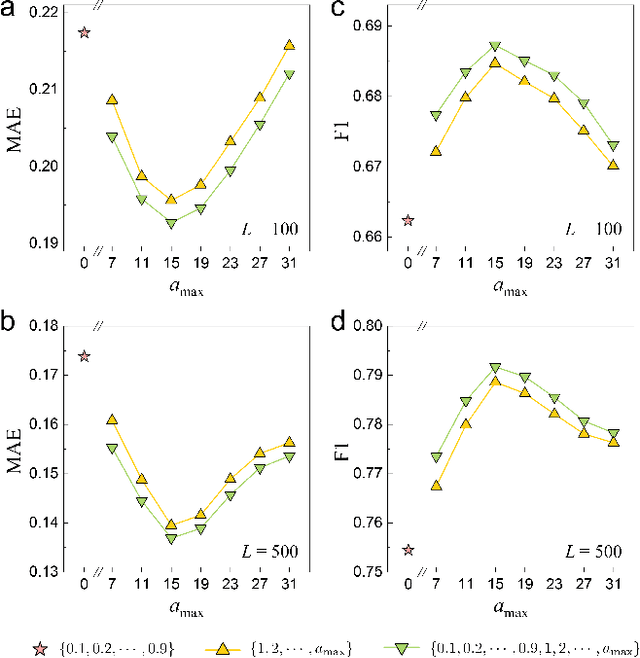
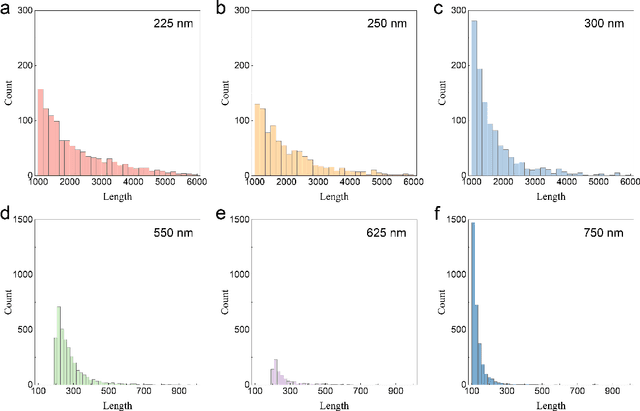
Machine learning (ML) has become a versatile tool for analyzing anomalous diffusion trajectories, yet most existing pipelines are trained on large collections of simulated data. In contrast, experimental trajectories, such as those from single-particle tracking (SPT), are typically scarce and may differ substantially from the idealized models used for simulation, leading to degradation or even breakdown of performance when ML methods are applied to real data. To address this mismatch, we introduce a wavelet-based representation of anomalous diffusion that enables data-efficient learning directly from experimental recordings. This representation is constructed by applying six complementary wavelet families to each trajectory and combining the resulting wavelet modulus scalograms. We first evaluate the wavelet representation on simulated trajectories from the andi-datasets benchmark, where it clearly outperforms both feature-based and trajectory-based methods with as few as 1000 training trajectories and still retains an advantage on large training sets. We then use this representation to learn directly from experimental SPT trajectories of fluorescent beads diffusing in F-actin networks, where the wavelet representation remains superior to existing alternatives for both diffusion-exponent regression and mesh-size classification. In particular, when predicting the diffusion exponents of experimental trajectories, a model trained on 1200 experimental tracks using the wavelet representation achieves significantly lower errors than state-of-the-art deep learning models trained purely on $10^6$ simulated trajectories. We associate this data efficiency with the emergence of distinct scale fingerprints disentangling underlying diffusion mechanisms in the wavelet spectra.
