 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic Fundus Image Enhancement Network Boosted by Frequency Self-supervised Representation Learning
Sep 02, 2023



Fundus photography is prone to suffer from image quality degradation that impacts clinical examination performed by ophthalmologists or intelligent systems. Though enhancement algorithms have been developed to promote fundus observation on degraded images, high data demands and limited applicability hinder their clinical deployment. To circumvent this bottleneck, a generic fundus image enhancement network (GFE-Net) is developed in this study to robustly correct unknown fundus images without supervised or extra data. Levering image frequency information, self-supervised representation learning is conducted to learn robust structure-aware representations from degraded images. Then with a seamless architecture that couples representation learning and image enhancement, GFE-Net can accurately correct fundus images and meanwhile preserve retinal structures. Comprehensive experiments are implemented to demonstrate the effectiveness and advantages of GFE-Net. Compared with state-of-the-art algorithms, GFE-Net achieves superior performance in data dependency, enhancement performance, deployment efficiency, and scale generalizability. Follow-up fundus image analysis is also facilitated by GFE-Net, whose modules are respectively verified to be effective for image enhancement.
UniASM: Binary Code Similarity Detection without Fine-tuning
Nov 07, 2022Binary code similarity detection (BCSD) is widely used in various binary analysis tasks such as vulnerability search, malware detection, clone detection, and patch analysis. Recent studies have shown that the learning-based binary code embedding models perform better than the traditional feature-based approaches. In this paper, we proposed a novel transformer-based binary code embedding model, named UniASM, to learn representations of the binary functions. We designed two new training tasks to make the spatial distribution of the generated vectors more uniform, which can be used directly in BCSD without any fine-tuning. In addition, we proposed a new tokenization approach for binary functions, increasing the token's semantic information while mitigating the out-of-vocabulary (OOV) problem. The experimental results show that UniASM outperforms state-of-the-art (SOTA) approaches on the evaluation dataset. We achieved the average scores of recall@1 on cross-compilers, cross-optimization-levels and cross-obfuscations are 0.72, 0.63, and 0.77, which is higher than existing SOTA baselines. In a real-world task of known vulnerability searching, UniASM outperforms all the current baselines.
Walle: An End-to-End, General-Purpose, and Large-Scale Production System for Device-Cloud Collaborative Machine Learning
May 30, 2022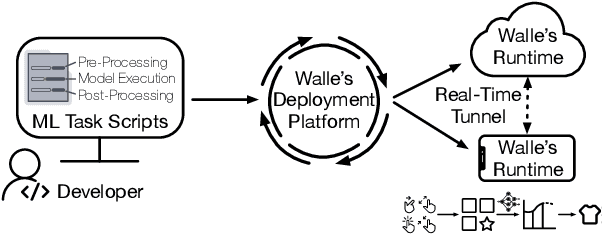
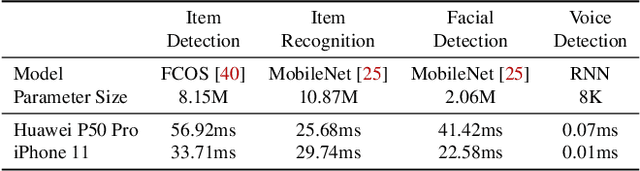
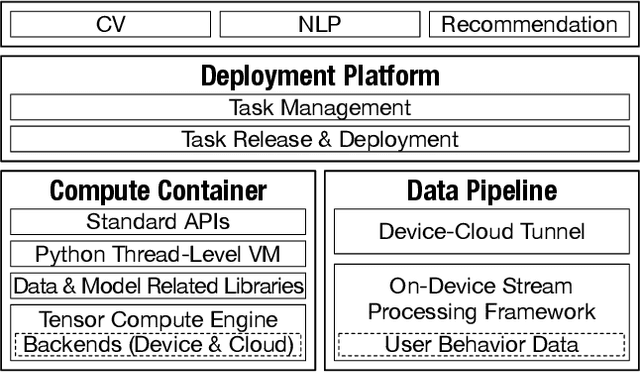

