 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapt as You Say: Online Interactive Bimanual Skill Adaptation via Human Language Feedback
Mar 27, 2026Developing general-purpose robots capable of autonomously operating in human living environments requires the ability to adapt to continuously evolving task conditions. However, adapting high-dimensional coordinated bimanual skills to novel task variations at deployment remains a fundamental challenge. In this work, we present BiSAIL (Bimanual Skill Adaptation via Interactive Language), a novel framework that enables zero-shot online adaptation of offline-learned bimanual skills through interactive language feedback. The key idea of BiSAIL is to adopt a hierarchical reason-then-modulate paradigm, which first infers generalized adaptation objectives from multimodal task variations, and then adapts bimanual motions via diffusion modulation to achieve the inferred objectives. Extensive real-robot experiments across six bimanual tasks and two dual-arm platforms demonstrate that BiSAIL significantly outperforms existing methods in human-in-the-loop adaptability, task generalization and cross-embodiment scalability. This work enables the development of adaptive bimanual assistants that can be flexibly customized by non-expert users via intuitive verbal corrections. Experimental videos and code are available at https://rip4kobe.github.io/BiSAIL/.
Disentangling perception and reasoning for improving data efficiency in learning cloth manipulation without demonstrations
Jan 29, 2026Cloth manipulation is a ubiquitous task in everyday life, but it remains an open challenge for robotics. The difficulties in developing cloth manipulation policies are attributed to the high-dimensional state space, complex dynamics, and high propensity to self-occlusion exhibited by fabrics. As analytical methods have not been able to provide robust and general manipulation policies, reinforcement learning (RL) is considered a promising approach to these problems. However, to address the large state space and complex dynamics, data-based methods usually rely on large models and long training times. The resulting computational cost significantly hampers the development and adoption of these methods. Additionally, due to the challenge of robust state estimation, garment manipulation policies often adopt an end-to-end learning approach with workspace images as input. While this approach enables a conceptually straightforward sim-to-real transfer via real-world fine-tuning, it also incurs a significant computational cost by training agents on a highly lossy representation of the environment state. This paper questions this common design choice by exploring an efficient and modular approach to RL for cloth manipulation. We show that, through careful design choices, model size and training time can be significantly reduced when learning in simulation. Furthermore, we demonstrate how the resulting simulation-trained model can be transferred to the real world. We evaluate our approach on the SoftGym benchmark and achieve significant performance improvements over available baselines on our task, while using a substantially smaller model.
Interactive Motion Planning for Human-Robot Collaboration Based on Human-Centric Configuration Space Ergonomic Field
Dec 16, 2025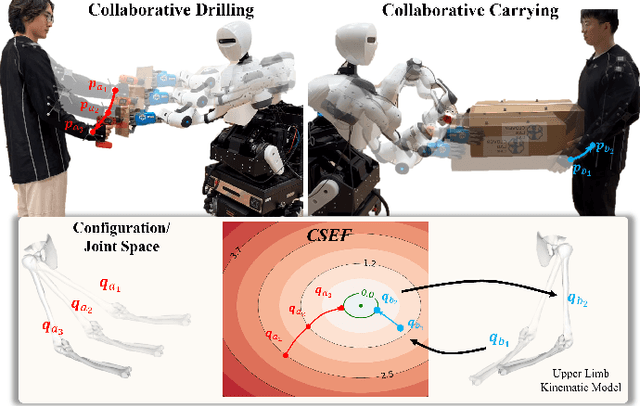
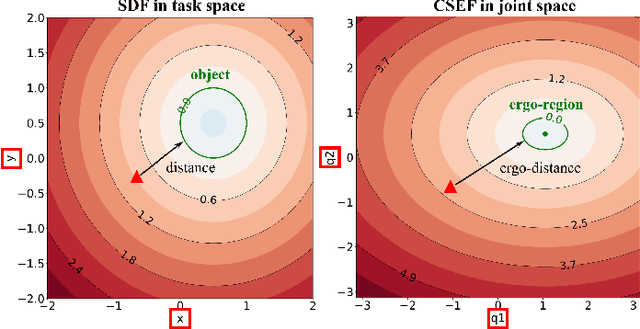
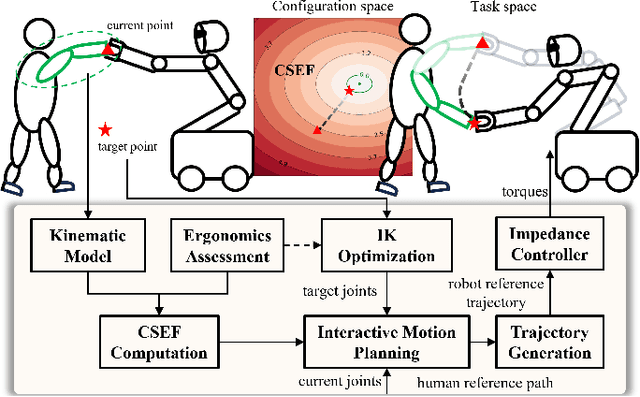
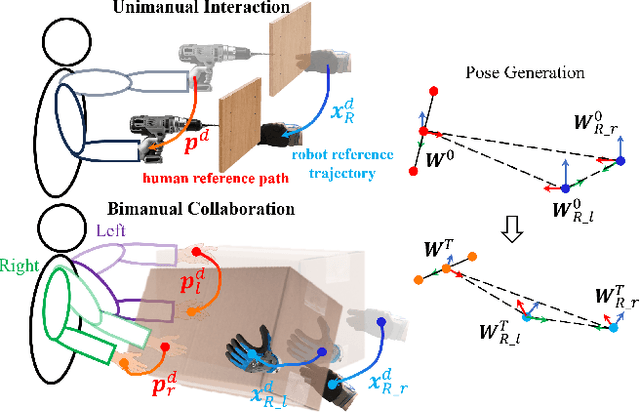
