 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
Jul 08, 2023



We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by the unimodal prototypical networks for few-shot learning, we introduce PROTO-CLIP that utilizes image prototypes and text prototypes for few-shot learning. Specifically, PROTO-CLIP adapts the image encoder and text encoder in CLIP in a joint fashion using few-shot examples. The two encoders are used to compute prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of corresponding classes. Such a proposed alignment is beneficial for few-shot classification due to the contributions from both types of prototypes. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning as well as in the real world for robot perception.
Self-Supervised Unseen Object Instance Segmentation via Long-Term Robot Interaction
Feb 07, 2023



We introduce a novel robotic system for improving unseen object instance segmentation in the real world by leveraging long-term robot interaction with objects. Previous approaches either grasp or push an object and then obtain the segmentation mask of the grasped or pushed object after one action. Instead, our system defers the decision on segmenting objects after a sequence of robot pushing actions. By applying multi-object tracking and video object segmentation on the images collected via robot pushing, our system can generate segmentation masks of all the objects in these images in a self-supervised way. These include images where objects are very close to each other, and segmentation errors usually occur on these images for existing object segmentation networks. We demonstrate the usefulness of our system by fine-tuning segmentation networks trained on synthetic data with real-world data collected by our system. We show that, after fine-tuning, the segmentation accuracy of the networks is significantly improved both in the same domain and across different domains. In addition, we verify that the fine-tuned networks improve top-down robotic grasping of unseen objects in the real world.
SplitEasy: A Practical Approach for Training ML models on Mobile Devices in a split second
Nov 09, 2020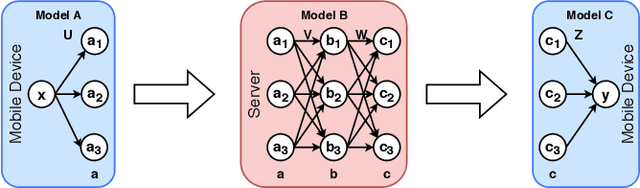
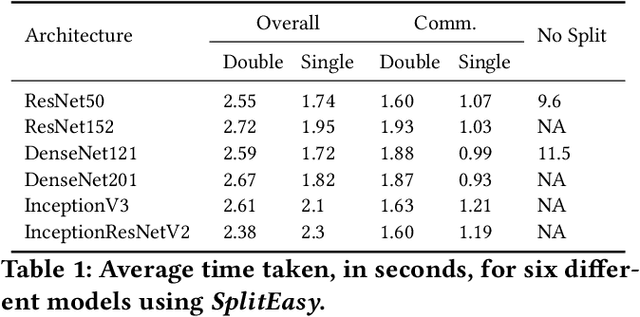
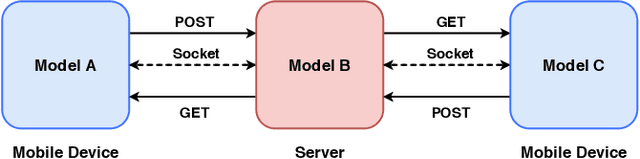
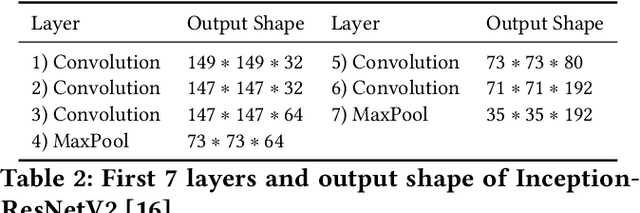
Modern mobile devices, although resourceful, cannot train state-of-the-art machine learning models without the assistance of servers, which require access to privacy-sensitive user data. Split learning has recently emerged as a promising technique for training complex deep learning (DL) models on low-powered mobile devices. The core idea behind this technique is to train the sensitive layers of a DL model on the mobile devices while offloading the computationally intensive layers to a server. Although a lot of works have already explored the effectiveness of split learning in simulated settings, a usable toolkit for this purpose does not exist. In this work, we propose SplitEasy, a framework for training ML models on mobile devices using split learning. Using the abstraction provided by SplitEasy, developers can run various DL models under split learning setting by making minimal modifications. We provide a detailed explanation of SplitEasy and perform experiments under varying networks to demonstrate its versatility. We demonstrate how SplitEasy can be used to train state-of-the-art models while incurring nearly constant computational cost on mobile devices.
Rethinking CNN Models for Audio Classification
Jul 22, 2020



In this paper, we show that ImageNet-Pretrained standard deep CNN models can be used as strong baseline networks for audio classification. Even though there is a significant difference between audio Spectrogram and standard ImageNet image samples, transfer learning assumptions still hold firmly. To understand what enables the ImageNet pretrained models to learn useful audio representations, we systematically study how much of pretrained weights is useful for learning spectrograms. We show (1) that for a given standard model using pretrained weights is better than using randomly initialized weights (2) qualitative results of what the CNNs learn from the spectrograms by visualizing the gradients. Besides, we show that even though we use the pretrained model weights for initialization, there is variance in performance in various output runs of the same model. This variance in performance is due to the random initialization of linear classification layer and random mini-batch orderings in multiple runs. This brings significant diversity to build stronger ensemble models with an overall improvement in accuracy. An ensemble of ImageNet pretrained DenseNet achieves 92.89% validation accuracy on the ESC-50 dataset and 87.42% validation accuracy on the UrbanSound8K dataset which is the current state-of-the-art on both of these datasets.