 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiDreams: An Open-Source Library for Robust Object Manipulation via Uncertainty-aware Task-specific Intuitive Physics
Mar 18, 2026Dynamics models, whether simulators or learned world models, have long been central to robotic manipulation, but most focus on minimizing prediction error rather than confronting a more fundamental challenge: real-world manipulation is inherently uncertain. We argue that robust manipulation under uncertainty is fundamentally an integration problem: uncertainties must be represented, propagated, and constrained within the planning loop, not merely suppressed during training. We present and open-source ManiDreams, a modular framework for uncertainty-aware manipulation planning over intuitive physics models. It realizes this integration through composable abstractions for distributional state representation, backend-agnostic dynamics prediction, and declarative constraint specification for action optimization. The framework explicitly addresses three sources of uncertainty: perceptual, parametric, and structural. It wraps any base policy with a sample-predict-constrain loop that evaluates candidate actions against distributional outcomes, adding robustness without retraining. Experiments on ManiSkill tasks show that ManiDreams maintains robust performance under various perturbations where the RL baseline degrades significantly. Runnable examples on pushing, picking, catching, and real-world deployment demonstrate flexibility across different policies, optimizers, physics backends, and executors. The framework is publicly available at https://github.com/Rice-RobotPI-Lab/ManiDreams
B4P: Simultaneous Grasp and Motion Planning for Object Placement via Parallelized Bidirectional Forests and Path Repair
Apr 06, 2025Robot pick and place systems have traditionally decoupled grasp, placement, and motion planning to build sequential optimization pipelines with the assumption that the individual components will be able to work together. However, this separation introduces sub-optimality, as grasp choices may limit or even prohibit feasible motions for a robot to reach the target placement pose, particularly in cluttered environments with narrow passages. To this end, we propose a forest-based planning framework to simultaneously find grasp configurations and feasible robot motions that explicitly satisfy downstream placement configurations paired with the selected grasps. Our proposed framework leverages a bidirectional sampling-based approach to build a start forest, rooted at the feasible grasp regions, and a goal forest, rooted at the feasible placement regions, to facilitate the search through randomly explored motions that connect valid pairs of grasp and placement trees. We demonstrate that the framework's inherent parallelism enables superlinear speedup, making it scalable for applications for redundant robot arms (e.g., 7 Degrees of Freedom) to work efficiently in highly cluttered environments. Extensive experiments in simulation demonstrate the robustness and efficiency of the proposed framework in comparison with multiple baselines under diverse scenarios.
Collision-inclusive Manipulation Planning for Occluded Object Grasping via Compliant Robot Motions
Dec 09, 2024



Traditional robotic manipulation mostly focuses on collision-free tasks. In practice, however, many manipulation tasks (e.g., occluded object grasping) require the robot to intentionally collide with the environment to reach a desired task configuration. By enabling compliant robot motions, collisions between the robot and the environment are allowed and can thus be exploited, but more physical uncertainties are introduced. To address collision-rich problems such as occluded object grasping while handling the involved uncertainties, we propose a collision-inclusive planning framework that can transition the robot to a desired task configuration via roughly modeled collisions absorbed by Cartesian impedance control. By strategically exploiting the environmental constraints and exploring inside a manipulation funnel formed by task repetitions, our framework can effectively reduce physical and perception uncertainties. With real-world evaluations on both single-arm and dual-arm setups, we show that our framework is able to efficiently address various realistic occluded grasping problems where a feasible grasp does not initially exist.
