 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dubbing: End-to-End Auto-Audiobook System with Text-to-Timbre and Context-Aware Instruct-TTS
Sep 19, 2025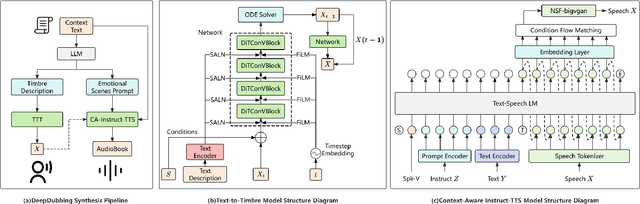


The pipeline for multi-participant audiobook production primarily consists of three stages: script analysis, character voice timbre selection, and speech synthesis. Among these, script analysis can be automated with high accuracy using NLP models, whereas character voice timbre selection still relies on manual effort. Speech synthesis uses either manual dubbing or text-to-speech (TTS). While TTS boosts efficiency, it struggles with emotional expression, intonation control, and contextual scene adaptation. To address these challenges, we propose DeepDubbing, an end-to-end automated system for multi-participant audiobook production. The system comprises two main components: a Text-to-Timbre (TTT) model and a Context-Aware Instruct-TTS (CA-Instruct-TTS) model. The TTT model generates role-specific timbre embeddings conditioned on text descriptions. The CA-Instruct-TTS model synthesizes expressive speech by analyzing contextual dialogue and incorporating fine-grained emotional instructions. This system enables the automated generation of multi-participant audiobooks with both timbre-matched character voices and emotionally expressive narration, offering a novel solution for audiobook production.
Online Learning with Probing for Sequential User-Centric Selection
Jul 27, 2025
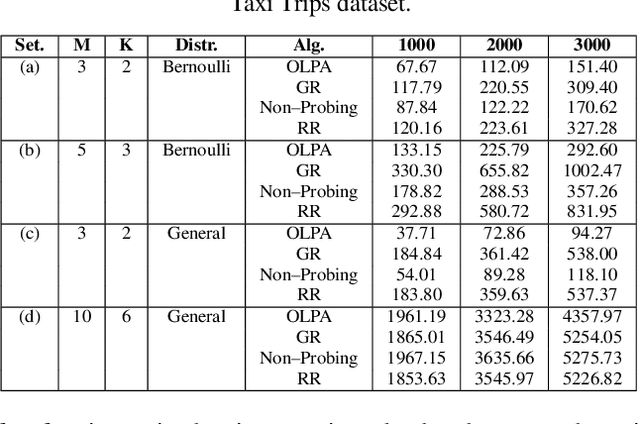

We formalize sequential decision-making with information acquisition as the probing-augmented user-centric selection (PUCS) framework, where a learner first probes a subset of arms to obtain side information on resources and rewards, and then assigns $K$ plays to $M$ arms. PUCS covers applications such as ridesharing, wireless scheduling, and content recommendation, in which both resources and payoffs are initially unknown and probing is costly. For the offline setting with known distributions, we present a greedy probing algorithm with a constant-factor approximation guarantee $\zeta = (e-1)/(2e-1)$. For the online setting with unknown distributions, we introduce OLPA, a stochastic combinatorial bandit algorithm that achieves a regret bound $\mathcal{O}(\sqrt{T} + \ln^{2} T)$. We also prove a lower bound $\Omega(\sqrt{T})$, showing that the upper bound is tight up to logarithmic factors. Experiments on real-world data demonstrate the effectiveness of our solutions.
B4P: Simultaneous Grasp and Motion Planning for Object Placement via Parallelized Bidirectional Forests and Path Repair
Apr 06, 2025Robot pick and place systems have traditionally decoupled grasp, placement, and motion planning to build sequential optimization pipelines with the assumption that the individual components will be able to work together. However, this separation introduces sub-optimality, as grasp choices may limit or even prohibit feasible motions for a robot to reach the target placement pose, particularly in cluttered environments with narrow passages. To this end, we propose a forest-based planning framework to simultaneously find grasp configurations and feasible robot motions that explicitly satisfy downstream placement configurations paired with the selected grasps. Our proposed framework leverages a bidirectional sampling-based approach to build a start forest, rooted at the feasible grasp regions, and a goal forest, rooted at the feasible placement regions, to facilitate the search through randomly explored motions that connect valid pairs of grasp and placement trees. We demonstrate that the framework's inherent parallelism enables superlinear speedup, making it scalable for applications for redundant robot arms (e.g., 7 Degrees of Freedom) to work efficiently in highly cluttered environments. Extensive experiments in simulation demonstrate the robustness and efficiency of the proposed framework in comparison with multiple baselines under diverse scenarios.