Industrial human-robot collaboration requires motion planning that is collision-free, responsive, and ergonomically safe to reduce fatigue and musculoskeletal risk. We propose the Configuration Space Ergonomic Field (CSEF), a continuous and differentiable field over the human joint space that quantifies ergonomic quality and provides gradients for real-time ergonomics-aware planning. An efficient algorithm constructs CSEF from established metrics with joint-wise weighting and task conditioning, and we integrate it into a gradient-based planner compatible with impedance-controlled robots. In a 2-DoF benchmark, CSEF-based planning achieves higher success rates, lower ergonomic cost, and faster computation than a task-space ergonomic planner. Hardware experiments with a dual-arm robot in unimanual guidance, collaborative drilling, and bimanual cocarrying show faster ergonomic cost reduction, closer tracking to optimized joint targets, and lower muscle activation than a point-to-point baseline. CSEF-based planning method reduces average ergonomic scores by up to 10.31% for collaborative drilling tasks and 5.60% for bimanual co-carrying tasks while decreasing activation in key muscle groups, indicating practical benefits for real-world deployment.
Towards Deploying VLA without Fine-Tuning: Plug-and-Play Inference-Time VLA Policy Steering via Embodied Evolutionary Diffusion
Nov 18, 2025Vision-Language-Action (VLA) models have demonstrated significant potential in real-world robotic manipulation. However, pre-trained VLA policies still suffer from substantial performance degradation during downstream deployment. Although fine-tuning can mitigate this issue, its reliance on costly demonstration collection and intensive computation makes it impractical in real-world settings. In this work, we introduce VLA-Pilot, a plug-and-play inference-time policy steering method for zero-shot deployment of pre-trained VLA without any additional fine-tuning or data collection. We evaluate VLA-Pilot on six real-world downstream manipulation tasks across two distinct robotic embodiments, encompassing both in-distribution and out-of-distribution scenarios. Experimental results demonstrate that VLA-Pilot substantially boosts the success rates of off-the-shelf pre-trained VLA policies, enabling robust zero-shot generalization to diverse tasks and embodiments. Experimental videos and code are available at: https://rip4kobe.github.io/vla-pilot/.
ManiDP: Manipulability-Aware Diffusion Policy for Posture-Dependent Bimanual Manipulation
Oct 27, 2025Recent work has demonstrated the potential of diffusion models in robot bimanual skill learning. However, existing methods ignore the learning of posture-dependent task features, which are crucial for adapting dual-arm configurations to meet specific force and velocity requirements in dexterous bimanual manipulation. To address this limitation, we propose Manipulability-Aware Diffusion Policy (ManiDP), a novel imitation learning method that not only generates plausible bimanual trajectories, but also optimizes dual-arm configurations to better satisfy posture-dependent task requirements. ManiDP achieves this by extracting bimanual manipulability from expert demonstrations and encoding the encapsulated posture features using Riemannian-based probabilistic models. These encoded posture features are then incorporated into a conditional diffusion process to guide the generation of task-compatible bimanual motion sequences. We evaluate ManiDP on six real-world bimanual tasks, where the experimental results demonstrate a 39.33$\%$ increase in average manipulation success rate and a 0.45 improvement in task compatibility compared to baseline methods. This work highlights the importance of integrating posture-relevant robotic priors into bimanual skill diffusion to enable human-like adaptability and dexterity.
