 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Pre-Trained Vision Models for Novel Instance Detection and Segmentation
May 28, 2024



Novel Instance Detection and Segmentation (NIDS) aims at detecting and segmenting novel object instances given a few examples of each instance. We propose a unified framework (NIDS-Net) comprising object proposal generation, embedding creation for both instance templates and proposal regions, and embedding matching for instance label assignment. Leveraging recent advancements in large vision methods, we utilize the Grounding DINO and Segment Anything Model (SAM) to obtain object proposals with accurate bounding boxes and masks. Central to our approach is the generation of high-quality instance embeddings. We utilize foreground feature averages of patch embeddings from the DINOv2 ViT backbone, followed by refinement through a weight adapter mechanism that we introduce. We show experimentally that our weight adapter can adjust the embeddings locally within their feature space and effectively limit overfitting. This methodology enables a straightforward matching strategy, resulting in significant performance gains. Our framework surpasses current state-of-the-art methods, demonstrating notable improvements of 22.3, 46.2, 10.3, and 24.0 in average precision (AP) across four detection datasets. In instance segmentation tasks on seven core datasets of the BOP challenge, our method outperforms the top RGB methods by 3.6 AP and remains competitive with the best RGB-D method. Code is available at: https://github.com/YoungSean/NIDS-Net
Proto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
Jul 08, 2023



We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by the unimodal prototypical networks for few-shot learning, we introduce PROTO-CLIP that utilizes image prototypes and text prototypes for few-shot learning. Specifically, PROTO-CLIP adapts the image encoder and text encoder in CLIP in a joint fashion using few-shot examples. The two encoders are used to compute prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of corresponding classes. Such a proposed alignment is beneficial for few-shot classification due to the contributions from both types of prototypes. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning as well as in the real world for robot perception.
SCENEREPLICA: Benchmarking Real-World Robot Manipulation by Creating Reproducible Scenes
Jun 27, 2023
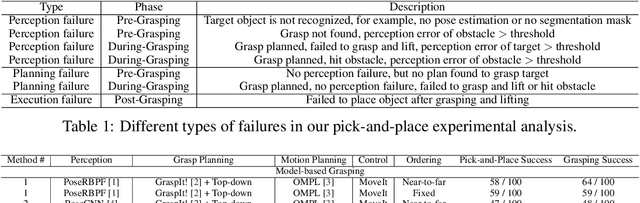
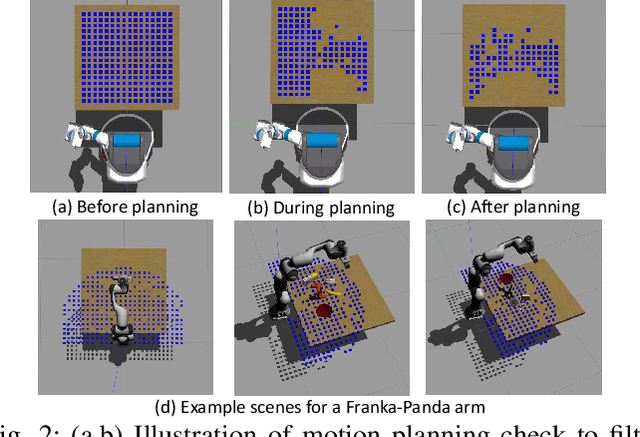
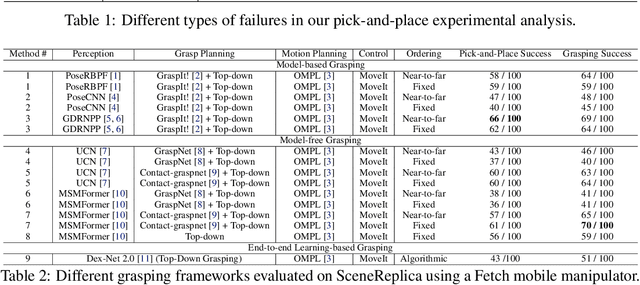
We present a new reproducible benchmark for evaluating robot manipulation in the real world, specifically focusing on pick-and-place. Our benchmark uses the YCB objects, a commonly used dataset in the robotics community, to ensure that our results are comparable to other studies. Additionally, the benchmark is designed to be easily reproducible in the real world, making it accessible to researchers and practitioners. We also provide our experimental results and analyzes for model-based and model-free 6D robotic grasping on the benchmark, where representative algorithms are evaluated for object perception, grasping planning, and motion planning. We believe that our benchmark will be a valuable tool for advancing the field of robot manipulation. By providing a standardized evaluation framework, researchers can more easily compare different techniques and algorithms, leading to faster progress in developing robot manipulation methods.
FewSOL: A Dataset for Few-Shot Object Learning in Robotic Environments
Jul 06, 2022


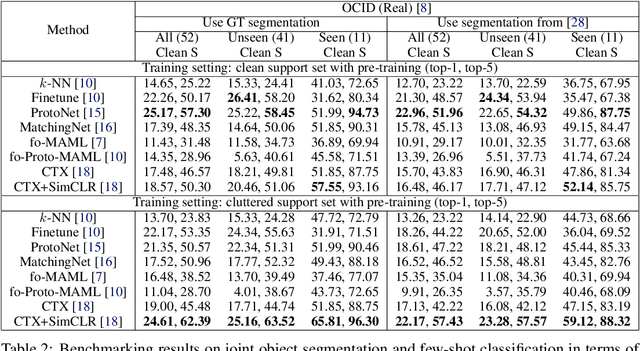
We introduce the Few-Shot Object Learning (FewSOL) dataset for object recognition with a few images per object. We captured 336 real-world objects with 9 RGB-D images per object from different views. Object segmentation masks, object poses and object attributes are provided. In addition, synthetic images generated using 330 3D object models are used to augment the dataset. We investigated (i) few-shot object classification and (ii) joint object segmentation and few-shot classification with the state-of-the-art methods for few-shot learning and meta-learning using our dataset. The evaluation results show that there is still a large margin to be improved for few-shot object classification in robotic environments. Our dataset can be used to study a set of few-shot object recognition problems such as classification, detection and segmentation, shape reconstruction, pose estimation, keypoint correspondences and attribute recognition. The dataset and code are available at https://irvlutd.github.io/FewSOL.