RainFusion: Adaptive Video Generation Acceleration via Multi-Dimensional Visual Redundancy
May 27, 2025Video generation using diffusion models is highly computationally intensive, with 3D attention in Diffusion Transformer (DiT) models accounting for over 80\% of the total computational resources. In this work, we introduce {\bf RainFusion}, a novel training-free sparse attention method that exploits inherent sparsity nature in visual data to accelerate attention computation while preserving video quality. Specifically, we identify three unique sparse patterns in video generation attention calculations--Spatial Pattern, Temporal Pattern and Textural Pattern. The sparse pattern for each attention head is determined online with negligible overhead (\textasciitilde\,0.2\%) with our proposed {\bf ARM} (Adaptive Recognition Module) during inference. Our proposed {\bf RainFusion} is a plug-and-play method, that can be seamlessly integrated into state-of-the-art 3D-attention video generation models without additional training or calibration. We evaluate our method on leading open-sourced models including HunyuanVideo, OpenSoraPlan-1.2 and CogVideoX-5B, demonstrating its broad applicability and effectiveness. Experimental results show that RainFusion achieves over {\bf 2\(\times\)} speedup in attention computation while maintaining video quality, with only a minimal impact on VBench scores (-0.2\%).
Reinforcement Learning for Active Matter
Mar 30, 2025Active matter refers to systems composed of self-propelled entities that consume energy to produce motion, exhibiting complex non-equilibrium dynamics that challenge traditional models. With the rapid advancements in machine learning, reinforcement learning (RL) has emerged as a promising framework for addressing the complexities of active matter. This review systematically introduces the integration of RL for guiding and controlling active matter systems, focusing on two key aspects: optimal motion strategies for individual active particles and the regulation of collective dynamics in active swarms. We discuss the use of RL to optimize the navigation, foraging, and locomotion strategies for individual active particles. In addition, the application of RL in regulating collective behaviors is also examined, emphasizing its role in facilitating the self-organization and goal-directed control of active swarms. This investigation offers valuable insights into how RL can advance the understanding, manipulation, and control of active matter, paving the way for future developments in fields such as biological systems, robotics, and medical science.
Machine Learning Analysis of Anomalous Diffusion
Dec 02, 2024



The rapid advancements in machine learning have made its application to anomalous diffusion analysis both essential and inevitable. This review systematically introduces the integration of machine learning techniques for enhanced analysis of anomalous diffusion, focusing on two pivotal aspects: single trajectory characterization via machine learning and representation learning of anomalous diffusion. We extensively compare various machine learning methods, including both classical machine learning and deep learning, used for the inference of diffusion parameters and trajectory segmentation. Additionally, platforms such as the Anomalous Diffusion Challenge that serve as benchmarks for evaluating these methods are highlighted. On the other hand, we outline three primary strategies for representing anomalous diffusion: the combination of predefined features, the feature vector from the penultimate layer of neural network, and the latent representation from the autoencoder, analyzing their applicability across various scenarios. This investigation paves the way for future research, offering valuable perspectives that can further enrich the study of anomalous diffusion and advance the application of artificial intelligence in statistical physics and biophysics.
RazorAttention: Efficient KV Cache Compression Through Retrieval Heads
Jul 22, 2024The memory and computational demands of Key-Value (KV) cache present significant challenges for deploying long-context language models. Previous approaches attempt to mitigate this issue by selectively dropping tokens, which irreversibly erases critical information that might be needed for future queries. In this paper, we propose a novel compression technique for KV cache that preserves all token information. Our investigation reveals that: i) Most attention heads primarily focus on the local context; ii) Only a few heads, denoted as retrieval heads, can essentially pay attention to all input tokens. These key observations motivate us to use separate caching strategy for attention heads. Therefore, we propose RazorAttention, a training-free KV cache compression algorithm, which maintains a full cache for these crucial retrieval heads and discards the remote tokens in non-retrieval heads. Furthermore, we introduce a novel mechanism involving a "compensation token" to further recover the information in the dropped tokens. Extensive evaluations across a diverse set of large language models (LLMs) demonstrate that RazorAttention achieves a reduction in KV cache size by over 70% without noticeable impacts on performance. Additionally, RazorAttention is compatible with FlashAttention, rendering it an efficient and plug-and-play solution that enhances LLM inference efficiency without overhead or retraining of the original model.