Caging in Time: A Framework for Robust Object Manipulation under Uncertainties and Limited Robot Perception
Oct 21, 2024
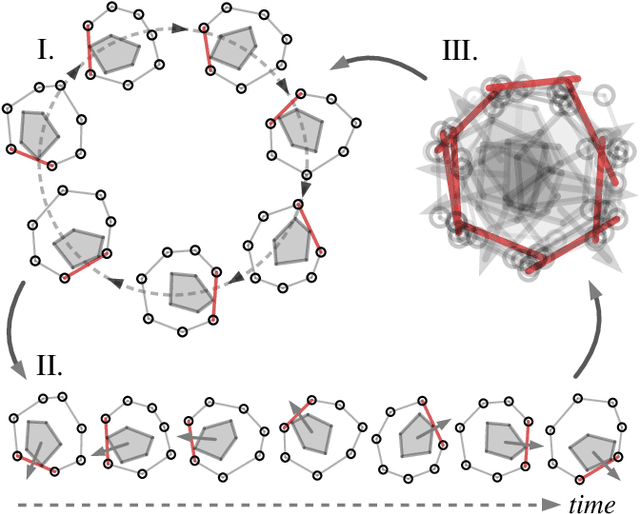
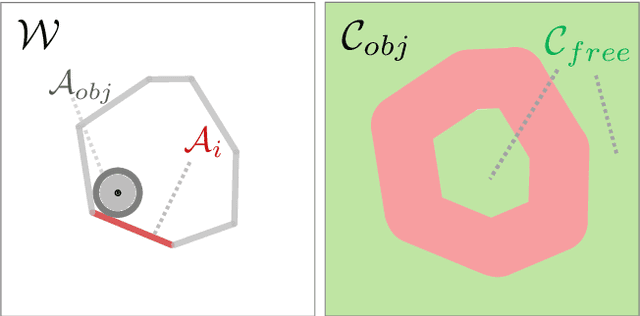

Real-world object manipulation has been commonly challenged by physical uncertainties and perception limitations. Being an effective strategy, while caging configuration-based manipulation frameworks have successfully provided robust solutions, they are not broadly applicable due to their strict requirements on the availability of multiple robots, widely distributed contacts, or specific geometries of the robots or the objects. To this end, this work proposes a novel concept, termed Caging in Time, to allow caging configurations to be formed even if there is just one robot engaged in a task. This novel concept can be explained by an insight that even if a caging configuration is needed to constrain the motion of an object, only a small portion of the cage is actively manipulating at a time. As such, we can switch the configuration of the robot strategically so that by collapsing its configuration in time, we will see a cage formed and its necessary portion active whenever needed. We instantiate our Caging in Time theory on challenging quasistatic and dynamic manipulation tasks, showing that Caging in Time can be achieved in general state spaces including geometry-based and energy-based spaces. With extensive experiments, we show robust and accurate manipulation, in an open-loop manner, without requiring detailed knowledge of the object geometry or physical properties, nor realtime accurate feedback on the manipulation states. In addition to being an effective and robust open-loop manipulation solution, the proposed theory can be a supplementary strategy to other manipulation systems affected by uncertain or limited robot perception.
UNO Push: Unified Nonprehensile Object Pushing via Non-Parametric Estimation and Model Predictive Control
Mar 20, 2024Nonprehensile manipulation through precise pushing is an essential skill that has been commonly challenged by perception and physical uncertainties, such as those associated with contacts, object geometries, and physical properties. For this, we propose a unified framework that jointly addresses system modeling, action generation, and control. While most existing approaches either heavily rely on a priori system information for analytic modeling, or leverage a large dataset to learn dynamic models, our framework approximates a system transition function via non-parametric learning only using a small number of exploratory actions (ca. 10). The approximated function is then integrated with model predictive control to provide precise pushing manipulation. Furthermore, we show that the approximated system transition functions can be robustly transferred across novel objects while being online updated to continuously improve the manipulation accuracy. Through extensive experiments on a real robot platform with a set of novel objects and comparing against a state-of-the-art baseline, we show that the proposed unified framework is a light-weight and highly effective approach to enable precise pushing manipulation all by itself. Our evaluation results illustrate that the system can robustly ensure millimeter-level precision and can straightforwardly work on any novel object.
Interactive Robot-Environment Self-Calibration via Compliant Exploratory Actions
Mar 19, 2024



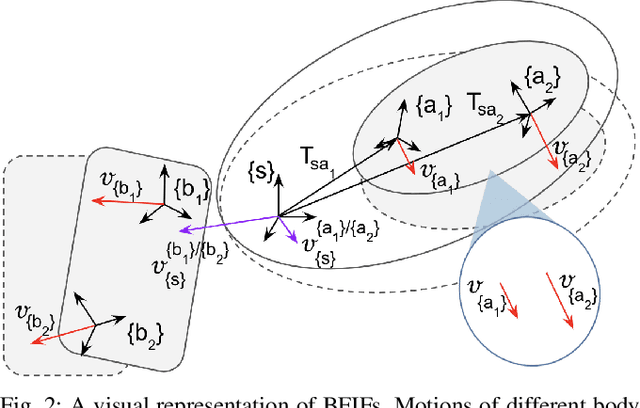
Calibrating robots into their workspaces is crucial for manipulation tasks. Existing calibration techniques often rely on sensors external to the robot (cameras, laser scanners, etc.) or specialized tools. This reliance complicates the calibration process and increases the costs and time requirements. Furthermore, the associated setup and measurement procedures require significant human intervention, which makes them more challenging to operate. Using the built-in force-torque sensors, which are nowadays a default component in collaborative robots, this work proposes a self-calibration framework where robot-environmental spatial relations are automatically estimated through compliant exploratory actions by the robot itself. The self-calibration approach converges, verifies its own accuracy, and terminates upon completion, autonomously purely through interactive exploration of the environment's geometries. Extensive experiments validate the effectiveness of our self-calibration approach in accurately establishing the robot-environment spatial relationships without the need for additional sensing equipment or any human intervention.