ARC-Calib: Autonomous Markerless Camera-to-Robot Calibration via Exploratory Robot Motions
Mar 18, 2025Camera-to-robot (also known as eye-to-hand) calibration is a critical component of vision-based robot manipulation. Traditional marker-based methods often require human intervention for system setup. Furthermore, existing autonomous markerless calibration methods typically rely on pre-trained robot tracking models that impede their application on edge devices and require fine-tuning for novel robot embodiments. To address these limitations, this paper proposes a model-based markerless camera-to-robot calibration framework, ARC-Calib, that is fully autonomous and generalizable across diverse robots and scenarios without requiring extensive data collection or learning. First, exploratory robot motions are introduced to generate easily trackable trajectory-based visual patterns in the camera's image frames. Then, a geometric optimization framework is proposed to exploit the coplanarity and collinearity constraints from the observed motions to iteratively refine the estimated calibration result. Our approach eliminates the need for extra effort in either environmental marker setup or data collection and model training, rendering it highly adaptable across a wide range of real-world autonomous systems. Extensive experiments are conducted in both simulation and the real world to validate its robustness and generalizability.
ImplicitCell: Resolution Cell Modeling of Joint Implicit Volume Reconstruction and Pose Refinement in Freehand 3D Ultrasound
Mar 09, 2025Freehand 3D ultrasound enables volumetric imaging by tracking a conventional ultrasound probe during freehand scanning, offering enriched spatial information that improves clinical diagnosis. However, the quality of reconstructed volumes is often compromised by tracking system noise and irregular probe movements, leading to artifacts in the final reconstruction. To address these challenges, we propose ImplicitCell, a novel framework that integrates Implicit Neural Representation (INR) with an ultrasound resolution cell model for joint optimization of volume reconstruction and pose refinement. Three distinct datasets are used for comprehensive validation, including phantom, common carotid artery, and carotid atherosclerosis. Experimental results demonstrate that ImplicitCell significantly reduces reconstruction artifacts and improves volume quality compared to existing methods, particularly in challenging scenarios with noisy tracking data. These improvements enhance the clinical utility of freehand 3D ultrasound by providing more reliable and precise diagnostic information.
OneTracker: Unifying Visual Object Tracking with Foundation Models and Efficient Tuning
Mar 14, 2024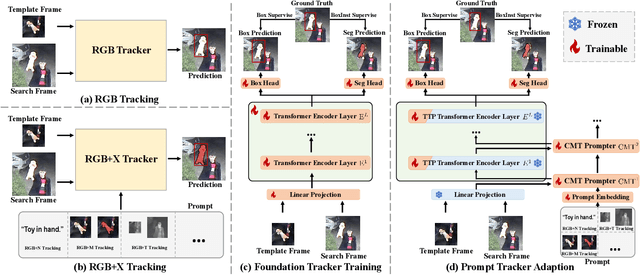
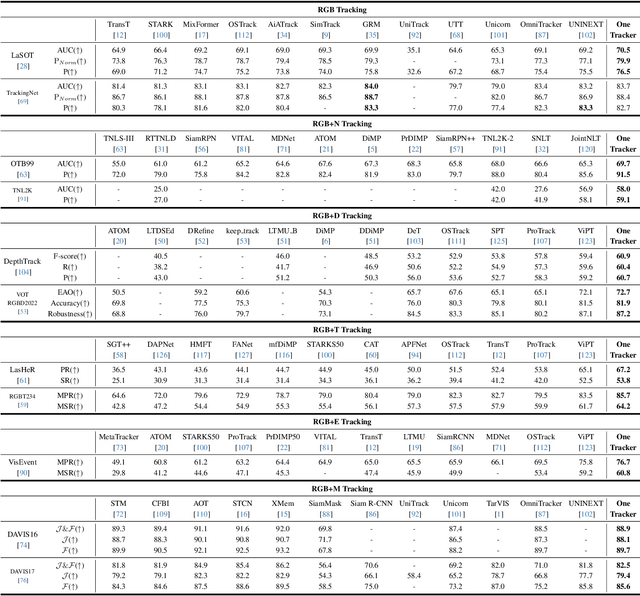
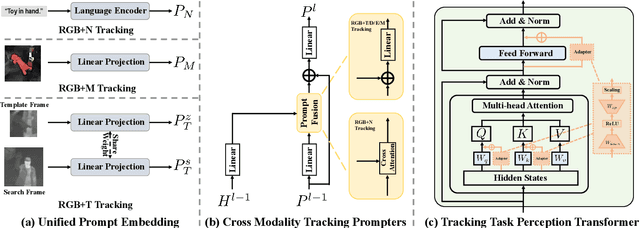

Visual object tracking aims to localize the target object of each frame based on its initial appearance in the first frame. Depending on the input modility, tracking tasks can be divided into RGB tracking and RGB+X (e.g. RGB+N, and RGB+D) tracking. Despite the different input modalities, the core aspect of tracking is the temporal matching. Based on this common ground, we present a general framework to unify various tracking tasks, termed as OneTracker. OneTracker first performs a large-scale pre-training on a RGB tracker called Foundation Tracker. This pretraining phase equips the Foundation Tracker with a stable ability to estimate the location of the target object. Then we regard other modality information as prompt and build Prompt Tracker upon Foundation Tracker. Through freezing the Foundation Tracker and only adjusting some additional trainable parameters, Prompt Tracker inhibits the strong localization ability from Foundation Tracker and achieves parameter-efficient finetuning on downstream RGB+X tracking tasks. To evaluate the effectiveness of our general framework OneTracker, which is consisted of Foundation Tracker and Prompt Tracker, we conduct extensive experiments on 6 popular tracking tasks across 11 benchmarks and our OneTracker outperforms other models and achieves state-of-the-art performance.
