 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Local Matches to Global Masks: Novel Instance Detection in Open-World Scenes
Mar 03, 2026Detecting and segmenting novel object instances in open-world environments is a fundamental problem in robotic perception. Given only a small set of template images, a robot must locate and segment a specific object instance in a cluttered, previously unseen scene. Existing proposal-based approaches are highly sensitive to proposal quality and often fail under occlusion and background clutter. We propose L2G-Det, a local-to-global instance detection framework that bypasses explicit object proposals by leveraging dense patch-level matching between templates and the query image. Locally matched patches generate candidate points, which are refined through a candidate selection module to suppress false positives. The filtered points are then used to prompt an augmented Segment Anything Model (SAM) with instance-specific object tokens, enabling reliable reconstruction of complete instance masks. Experiments demonstrate improved performance over proposal-based methods in challenging open-world settings.
Adapting Pre-Trained Vision Models for Novel Instance Detection and Segmentation
May 28, 2024



Novel Instance Detection and Segmentation (NIDS) aims at detecting and segmenting novel object instances given a few examples of each instance. We propose a unified framework (NIDS-Net) comprising object proposal generation, embedding creation for both instance templates and proposal regions, and embedding matching for instance label assignment. Leveraging recent advancements in large vision methods, we utilize the Grounding DINO and Segment Anything Model (SAM) to obtain object proposals with accurate bounding boxes and masks. Central to our approach is the generation of high-quality instance embeddings. We utilize foreground feature averages of patch embeddings from the DINOv2 ViT backbone, followed by refinement through a weight adapter mechanism that we introduce. We show experimentally that our weight adapter can adjust the embeddings locally within their feature space and effectively limit overfitting. This methodology enables a straightforward matching strategy, resulting in significant performance gains. Our framework surpasses current state-of-the-art methods, demonstrating notable improvements of 22.3, 46.2, 10.3, and 24.0 in average precision (AP) across four detection datasets. In instance segmentation tasks on seven core datasets of the BOP challenge, our method outperforms the top RGB methods by 3.6 AP and remains competitive with the best RGB-D method. Code is available at: https://github.com/YoungSean/NIDS-Net
RISeg: Robot Interactive Object Segmentation via Body Frame-Invariant Features
Mar 04, 2024
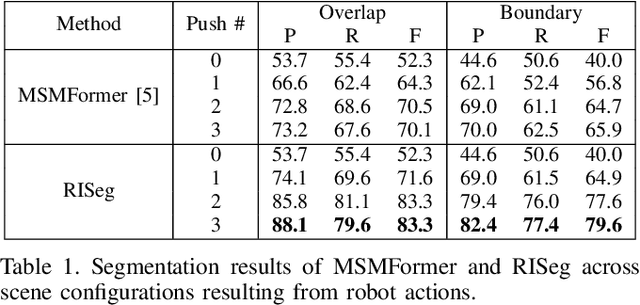
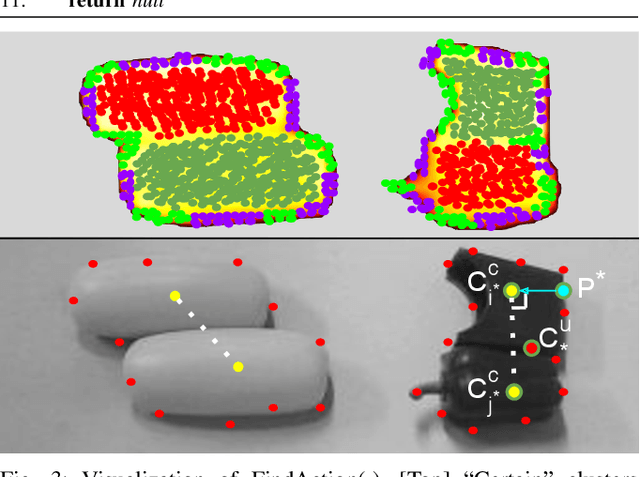
In order to successfully perform manipulation tasks in new environments, such as grasping, robots must be proficient in segmenting unseen objects from the background and/or other objects. Previous works perform unseen object instance segmentation (UOIS) by training deep neural networks on large-scale data to learn RGB/RGB-D feature embeddings, where cluttered environments often result in inaccurate segmentations. We build upon these methods and introduce a novel approach to correct inaccurate segmentation, such as under-segmentation, of static image-based UOIS masks by using robot interaction and a designed body frame-invariant feature. We demonstrate that the relative linear and rotational velocities of frames randomly attached to rigid bodies due to robot interactions can be used to identify objects and accumulate corrected object-level segmentation masks. By introducing motion to regions of segmentation uncertainty, we are able to drastically improve segmentation accuracy in an uncertainty-driven manner with minimal, non-disruptive interactions (ca. 2-3 per scene). We demonstrate the effectiveness of our proposed interactive perception pipeline in accurately segmenting cluttered scenes by achieving an average object segmentation accuracy rate of 80.7%, an increase of 28.2% when compared with other state-of-the-art UOIS methods.