Human-Like Robot Impedance Regulation Skill Learning from Human-Human Demonstrations
Feb 19, 2025Humans are experts in collaborating with others physically by regulating compliance behaviors based on the perception of their partner states and the task requirements. Enabling robots to develop proficiency in human collaboration skills can facilitate more efficient human-robot collaboration (HRC). This paper introduces an innovative impedance regulation skill learning framework for achieving HRC in multiple physical collaborative tasks. The framework is designed to adjust the robot compliance to the human partner states while adhering to reference trajectories provided by human-human demonstrations. Specifically, electromyography (EMG) signals from human muscles are collected and analyzed to extract limb impedance, representing compliance behaviors during demonstrations. Human endpoint motions are captured and represented using a probabilistic learning method to create reference trajectories and corresponding impedance profiles. Meanwhile, an LSTMbased module is implemented to develop task-oriented impedance regulation policies by mapping the muscle synergistic contributions between two demonstrators. Finally, we propose a wholebody impedance controller for a human-like robot, coordinating joint outputs to achieve the desired impedance and reference trajectory during task execution. Experimental validation was conducted through a collaborative transportation task and two interactive Tai Chi pushing hands tasks, demonstrating superior performance from the perspective of interactive forces compared to a constant impedance control method.
Human-Humanoid Robots Cross-Embodiment Behavior-Skill Transfer Using Decomposed Adversarial Learning from Demonstration
Dec 19, 2024Humanoid robots are envisioned as embodied intelligent agents capable of performing a wide range of human-level loco-manipulation tasks, particularly in scenarios requiring strenuous and repetitive labor. However, learning these skills is challenging due to the high degrees of freedom of humanoid robots, and collecting sufficient training data for humanoid is a laborious process. Given the rapid introduction of new humanoid platforms, a cross-embodiment framework that allows generalizable skill transfer is becoming increasingly critical. To address this, we propose a transferable framework that reduces the data bottleneck by using a unified digital human model as a common prototype and bypassing the need for re-training on every new robot platform. The model learns behavior primitives from human demonstrations through adversarial imitation, and the complex robot structures are decomposed into functional components, each trained independently and dynamically coordinated. Task generalization is achieved through a human-object interaction graph, and skills are transferred to different robots via embodiment-specific kinematic motion retargeting and dynamic fine-tuning. Our framework is validated on five humanoid robots with diverse configurations, demonstrating stable loco-manipulation and highlighting its effectiveness in reducing data requirements and increasing the efficiency of skill transfer across platforms.
Towards Precise Pruning Points Detection using Semantic-Instance-Aware Plant Models for Grapevine Winter Pruning Automation
Sep 15, 2021
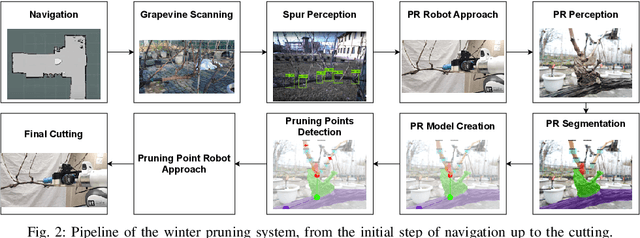
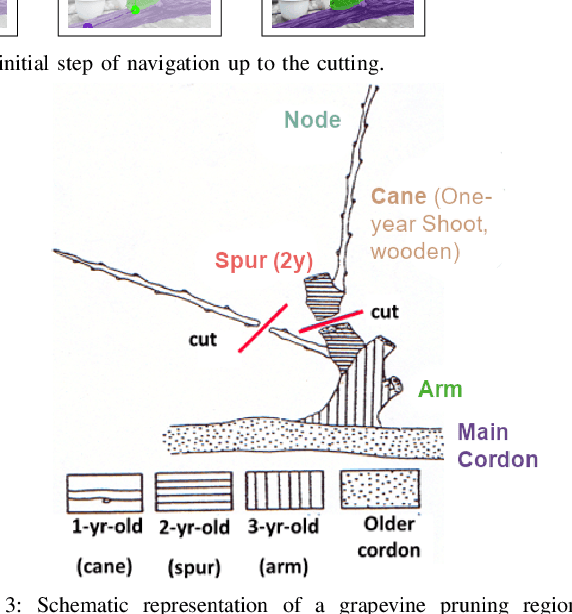

Grapevine winter pruning is a complex task, that requires skilled workers to execute it correctly. The complexity makes it time consuming. It is an operation that requires about 80-120 hours per hectare annually, making an automated robotic system that helps in speeding up the process a crucial tool in large-size vineyards. We will describe (a) a novel expert annotated dataset for grapevine segmentation, (b) a state of the art neural network implementation and (c) generation of pruning points following agronomic rules, leveraging the simplified structure of the plant. With this approach, we are able to generate a set of pruning points on the canes, paving the way towards a correct automation of grapevine winter pruning.