RISeg: Robot Interactive Object Segmentation via Body Frame-Invariant Features
Mar 04, 2024
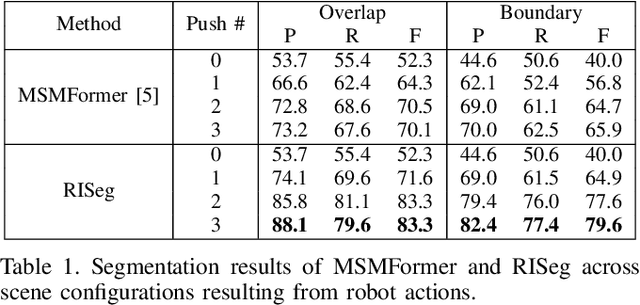
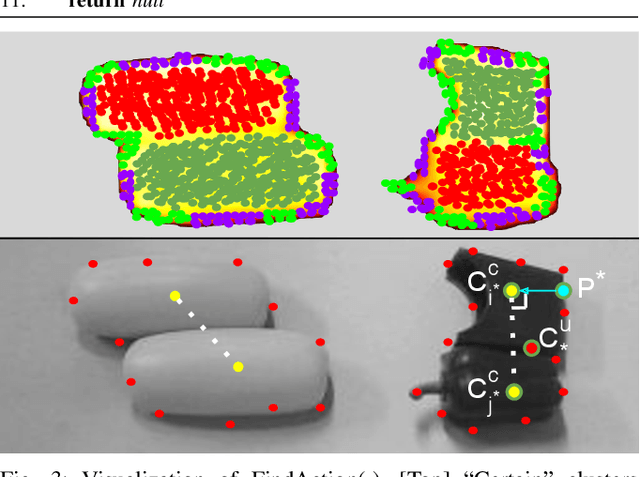
In order to successfully perform manipulation tasks in new environments, such as grasping, robots must be proficient in segmenting unseen objects from the background and/or other objects. Previous works perform unseen object instance segmentation (UOIS) by training deep neural networks on large-scale data to learn RGB/RGB-D feature embeddings, where cluttered environments often result in inaccurate segmentations. We build upon these methods and introduce a novel approach to correct inaccurate segmentation, such as under-segmentation, of static image-based UOIS masks by using robot interaction and a designed body frame-invariant feature. We demonstrate that the relative linear and rotational velocities of frames randomly attached to rigid bodies due to robot interactions can be used to identify objects and accumulate corrected object-level segmentation masks. By introducing motion to regions of segmentation uncertainty, we are able to drastically improve segmentation accuracy in an uncertainty-driven manner with minimal, non-disruptive interactions (ca. 2-3 per scene). We demonstrate the effectiveness of our proposed interactive perception pipeline in accurately segmenting cluttered scenes by achieving an average object segmentation accuracy rate of 80.7%, an increase of 28.2% when compared with other state-of-the-art UOIS methods.
Non-Parametric Self-Identification and Model Predictive Control of Dexterous In-Hand Manipulation
Jul 14, 2023



Building hand-object models for dexterous in-hand manipulation remains a crucial and open problem. Major challenges include the difficulty of obtaining the geometric and dynamical models of the hand, object, and time-varying contacts, as well as the inevitable physical and perception uncertainties. Instead of building accurate models to map between the actuation inputs and the object motions, this work proposes to enable the hand-object systems to continuously approximate their local models via a self-identification process where an underlying manipulation model is estimated through a small number of exploratory actions and non-parametric learning. With a very small number of data points, as opposed to most data-driven methods, our system self-identifies the underlying manipulation models online through exploratory actions and non-parametric learning. By integrating the self-identified hand-object model into a model predictive control framework, the proposed system closes the control loop to provide high accuracy in-hand manipulation. Furthermore, the proposed self-identification is able to adaptively trigger online updates through additional exploratory actions, as soon as the self-identified local models render large discrepancies against the observed manipulation outcomes. We implemented the proposed approach on a sensorless underactuated Yale Model O hand with a single external camera to observe the object's motion. With extensive experiments, we show that the proposed self-identification approach can enable accurate and robust dexterous manipulation without requiring an accurate system model nor a large amount of data for offline training.