SCENEREPLICA: Benchmarking Real-World Robot Manipulation by Creating Reproducible Scenes
Jun 27, 2023
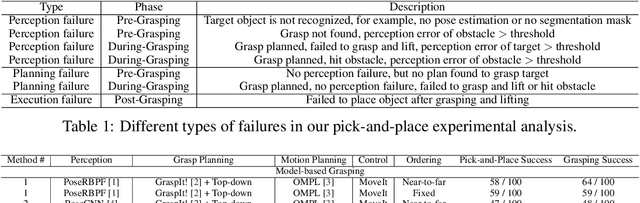
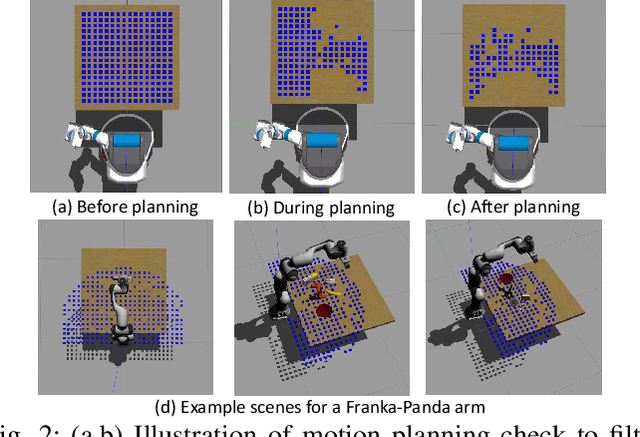
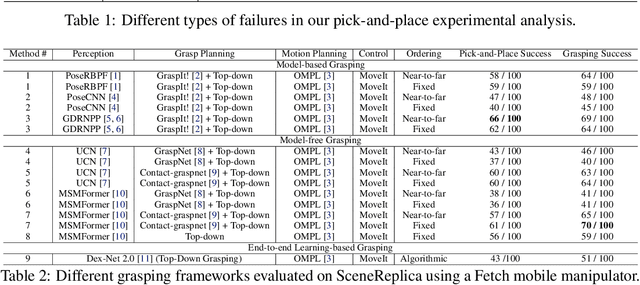
We present a new reproducible benchmark for evaluating robot manipulation in the real world, specifically focusing on pick-and-place. Our benchmark uses the YCB objects, a commonly used dataset in the robotics community, to ensure that our results are comparable to other studies. Additionally, the benchmark is designed to be easily reproducible in the real world, making it accessible to researchers and practitioners. We also provide our experimental results and analyzes for model-based and model-free 6D robotic grasping on the benchmark, where representative algorithms are evaluated for object perception, grasping planning, and motion planning. We believe that our benchmark will be a valuable tool for advancing the field of robot manipulation. By providing a standardized evaluation framework, researchers can more easily compare different techniques and algorithms, leading to faster progress in developing robot manipulation methods.