To break the bottlenecks of mainstream cloud-based machine learning (ML) paradigm, we adopt device-cloud collaborative ML and build the first end-to-end and general-purpose system, called Walle, as the foundation. Walle consists of a deployment platform, distributing ML tasks to billion-scale devices in time; a data pipeline, efficiently preparing task input; and a compute container, providing a cross-platform and high-performance execution environment, while facilitating daily task iteration. Specifically, the compute container is based on Mobile Neural Network (MNN), a tensor compute engine along with the data processing and model execution libraries, which are exposed through a refined Python thread-level virtual machine (VM) to support diverse ML tasks and concurrent task execution. The core of MNN is the novel mechanisms of operator decomposition and semi-auto search, sharply reducing the workload in manually optimizing hundreds of operators for tens of hardware backends and further quickly identifying the best backend with runtime optimization for a computation graph. The data pipeline introduces an on-device stream processing framework to enable processing user behavior data at source. The deployment platform releases ML tasks with an efficient push-then-pull method and supports multi-granularity deployment policies. We evaluate Walle in practical e-commerce application scenarios to demonstrate its effectiveness, efficiency, and scalability. Extensive micro-benchmarks also highlight the superior performance of MNN and the Python thread-level VM. Walle has been in large-scale production use in Alibaba, while MNN has been open source with a broad impact in the community.
INT8 Winograd Acceleration for Conv1D Equipped ASR Models Deployed on Mobile Devices
Oct 28, 2020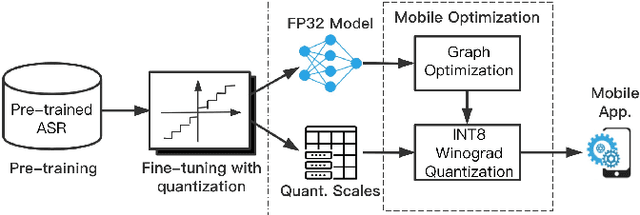
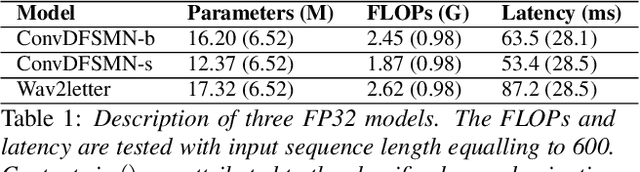

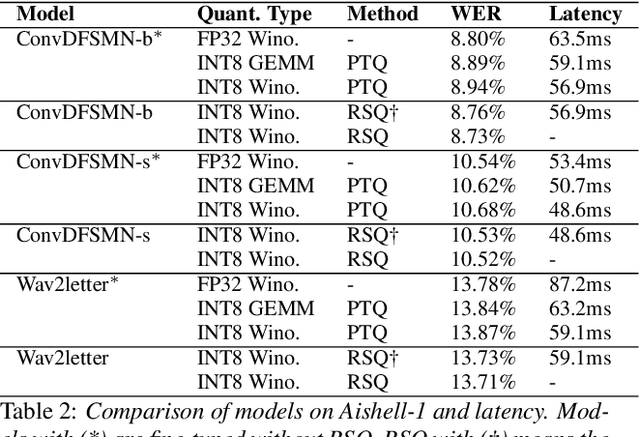
The intensive computation of Automatic Speech Recognition (ASR) models obstructs them from being deployed on mobile devices. In this paper, we present a novel quantized Winograd optimization pipeline, which combines the quantization and fast convolution to achieve efficient inference acceleration on mobile devices for ASR models. To avoid the information loss due to the combination of quantization and Winograd convolution, a Range-Scaled Quantization (RSQ) training method is proposed to expand the quantized numerical range and to distill knowledge from high-precision values. Moreover, an improved Conv1D equipped DFSMN (ConvDFSMN) model is designed for mobile deployment. We conduct extensive experiments on both ConvDFSMN and Wav2letter models. Results demonstrate the models can be effectively optimized with the proposed pipeline. Especially, Wav2letter achieves 1.48* speedup with an approximate 0.07% WER decrease on ARMv7-based mobile devices.