Kinodynamic Rapidly-exploring Random Forest for Rearrangement-Based Nonprehensile Manipulation
Feb 08, 2023



Rearrangement-based nonprehensile manipulation still remains as a challenging problem due to the high-dimensional problem space and the complex physical uncertainties it entails. We formulate this class of problems as a coupled problem of local rearrangement and global action optimization by incorporating free-space transit motions between constrained rearranging actions. We propose a forest-based kinodynamic planning framework to concurrently search in multiple problem regions, so as to enable global exploration of the most task-relevant subspaces, while facilitating effective switches between local rearranging actions. By interleaving dynamic horizon planning and action execution, our framework can adaptively handle real-world uncertainties. With extensive experiments, we show that our framework significantly improves the planning efficiency and manipulation effectiveness while being robust against various uncertainties.
Rearrangement-Based Manipulation via Kinodynamic Planning and Dynamic Planning Horizons
Aug 03, 2022
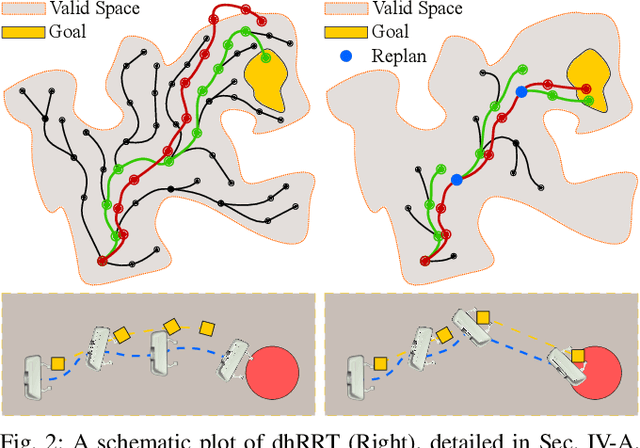

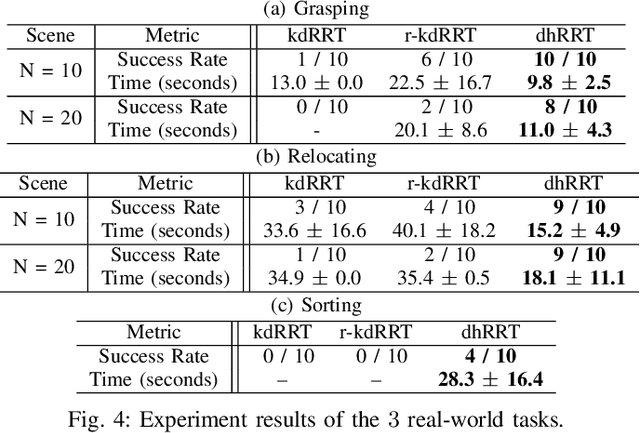
Robot manipulation in cluttered environments often requires complex and sequential rearrangement of multiple objects in order to achieve the desired reconfiguration of the target objects. Due to the sophisticated physical interactions involved in such scenarios, rearrangement-based manipulation is still limited to a small range of tasks and is especially vulnerable to physical uncertainties and perception noise. This paper presents a planning framework that leverages the efficiency of sampling-based planning approaches, and closes the manipulation loop by dynamically controlling the planning horizon. Our approach interleaves planning and execution to progressively approach the manipulation goal while correcting any errors or path deviations along the process. Meanwhile, our framework allows the definition of manipulation goals without requiring explicit goal configurations, enabling the robot to flexibly interact with all objects to facilitate the manipulation of the target ones. With extensive experiments both in simulation and on a real robot, we evaluate our framework on three manipulation tasks in cluttered environments: grasping, relocating, and sorting. In comparison with two baseline approaches, we show that our framework can significantly improve planning efficiency, robustness against physical uncertainties, and task success rate under limited time budgets.