Going Beyond Neural Network Feature Similarity: The Network Feature Complexity and Its Interpretation Using Category Theory
Oct 10, 2023The behavior of neural networks still remains opaque, and a recently widely noted phenomenon is that networks often achieve similar performance when initialized with different random parameters. This phenomenon has attracted significant attention in measuring the similarity between features learned by distinct networks. However, feature similarity could be vague in describing the same feature since equivalent features hardly exist. In this paper, we expand the concept of equivalent feature and provide the definition of what we call functionally equivalent features. These features produce equivalent output under certain transformations. Using this definition, we aim to derive a more intrinsic metric for the so-called feature complexity regarding the redundancy of features learned by a neural network at each layer. We offer a formal interpretation of our approach through the lens of category theory, a well-developed area in mathematics. To quantify the feature complexity, we further propose an efficient algorithm named Iterative Feature Merging. Our experimental results validate our ideas and theories from various perspectives. We empirically demonstrate that the functionally equivalence widely exists among different features learned by the same neural network and we could reduce the number of parameters of the network without affecting the performance.The IFM shows great potential as a data-agnostic model prune method. We have also drawn several interesting empirical findings regarding the defined feature complexity.
Differentiable Robot Neural Distance Function for Adaptive Grasp Synthesis on a Unified Robotic Arm-Hand System
Sep 28, 2023Grasping is a fundamental skill for robots to interact with their environment. While grasp execution requires coordinated movement of the hand and arm to achieve a collision-free and secure grip, many grasp synthesis studies address arm and hand motion planning independently, leading to potentially unreachable grasps in practical settings. The challenge of determining integrated arm-hand configurations arises from its computational complexity and high-dimensional nature. We address this challenge by presenting a novel differentiable robot neural distance function. Our approach excels in capturing intricate geometry across various joint configurations while preserving differentiability. This innovative representation proves instrumental in efficiently addressing downstream tasks with stringent contact constraints. Leveraging this, we introduce an adaptive grasp synthesis framework that exploits the full potential of the unified arm-hand system for diverse grasping tasks. Our neural joint space distance function achieves an 84.7% error reduction compared to baseline methods. We validated our approaches on a unified robotic arm-hand system that consists of a 7-DoF robot arm and a 16-DoF multi-fingered robotic hand. Results demonstrate that our approach empowers this high-DoF system to generate and execute various arm-hand grasp configurations that adapt to the size of the target objects while ensuring whole-body movements to be collision-free.
Sliding Touch-based Exploration for Modeling Unknown Object Shape with Multi-fingered Hands
Aug 01, 2023



Efficient and accurate 3D object shape reconstruction contributes significantly to the success of a robot's physical interaction with its environment. Acquiring accurate shape information about unknown objects is challenging, especially in unstructured environments, e.g. the vision sensors may only be able to provide a partial view. To address this issue, tactile sensors could be employed to extract local surface information for more robust unknown object shape estimation. In this paper, we propose a novel approach for efficient unknown 3D object shape exploration and reconstruction using a multi-fingered hand equipped with tactile sensors and a depth camera only providing a partial view. We present a multi-finger sliding touch strategy for efficient shape exploration using a Bayesian Optimization approach and a single-leader-multi-follower strategy for multi-finger smooth local surface perception. We evaluate our proposed method by estimating the 3D shape of objects from the YCB and OCRTOC datasets based on simulation and real robot experiments. The proposed approach yields successful reconstruction results relying on only a few continuous sliding touches. Experimental results demonstrate that our method is able to model unknown objects in an efficient and accurate way.
Energy-based Out-of-Distribution Detection for Graph Neural Networks
Feb 06, 2023Learning on graphs, where instance nodes are inter-connected, has become one of the central problems for deep learning, as relational structures are pervasive and induce data inter-dependence which hinders trivial adaptation of existing approaches that assume inputs to be i.i.d.~sampled. However, current models mostly focus on improving testing performance of in-distribution data and largely ignore the potential risk w.r.t. out-of-distribution (OOD) testing samples that may cause negative outcome if the prediction is overconfident on them. In this paper, we investigate the under-explored problem, OOD detection on graph-structured data, and identify a provably effective OOD discriminator based on an energy function directly extracted from graph neural networks trained with standard classification loss. This paves a way for a simple, powerful and efficient OOD detection model for GNN-based learning on graphs, which we call GNNSafe. It also has nice theoretical properties that guarantee an overall distinguishable margin between the detection scores for in-distribution and OOD samples, which, more critically, can be further strengthened by a learning-free energy belief propagation scheme. For comprehensive evaluation, we introduce new benchmark settings that evaluate the model for detecting OOD data from both synthetic and real distribution shifts (cross-domain graph shifts and temporal graph shifts). The results show that GNNSafe achieves up to $17.0\%$ AUROC improvement over state-of-the-arts and it could serve as simple yet strong baselines in such an under-developed area.