Grapevine Winter Pruning Automation: On Potential Pruning Points Detection through 2D Plant Modeling using Grapevine Segmentation
Jun 08, 2021



Grapevine winter pruning is a complex task, that requires skilled workers to execute it correctly. The complexity of this task is also the reason why it is time consuming. Considering that this operation takes about 80-120 hours/ha to be completed, and therefore is even more crucial in large-size vineyards, an automated system can help to speed up the process. To this end, this paper presents a novel multidisciplinary approach that tackles this challenging task by performing object segmentation on grapevine images, used to create a representative model of the grapevine plants. Second, a set of potential pruning points is generated from this plant representation. We will describe (a) a methodology for data acquisition and annotation, (b) a neural network fine-tuning for grapevine segmentation, (c) an image processing based method for creating the representative model of grapevines, starting from the inferred segmentation and (d) potential pruning points detection and localization, based on the plant model which is a simplification of the grapevine structure. With this approach, we are able to identify a significant set of potential pruning points on the canes, that can be used, with further selection, to derive the final set of the real pruning points.
Whole-Body Control on Non-holonomic Mobile Manipulation for Grapevine Winter Pruning Automation
May 22, 2021
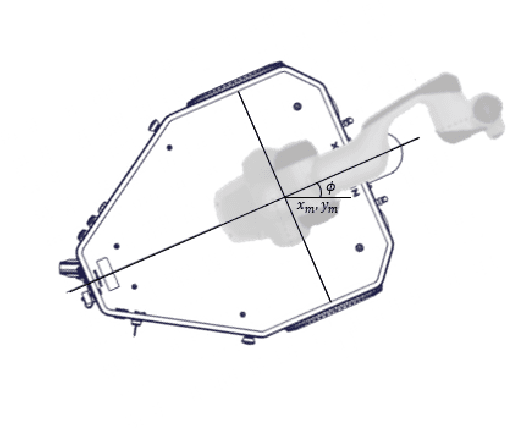
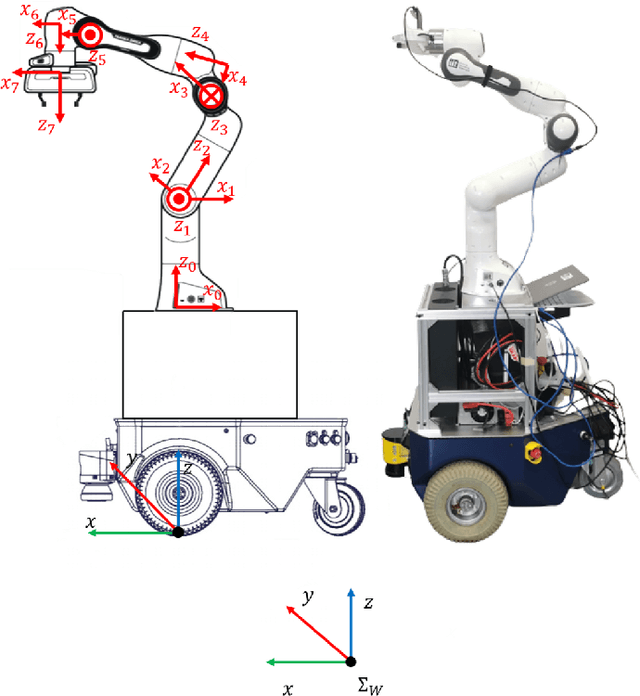
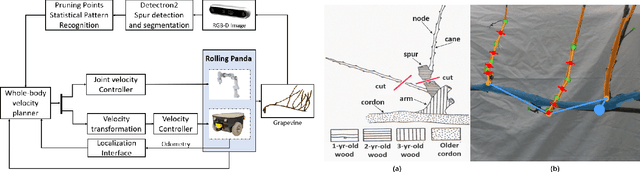
Mobile manipulators that combine mobility and manipulability, are increasingly being used for various unstructured application scenarios in the field, e.g. vineyards. Therefore, the coordinated motion of the mobile base and manipulator is an essential feature of the overall performance. In this paper, we explore a whole-body motion controller of a robot which is composed of a 2-DoFs non-holonomic wheeled mobile base with a 7-DoFs manipulator (non-holonomic wheeled mobile manipulator, NWMM) This robotic platform is designed to efficiently undertake complex grapevine pruning tasks. In the control framework, a task priority coordinated motion of the NWMM is guaranteed. Lower-priority tasks are projected into the null space of the top-priority tasks so that higher-priority tasks are completed without interruption from lower-priority tasks. The proposed controller was evaluated in a grapevine spur pruning experiment scenario.