Self-Supervised Unseen Object Instance Segmentation via Long-Term Robot Interaction
Feb 07, 2023



We introduce a novel robotic system for improving unseen object instance segmentation in the real world by leveraging long-term robot interaction with objects. Previous approaches either grasp or push an object and then obtain the segmentation mask of the grasped or pushed object after one action. Instead, our system defers the decision on segmenting objects after a sequence of robot pushing actions. By applying multi-object tracking and video object segmentation on the images collected via robot pushing, our system can generate segmentation masks of all the objects in these images in a self-supervised way. These include images where objects are very close to each other, and segmentation errors usually occur on these images for existing object segmentation networks. We demonstrate the usefulness of our system by fine-tuning segmentation networks trained on synthetic data with real-world data collected by our system. We show that, after fine-tuning, the segmentation accuracy of the networks is significantly improved both in the same domain and across different domains. In addition, we verify that the fine-tuned networks improve top-down robotic grasping of unseen objects in the real world.
Mean Shift Mask Transformer for Unseen Object Instance Segmentation
Nov 21, 2022
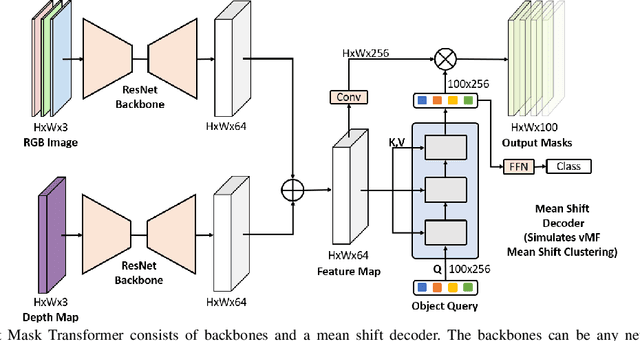
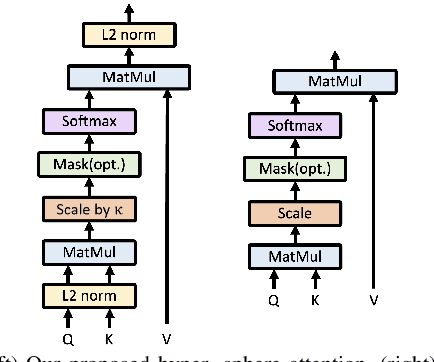
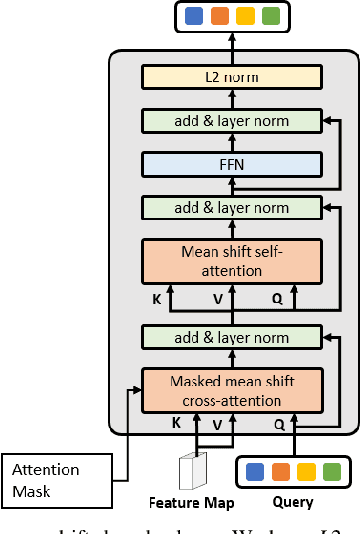
Segmenting unseen objects is a critical task in many different domains. For example, a robot may need to grasp an unseen object, which means it needs to visually separate this object from the background and/or other objects. Mean shift clustering is a common method in object segmentation tasks. However, the traditional mean shift clustering algorithm is not easily integrated into an end-to-end neural network training pipeline. In this work, we propose the Mean Shift Mask Transformer (MSMFormer), a new transformer architecture that simulates the von Mises-Fisher (vMF) mean shift clustering algorithm, allowing for the joint training and inference of both the feature extractor and the clustering. Its central component is a hypersphere attention mechanism, which updates object queries on a hypersphere. To illustrate the effectiveness of our method, we apply MSMFormer to Unseen Object Instance Segmentation, which yields a new state-of-the-art of 87.3 Boundary F-meansure on the real-world Object Clutter Indoor Dataset (OCID). Code is available at https://github.com/YoungSean/UnseenObjectsWithMeanShift